做新网站的swot分析有哪些免费推广网站
图解注意力
Part #2: The Illustrated Self-Attention
在文章前面的部分,我们展示了这张图片来展示自注意力被应用于正在处理单词"it"的一层中:

在本节中,我们将看看这是如何完成的。请注意,我们将以一种试图理解单个单词发生什么的方式来看待它。这就是为什么我们将展示许多单独的向量。实际的实现是通过将巨大的矩阵相乘在一起来完成的。但我想专注于这里单词层面上发生的事情的直觉。
Self-Attention (without masking)
让我们首先看看在编码器模块中如何计算原始自注意力。让我们看看一个一次只能处理四个标记的玩具变压器模块。
自注意力通过三个主要步骤应用:
- 为每个路径创建查询(Query)、键(Key)和值(Value)向量。
- 对于每个输入标记,使用其查询向量与所有其他键向量进行评分。
- 在将它们乘以相关分数后,将值向量相加

1- Create Query, Key, and Value Vectors
让我们专注于第一条路径。我们将采用其查询,并与所有键进行比较。这为每个键产生了一个分数。自注意力的第一步是为每个标记路径计算三个向量(现在让我们暂时忽略注意力头):

2- Score
现在我们已经有了向量,我们只在步骤#2中使用查询和键向量。由于我们专注于第一个标记,我们将它的查询与所有其他键向量相乘,为这四个标记中的每一个都产生了一个分数。

3- Sum
现在我们可以将分数乘以值向量。得分高的值将在我们加总它们后构成结果向量的很大一部分。

分数越低,我们展示的值向量就越透明。这是为了表示乘以一个小数如何稀释向量的值。
如果我们对每条路径执行相同的操作,我们最终会得到一个向量,代表每个标记包含该标记的适当上下文。然后,这些向量被呈现给Transformer模块中的下一个子层(前馈神经网络):

The Illustrated Masked Self-Attention
现在我们已经查看了Transformer自注意力步骤的内部,让我们继续看看掩蔽自注意力。掩蔽自注意力与自注意力相同,只是在步骤#2时有所不同。假设模型只有两个标记作为输入,我们正在观察第二个标记。在这种情况下,最后两个标记被掩蔽了。因此,模型在打分步骤中进行了干预。它基本上总是将未来标记的分数设为0,这样模型就不能提前看到未来的单词:

这种掩蔽通常是通过一个称为注意力掩蔽矩阵来实现的。想象一个由四个单词组成的序列(例如“robot must obey orders”)。在语言建模场景中,这个序列以四个步骤吸收——每个单词一步(假设现在每个单词都是一个标记)。由于这些模型以批量工作,我们可以假设这个玩具模型的批量大小为4,它将整个序列(及其四个步骤)作为一批处理。

在矩阵形式中,我们通过将查询矩阵乘以键矩阵来计算分数。让我们如下可视化它,只是不是单词,而是与该单词在该单元格中相关联的查询(或键)向量:

乘法之后,我们应用注意力掩蔽三角矩阵。它将我们想要掩蔽的单元格设置为负无穷大或一个非常大的负数(例如,在GPT-2中为-10亿):

然后,对每一行应用softmax会产生我们用于自注意力的实际分数:

这个分数表的意思是:
-
- 当模型处理数据集中的第一个示例(行#1),其中只包含一个单词(“robot”),它的全部注意力(100%)将集中在那个单词上。
-
- 当模型处理数据集中的第二个示例(行#2),其中包含单词(“robot must”),当它处理单词“must”时,它的48%注意力将集中在“robot”上,52%的注意力将集中在“must”上。
Masked Self-Attention
Evaluation Time: Processing One Token at a Time
我们可以按照掩蔽自注意力的工作方式使GPT-2运行。但在评估期间,当我们的模型在每次迭代后只添加一个新词,对于已经处理过的标记,重新计算早期路径上的自注意力将是低效的。
在这种情况下,我们处理第一个标记(现在先忽略s)。

GPT-2保留“a”这个标记的键(key)和值(value)向量。每个自注意力层都保留该标记的相应的键和值向量:

现在在下一次迭代中,当模型处理单词“robot”时,它不需要为“a”标记生成查询(query)、键(key)和值(value)。它只需重用第一次迭代中保存的那些:

Self-attention: 1- Creating queries, keys, and values
- 假设模型正在处理单词 “it”。如果我们谈论的是底层区块,那么该标记的输入将是 “it” 的嵌入和 #9 位置的位置上编码:

Transformer中的每个区块都有自己的权重(文章后面会分解)。我们首先遇到的是用于创建查询、键和值的权重矩阵。

乘法的结果是一个向量,基本上是单词 “it” 的查询、键和值向量的串联。

GPT-2 Self-attention: 1.5- Splitting into attention heads
在前面的示例中,我们直接深入到自注意力中,忽略了“多头”部分。现在对这一概念进行一些说明将是有用的。自注意力在 Q、K、V 向量的不同部分上多次进行。“划分”注意力头仅仅是将长向量重塑为矩阵。小型 GPT-2 有 12 个注意力头,因此这将是重塑矩阵的第一个维度:

GPT-2 Self-attention: 2- Scoring
我们现在可以继续进行打分——知道我们只看一个注意力头(并且所有其他头正在进行类似的操作)

现在,令牌可以根据所有其他令牌的键进行评分(这些键在之前的迭代中已在注意力头 #1 中计算出):

GPT-2 Self-attention: 3- Sum
如我们之前所见,现在我们将每个值与其得分相乘,然后将它们相加,生成注意力头 #1 的自注意力结果:

GPT-2 Self-attention: 3.5- Merge attention heads
我们处理不同注意力头的方式是首先将它们连接成一个向量:

但是,这个向量还不能直接发送到下一个子层。我们需要先把这个拼凑出来的隐含状态“怪物”转化为一个统一的表示。
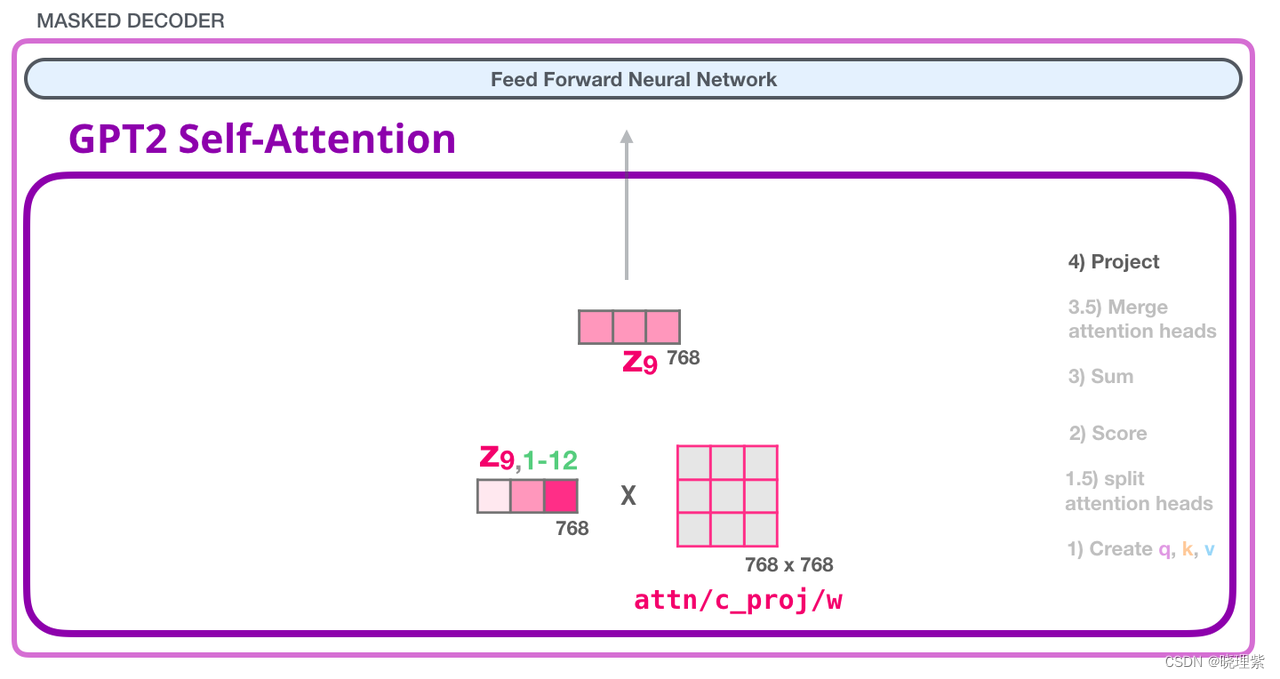
GPT-2 Self-attention: 4- Projecting
我们让模型学习如何最好地将连接起来的自注意力结果映射成一个前馈神经网络可以处理的向量。接下来是我们第二个大的权重矩阵,它将注意力头的结果投射到自注意力子层的输出向量:

至此,我们已经生成了可以传递到下一层的向量:
翻译自(https://jalammar.github.io/illustrated-transformer/)