国内自动化网站建设网络营销推广方案3篇
目录
- 三模型架构
- BERT
- GPT
- ELMO
- 三者差异点
三模型架构
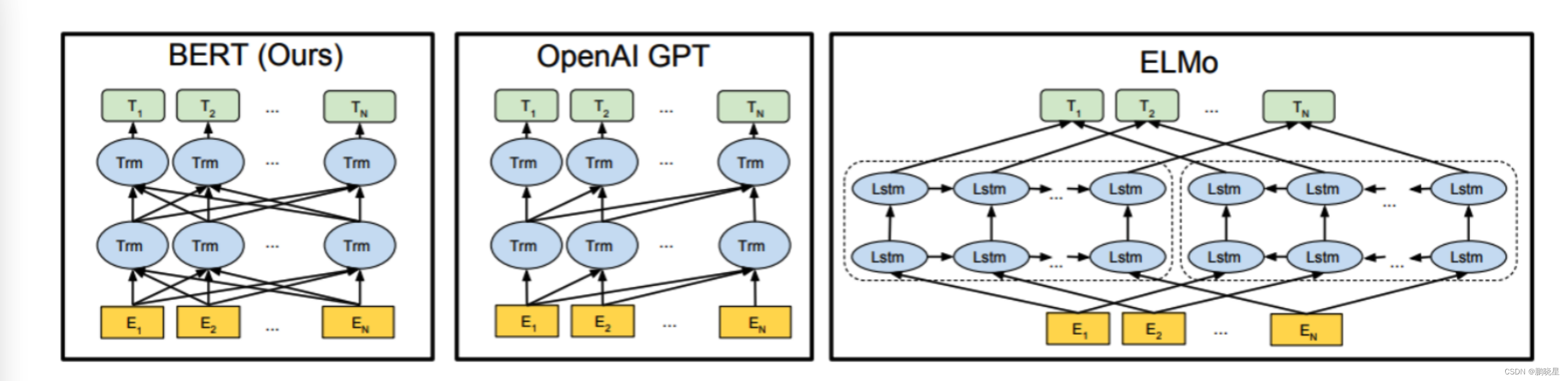
BERT
优点
- 在11个NLP任务上取得SOAT成绩.
- 利用了Transformer的并行化能力以及长语句捕捉语义依赖和结构依赖.
- BERT实现了双向Transformer并为后续的微调任务留出足够的空间.
缺点
- BERT模型太大, 太慢.
- BERT模型中的中文模型是以字为基本token单位的, 无法利用词向量, 无法识别生僻词.
- BERT模型中的MLM任务, [MASK]标记在训练阶段出现, 预测阶段不出现, 这种偏差会对模型有一定影响.
- BERT模型的MLM任务, 每个batch只有15%的token参与了训练, 造成大量文本数据的"无用", 收敛速度慢, 需要的算力和算时都大大提高.
文本截断处理方式
第一种方式就是只保留前面510个token.
第二种方式就是只保留后面510个token.
第三种方式就是前后分别保留一部分token, 总数是510.
BERT预训练模型所接收的最大sequence长度是512
bert + 迁移学习 简单练习代码
步骤:
微调脚本
# 使用python运行微调脚本
# --model_name_or_path: 选择具体的模型或者变体
# --task_name: 它将代表对应的任务类型, 如MRPC代表句子对二分类任务
# --do_train: 使用微调脚本进行训练
# --do_eval: 使用微调脚本进行验证
# --max_seq_length: 输入句子的最大长度, 超过则截断, 不足则补齐
# --learning_rate: 学习率
# --num_train_epochs: 训练轮数
# --output_dir $SAVE_DIR: 训练后的模型保存路径
# --overwrite_output_dir: 再次训练时将清空之前的保存路径内容重新写入# 该命令已在虚拟机执行,再次执行会覆盖缓存的模型python run_glue.py \--model_name_or_path bert-base-chinese \--task_name sst2 \--do_train \--do_eval \--max_seq_length 128 \--learning_rate 2e-5 \--num_train_epochs 1.0 \--output_dir bert-base-chinese-sst2-finetuning
import torch
# 0 找到自己预训练模型的路径
mymodelname = '/Users/lizhipeng/PycharmProjects/newProject/fasttext/transformers/examples/pytorch/text-classification/bert-base-chinese-sst2-finetuning'
print(mymodelname)# 1 本地加载预训练模型的tokenizer
tokenizer = AutoTokenizer.from_pretrained(mymodelname)# 2 本地加载 预训练模型 带分类模型头
model = AutoModelForSequenceClassification.from_pretrained(mymodelname)text = "早餐不好,服务不到位,晚餐无西餐,早餐晚餐相同,房间条件不好"
index = tokenizer.encode(text)
tokens_tensor = torch.tensor([index])# 使用评估模式
with torch.no_grad():# 使用模型预测获得结果result = model(tokens_tensor)print(result[0])predicted_label = torch.argmax(result[0]).item()
print('预测标签为>', predicted_label)text1 = "房间应该超出30平米,是HK同级酒店中少有的大;重装之后,设备也不错."
index = tokenizer.encode(text1)
tokens_tensor = torch.tensor([index])# 使用评估模式
with torch.no_grad():# 使用模型预测获得结果result = model(tokens_tensor)print(result[0])predicted_label = torch.argmax(result[0]).item()
print('预测标签为>', predicted_label)输出:
输入文本为: 早餐不好,服务不到位,晚餐无西餐,早餐晚餐相同,房间条件不好
预测标签为: 0
输入文本为: 房间应该超出30平米,是HK同级酒店中少有的大;重装之后,设备也不错.
预测标签为: 1
GPT
优点
GPT使用了Transformer提取特征, 使得模型能力大幅提升.
缺点
GPT只使用了单向Decoder, 无法融合未来的信息.
ELMO
优点
-ELMo根据上下文动态调整word embedding, 可以解决多义词的问题.
缺点
- ELMo使用LSTM提取特征的能力弱于Transformer
- ELMo使用向量拼接的方式融合上下文特征的能力弱于Transformer
三者差异点
关于特征提取器
- ELMo采用两部分双层双向LSTM进行特征提取, 然后再进行特征拼接来融合语义信息.
- GPT和BERT采用Transformer进行特征提取.
- 很多NLP任务表明Transformer的特征提取能力强于LSTM, 对于ELMo而言, 采用1层静态token embedding + 2层LSTM, 提取特征的能力有限.
单/双向语言模型
- 三者之中, 只有GPT采用单向语言模型, 而ELMo和BERT都采用双向语言模型.
- ELMo虽然被认为采用了双向语言模型, 但实际上是左右两个单向语言模型分别提取特征, 然后进行特征拼接, 这种融合特征的能力比BERT一体化的融合特征方式弱.
- 三者之中, 只有ELMo没有采用Transformer. GPT和BERT都源于Transformer架构, GPT的单向语言模型采用了经过修改后的Decoder模块, Decoder采用了look-ahead mask, 只能看到context before上文信息, 未来的信息都被mask掉了. 而BERT的双向语言模型采用了Encoder模块, Encoder只采用了padding mask, 可以同时看到context before上文信息, 以及context after下文信息.
心得:模型已浅知,内化成自己掌握的知识还需多学多看