上海优秀网站建设公司seo技术培训唐山
🥇🥇【大数据学习记录篇】-持续更新中~🥇🥇
个人主页:beixi@
本文章收录于专栏(点击传送):【大数据学习】
💓💓持续更新中,感谢各位前辈朋友们支持学习~💓💓
文章目录
- 1.Flume集群环境介绍
- 2.搭建环境介绍
- 3.启动HDFS集群环境
- 4.Flume集群环境搭建
1.Flume集群环境介绍
Flume是一个分布式、可靠和高可用性的数据采集工具,用于将大量数据从各种源采集到Hadoop生态系统中进行处理。在大型互联网企业的数据处理任务中,Flume被广泛应用。
Flume集群环境介绍:
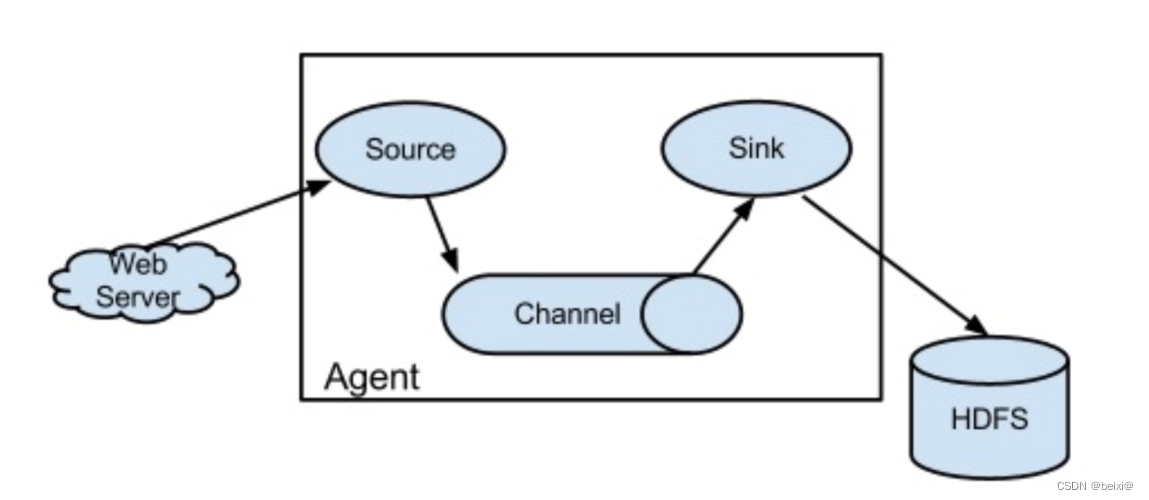
Agent:Flume的基本组成单元是Agent,用于在不同的节点之间传输数据。Agent可以是单节点或分布式部署。
Source:Source是Flume数据采集的起点,用于从数据源(如日志文件、网络流、消息队列等)中获取数据并将其发送到Channel中。Flume支持多种Source类型,如Avro、Netcat、Exec等。
Channel:Channel是Flume的缓存区,用于暂存从Source获取的数据。Flume支持多种Channel类型,如Memory、File、Kafka等,可以根据数据量和数据传输速率选择合适的Channel类型。
Sink:Sink是Flume的目标,用于将数据输出到指定的目标位置。Flume支持多种Sink类型,如HDFS、HBase、Elasticsearch等。
Event:Event是Flume传输的基本单元,表示采集到的数据。一个Event包含Header和Body两个部分,其中Header用于描述Event的属性(如时间戳、数据类型等),Body是实际的数据内容。
Collector:Collector用于收集Flume的监控信息,如Agent的启停状态、数据采集速率等。Flume提供了Web界面和API接口来实现监控和管理。
Flume逻辑上分三层架构:agent,collector,storage。agent用于采集数据,agent是Flume中产生数据流的地方,同时,agent会将产生的数据流传输到collector。collector的作用是将多个agent的数据汇总后,加载到storage中。storage是存储系统,可以是一个普通file,也可以是HDFS,HIVE,HBase等。
2.搭建环境介绍
本次搭建的环境有:
Oracle Linux 7.4,三台虚拟机,分别为master,slave1,slave2
JDK1.8.0_144
Hadoop2.7.4集群环境
Flume1.6.0
3.启动HDFS集群环境
1.打开master命令窗口,启动HDFS平台。
start-dfs.sh

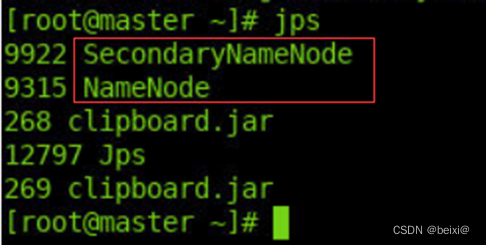
2.查看”主节点”上HDFS守护进程
jps
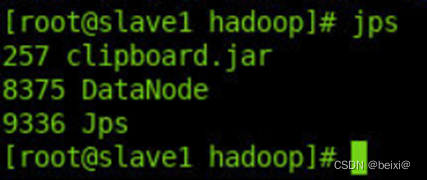
3.打开slave1从机命令窗口,查看HDFS守护进程。
jps
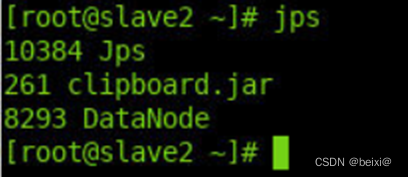
4.打开slave2从机命令窗口,查看HDFS守护进程。
jps
4.Flume集群环境搭建
1.打开master命令窗口。
2.解压Flume压缩文件至/opt目录。
tar -zxvf experiment/file/apache-flume-1.6.0-bin.tar.gz -C /opt

3.修改解压后文件夹的名字为flume。
mv /opt/apache-flume-1.6.0-bin /opt/flume

4.查看Flume配置文件目录conf
ll /opt/flume/conf/

5.复制Flume配置文件flume-env.sh.template名为flume-env.sh
cp /opt/flume/conf/flume-env.sh.template /opt/flume/conf/flume-env.sh

6.查找Java安装路径
echo $JAVA_HOME

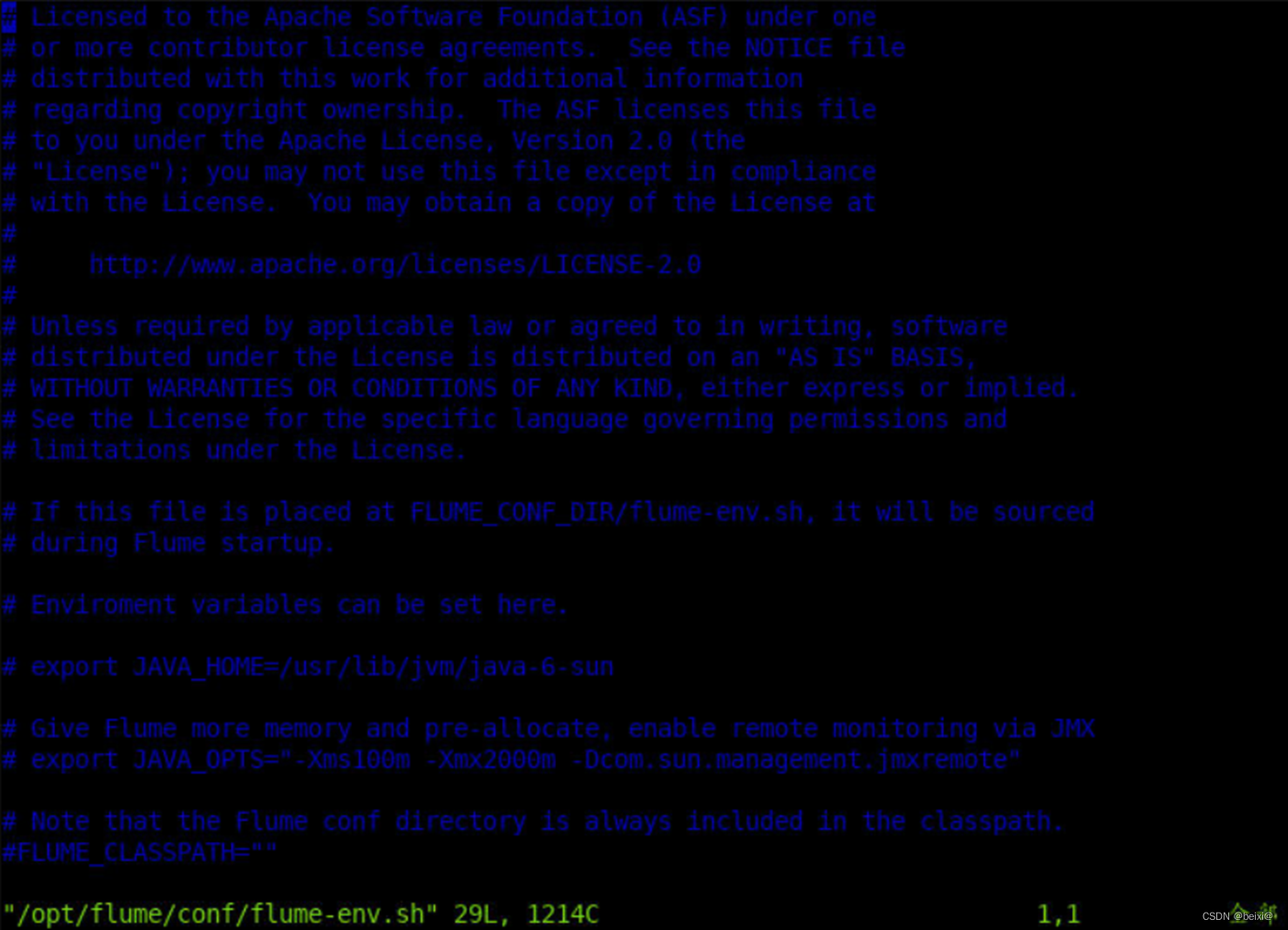
7.配置flume-env.sh文件
vim /opt/flume/conf/flume-env.sh
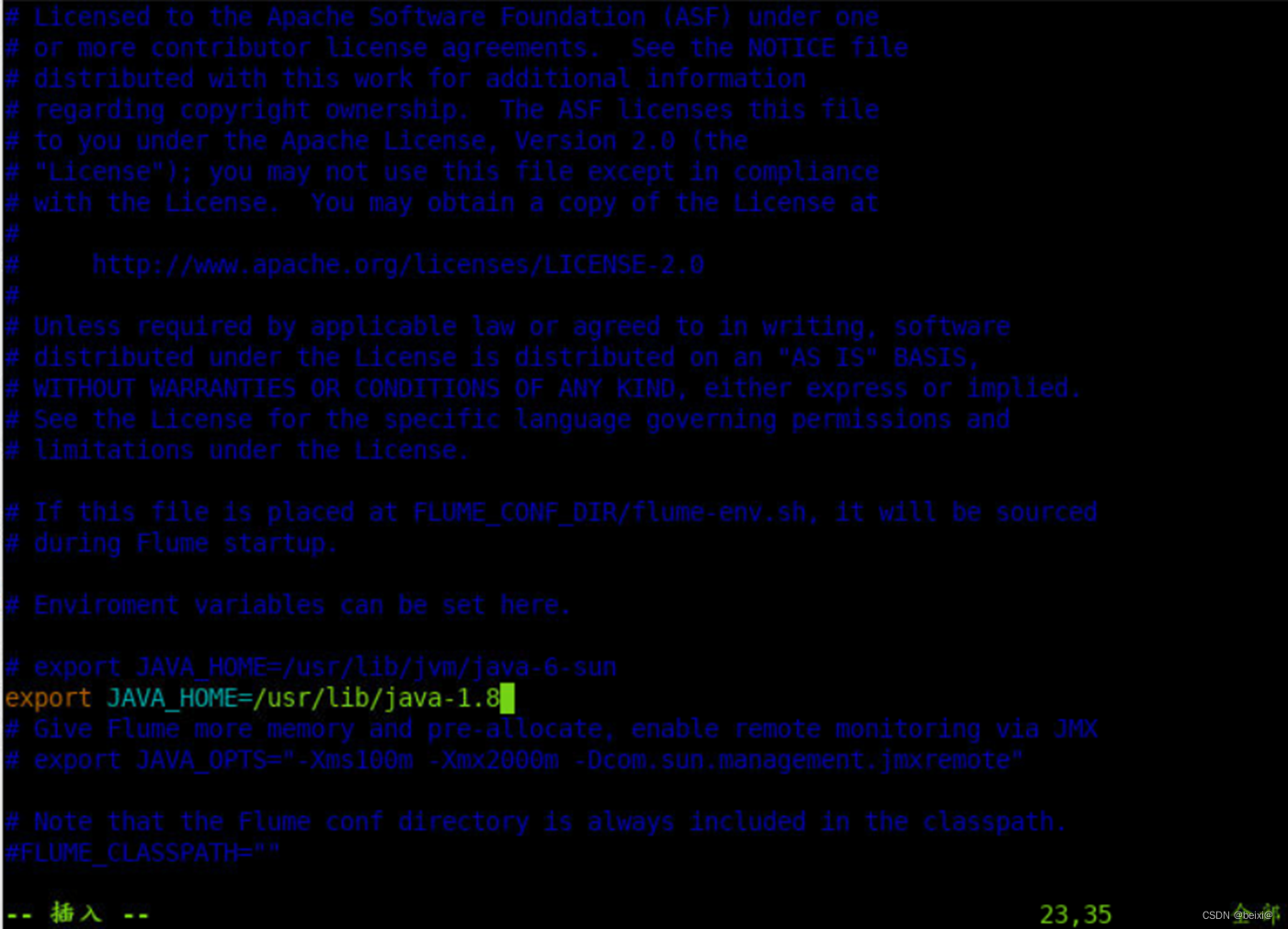
8.按键 i ,更改代码如下:
export JAVA_HOME=/usr/lib/java-1.8
9.按键Esc,按键”:wq!”保存退出。
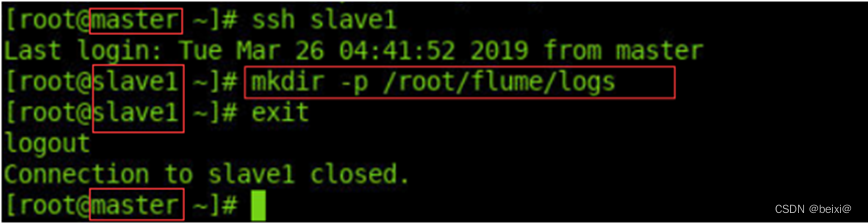
10.通过ssh命令,跳转至slave1机器命令窗口创建日志文件夹,再退回到master命令窗口。
ssh slave1
mkdir -p /root/flume/logs
exit
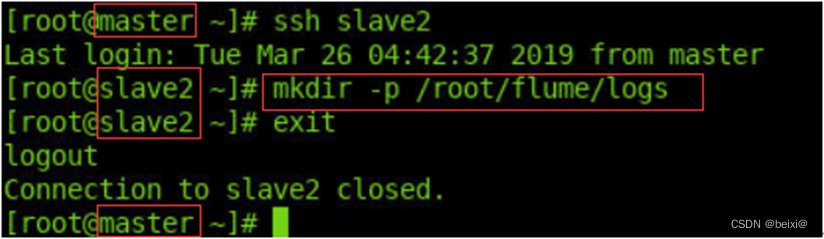
11.通过ssh命令,跳转至slave2机器命令窗口创建日志文件夹,再退回到master命令窗口。
ssh slave2
mkdir -p /root/flume/logs
exit
12.在当前“主节点”命令窗口中,配置slave.conf文件,进行配置。
vim /opt/flume/conf/slave.conf

13.按键 i ,更改代码如下:
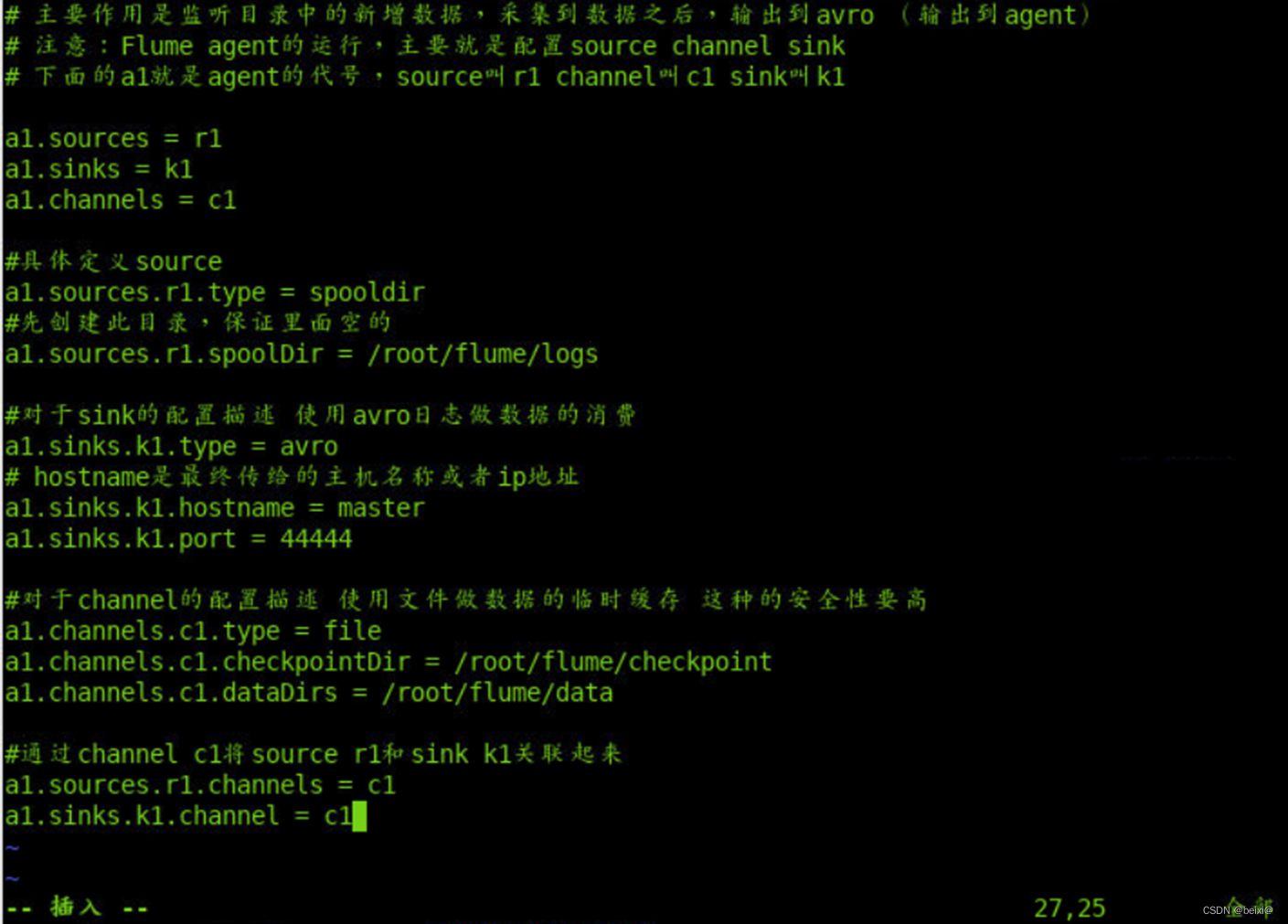
# 主要作用是监听目录中的新增数据,采集到数据之后,输出到avro (输出到agent)
# 注意:Flume agent的运行,主要就是配置source channel sink
# 下面的a1就是agent的代号,source叫r1 channel叫c1 sink叫k1
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#具体定义source
a1.sources.r1.type = spooldir
#先创建此目录,保证里面空的
a1.sources.r1.spoolDir = /root/flume/logs
#对于sink的配置描述 使用avro日志做数据的消费
a1.sinks.k1.type = avro
# hostname是最终传给的主机名称或者ip地址
a1.sinks.k1.hostname = master
a1.sinks.k1.port = 44444
#对于channel的配置描述 使用文件做数据的临时缓存 这种的安全性要高
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /root/flume/checkpoint
a1.channels.c1.dataDirs = /root/flume/data
#通过channel c1将source r1和sink k1关联起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
14.按键Esc,按键”:wq!”保存退出。
15.将flume分发至slave1、slave2机器。
scp -r /opt/flume slave1:/opt

scp -r /opt/flume slave2:/opt

16.配置master.conf文件
vim /opt/flume/conf/master.conf

17.按键 i ,更改代码如下:
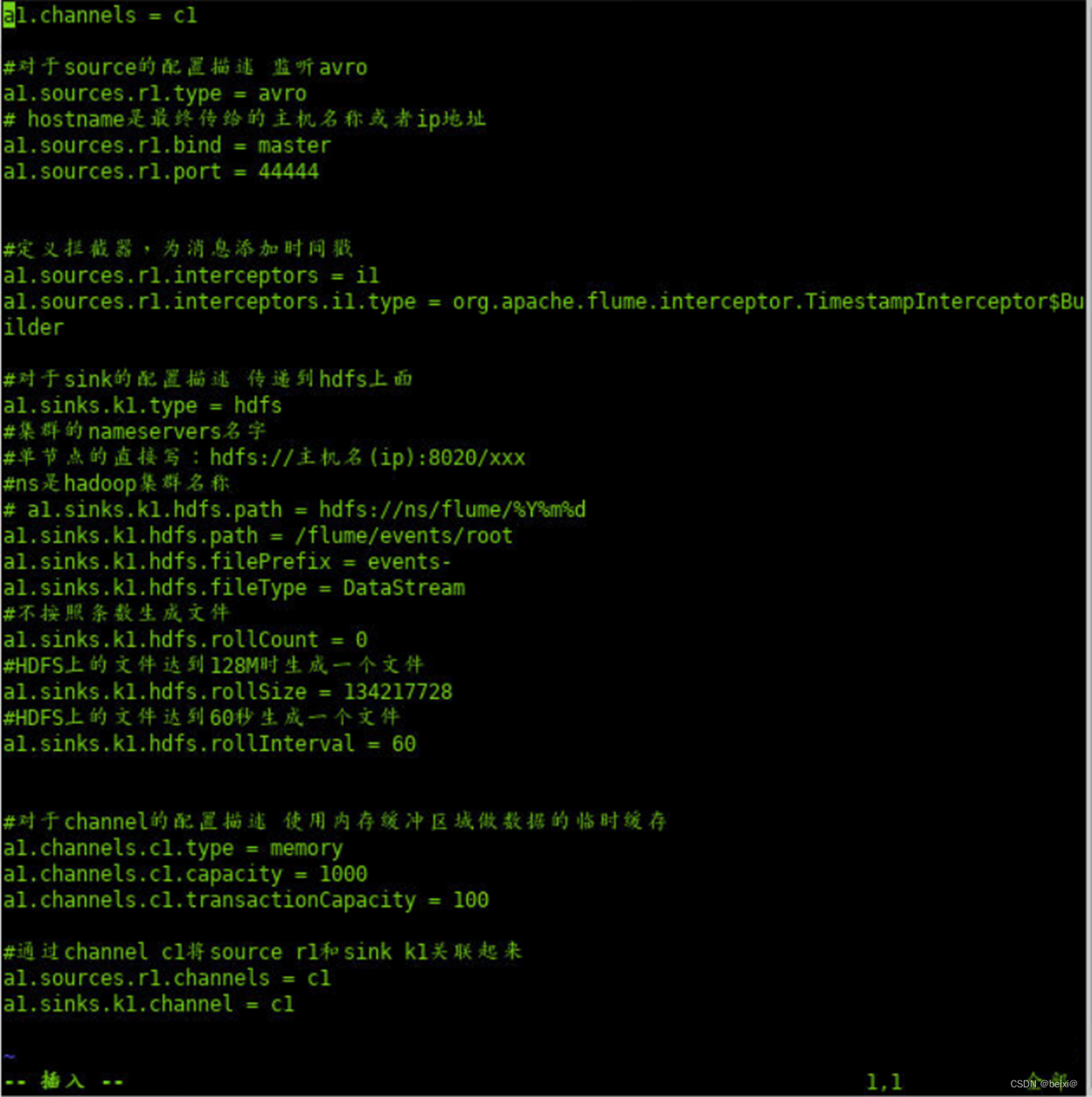
# 获取slave1,2上的数据,聚合起来,传到hdfs上面
# 注意:Flume agent的运行,主要就是配置source channel sink
# 下面的a1就是agent的代号,source叫r1 channel叫c1 sink叫k1a1.sources = r1
a1.sinks = k1
a1.channels = c1#对于source的配置描述 监听avro
a1.sources.r1.type = avro
# hostname是最终传给的主机名称或者ip地址
a1.sources.r1.bind = master
a1.sources.r1.port = 44444#定义拦截器,为消息添加时间戳
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder#对于sink的配置描述 传递到hdfs上面
a1.sinks.k1.type = hdfs
#集群的nameservers名字
#单节点的直接写:hdfs://主机名(ip):9000/xxx
#ns是hadoop集群名称
# a1.sinks.k1.hdfs.path = hdfs://ns/flume/%Y%m%d
a1.sinks.k1.hdfs.path = /flume/events/root
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.fileType = DataStream
#不按照条数生成文件
a1.sinks.k1.hdfs.rollCount = 0
#HDFS上的文件达到128M时生成一个文件
a1.sinks.k1.hdfs.rollSize = 134217728
#HDFS上的文件达到60秒生成一个文件
a1.sinks.k1.hdfs.rollInterval = 60 #对于channel的配置描述 使用内存缓冲区域做数据的临时缓存
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100#通过channel c1将source r1和sink k1关联起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
18.按键Esc,按键”:wq!”保存退出。
至此,Flume集群环境搭建就到此结束了,如果本篇文章对你有帮助记得点赞收藏+关注~