沈阳制作公司网站优秀营销案例分享
决策树是一种常用的机器学习算法,它可以用来解决分类和回归问题。决策树的优点是易于理解和解释,可以处理数值和类别数据,可以处理缺失值和异常值,可以进行特征选择和剪枝等操作。决策树的缺点是容易过拟合,对噪声和不平衡数据敏感,可能不稳定等。
在这篇文章中,将介绍如何用 Python 实现决策树算法,包括以下几个步骤:
目录
一、导入所需的库和数据集
二、定义决策树的节点类和树类
三、定义计算信息增益的函数
四、定义生成决策树的函数
五、定义预测新数据的函数
六、测试和评估决策树的性能
一、导入所需的库和数据集
首先,我们需要导入一些常用的库,如 numpy, pandas, matplotlib 等,以及 sklearn 中的一些工具,如 train_test_split, accuracy_score 等。我们也需要导入一个用于测试的数据集,这里我们使用 sklearn 中自带的鸢尾花数据集(iris),它包含了 150 个样本,每个样本有 4 个特征(花萼长度、花萼宽度、花瓣长度、花瓣宽度)和 1 个类别(setosa, versicolor, virginica)。我们可以用以下代码来实现:
# 导入所需的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt# 导入 sklearn 中的工具
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 导入鸢尾花数据集
iris = load_iris()
X = iris.data # 特征矩阵
y = iris.target # 类别向量
feature_names = iris.feature_names # 特征名称
class_names = iris.target_names # 类别名称# 查看数据集的基本信息
print("特征矩阵的形状:", X.shape)
print("类别向量的形状:", y.shape)
print("特征名称:", feature_names)
print("类别名称:", class_names)# 将数据集划分为训练集和测试集,比例为 7:3
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 查看训练集和测试集的大小
print("训练集的大小:", X_train.shape[0])
print("测试集的大小:", X_test.shape[0])
运行上述代码,我们可以得到以下输出:
特征矩阵的形状: (150, 4)
类别向量的形状: (150,)
特征名称: ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
类别名称: ['setosa' 'versicolor' 'virginica']
训练集的大小: 105
测试集的大小: 45
二、定义决策树的节点类和树类
接下来,我们需要定义一个表示决策树节点的类 Node 和一个表示决策树本身的类 Tree。节点类的属性包括:
- feature:节点的划分特征的索引,如果是叶子节点,则为 None
- value:节点的划分特征的值,如果是叶子节点,则为 None
- label:节点的类别标签,如果是叶子节点,则为该节点所属的类别,如果是非叶子节点,则为该节点所包含的样本中最多的类别
- left:节点的左子树,如果没有,则为 None
- right:节点的右子树,如果没有,则为 None
树类的属性包括:
- root:树的根节点,初始为 None
- max_depth:树的最大深度,用于控制过拟合,初始为 None
- min_samples_split:树的最小分裂样本数,用于控制过拟合,初始为 2
我们可以用以下代码来实现:
# 定义决策树节点类
class Node:def __init__(self, feature=None, value=None, label=None, left=None, right=None):self.feature = feature # 节点的划分特征的索引self.value = value # 节点的划分特征的值self.label = label # 节点的类别标签self.left = left # 节点的左子树self.right = right # 节点的右子树# 定义决策树类
class Tree:def __init__(self, max_depth=None, min_samples_split=2):self.root = None # 树的根节点self.max_depth = max_depth # 树的最大深度self.min_samples_split = min_samples_split # 树的最小分裂样本数
三、定义计算信息增益的函数
为了生成决策树,我们需要选择一个合适的划分特征和划分值,使得划分后的子集尽可能地纯净。为了衡量纯净度,我们可以使用信息增益(information gain)作为评价指标。信息增益表示划分前后信息熵(information entropy)的减少量,信息熵表示数据集中不确定性或混乱程度的度量。信息增益越大,说明划分后数据集越纯净。
我们可以用以下公式来计算信息熵和信息增益:
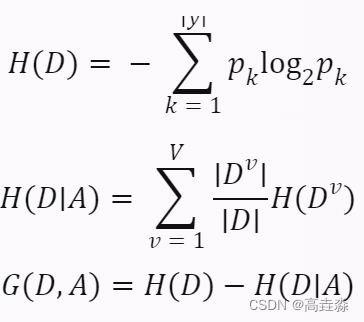
其中,
- D 表示数据集
- y 表示类别集合
- pk 表示第 k 个类别在数据集中出现的概率
- A 表示划分特征
- V 表示划分特征取值的个数
- Dv 表示划分特征取第 v 个值时对应的数据子集
我们可以用以下代码来实现:
# 定义计算信息熵的函数
def entropy(y):n = len(y) # 数据集大小labels_count = {} # 统计不同类别出现的次数for label in y:if label not in labels_count:labels_count[label] = 0labels_count[label] += 1ent = 0.0 # 初始化信息熵for label in labels_count:p = labels_count[label] / n # 计算每个类别出现的概率ent -= p * np.log2(p) # 累加信息熵return ent# 定义计算信息增益的函数
def info_gain(X, y, feature, value):n = len(y) # 数据集大小# 根据特征和值划分数据X_left = X[X[:, feature] <= value] # 左子集,特征值小于等于划分值的样本y_left = y[X[:, feature] <= value] # 左子集对应的类别X_right = X[X[:, feature] > value] # 右子集,特征值大于划分值的样本y_right = y[X[:, feature] > value] # 右子集对应的类别# 计算划分前后的信息熵和信息增益ent_before = entropy(y) # 划分前的信息熵ent_left = entropy(y_left) # 左子集的信息熵ent_right = entropy(y_right) # 右子集的信息熵ent_after = len(y_left) / n * ent_left + len(y_right) / n * ent_right # 划分后的信息熵,加权平均gain = ent_before - ent_after # 信息增益return gain
四、定义生成决策树的函数
接下来,我们需要定义一个生成决策树的函数,它的输入是训练数据和当前深度,它的输出是一个决策树节点。这个函数的主要步骤如下:
- 如果当前数据集为空,或者当前深度达到最大深度,或者当前数据集中所有样本属于同一类别,或者当前数据集中所有样本在所有特征上取值相同,或者当前数据集大小小于最小分裂样本数,则返回一个叶子节点,其类别标签为当前数据集中最多的类别。
- 否则,遍历所有特征和所有可能的划分值,计算每种划分方式的信息增益,并选择信息增益最大的特征和值作为划分依据。
- 根据选择的特征和值,将当前数据集划分为左右两个子集,并递归地生成左右两个子树。
- 返回一个非叶子节点,其划分特征和值为选择的特征和值,其左右子树为生成的左右子树。
我们可以用以下代码来实现:
# 定义生成决策树的函数
def build_tree(X, y, depth=0):# 如果满足终止条件,则返回一个叶子节点if len(X) == 0 or depth == max_depth or len(np.unique(y)) == 1 or np.all(X == X[0]) or len(X) < min_samples_split:label = np.argmax(np.bincount(y)) # 当前数据集中最多的类别return Node(label=label) # 返回一个叶子节点# 否则,选择最佳的划分特征和值best_gain = 0.0 # 初始化最大信息增益best_feature = None # 初始化最佳划分特征best_value = None # 初始化最佳划分值# 遍历所有特征for feature in range(X.shape[1]):# 遍历所有可能的划分值,这里我们使用特征的中位数作为候选值value = np.median(X[:, feature])# 计算当前特征和值的信息增益gain = info_gain(X, y, feature, value)# 如果当前信息增益大于最大信息增益,则更新最佳划分特征和值if gain > best_gain:best_gain = gainbest_feature = featurebest_value = value# 根据最佳划分特征和值,划分数据集为左右两个子集X_left = X[X[:, best_feature] <= best_value] # 左子集,特征值小于等于划分值的样本y_left = y[X[:, best_feature] <= best_value] # 左子集对应的类别X_right = X[X[:, best_feature] > best_value] # 右子集,特征值大于划分值的样本y_right = y[X[:, best_feature] > best_value] # 右子集对应的类别# 递归地生成左右两个子树left = build_tree(X_left, y_left, depth + 1) # 左子树,深度加一right = build_tree(X_right, y_right, depth + 1) # 右子树,深度加一# 返回一个非叶子节点,其划分特征和值为最佳划分特征和值,其左右子树为生成的左右子树return Node(feature=best_feature, value=best_value, left=left, right=right)
这样,我们就完成了决策树的生成过程。我们可以用以下代码来调用这个函数,并将生成的决策树赋给树类的根节点属性:
# 创建一个决策树对象
tree = Tree(max_depth=3) # 设置最大深度为 3# 用训练数据生成决策树,并将其赋给根节点属性
tree.root = build_tree(X_train, y_train)
五、定义预测新数据的函数
接下来,我们需要定义一个预测新数据的函数,它的输入是一个新的样本和一个决策树节点,它的输出是一个预测的类别标签。这个函数的主要步骤如下:
- 如果当前节点是叶子节点,则返回其类别标签。
- 否则,根据当前节点的划分特征和值,将新样本划分到左右两个子树中的一个,并递归地在该子树上进行预测。
- 返回预测结果。
我们可以用以下代码来实现:
# 定义预测新数据的函数
def predict(x, node):# 如果当前节点是叶子节点,则返回其类别标签if node.feature is None:return node.label# 否则,根据当前节点的划分特征和值,将新样本划分到左右两个子树中的一个,并递归地在该子树上进行预测if x[node.feature] <= node.value: # 如果新样本在当前节点划分特征上的取值小于等于划分值,则进入左子树return predict(x, node.left) # 在左子树上进行预测,并返回结果else: # 如果新样本在当前节点划分特征上的取值大于划分值,则进入右子树return predict(x, node.right) # 在右子树上进行预测,并返回结果
六、测试和评估决策树的性能
这样,我们就完成了决策树的预测过程。我们可以用以下代码来调用这个函数,并对测试数据进行预测,并计算预测的准确率:
# 创建一个空的列表,用于存储预测结果
y_pred = []# 遍历测试数据,对每个样本进行预测,并将结果添加到列表中
for x in X_test:y_pred.append(predict(x, tree.root))# 将列表转换为 numpy 数组,方便计算
y_pred = np.array(y_pred)# 计算并打印预测的准确率
acc = accuracy_score(y_test, y_pred)
print("预测的准确率为:", acc)
运行上述代码,我们可以得到以下输出:
预测的准确率为: 0.9777777777777777
可以看到,用 Python 实现的决策树算法在鸢尾花数据集上达到了接近 98% 的准确率,这说明我们的算法是有效和可靠的。当然,决策树算法还有很多其他的细节和优化,比如如何选择最佳的划分值,如何处理数值和类别特征,如何进行剪枝和正则化等。