东莞专业网站推广多少钱百度搜索风云榜人物
目录
一、XML快速入门
1.基本介绍 :
2.入门案例 :
二、XML语法
0.文件结构 :
1.文档声明 :
2. 元素 :
3.属性 :
4.注释 :
5.CDATA节 :
PS : XML转义符 :
三、Dom4j
1.关于XML解析技术 :
2° Dom4j介绍 :
3.Dom4j使用 :
1° 获取Document对象的三种方式
2° 代码演示
1>准备工作(引入jar包)
2>遍历和获取XML文件的元素
四、XML总结
一、XML快速入门
1.基本介绍 :
XML 指可扩展标记语言(Extensible Markup Language)。
XML 被设计用来传输和存储数据,能存储复杂的数据关系。
XML能干什么?
①解决程序间数据传输的问题(目前主流的传输格式是json),具有良好的可读性,可维护性。
②xml 可以作配置文件(使用最多)
eg : tomcat 服务器的 server.xml ,web.xml
③xml 可以充当小型的数据库(用的很少,因为很多程序为了安全都有自己的数据存储格式)。但是xml 文件做小型数据库,也是不错的选择,我们程序中可能用到的数据,如果放在数据库中读取不合适(因为你要增加维护数据库工作),可以考虑直接用 xml 来做小型数据库 ,而且直接读取文件显然要比读取数据库快。
2.入门案例 :
在IDEA中新建一个File,以.xml作为文件后缀名。
模拟存储两个学生的信息,代码如下 :
<?xml version="1.0" encoding="utf-8" ?>
<!--(1)<?xml version="1.0" encoding="utf-8" ?>用于说明文档信息xml : 表示文件类型是XML文件;version="1.0" : 表示通用的版本1.0,文档符合 XML1.0 规范;encoding="utf-8" : 表示文档的编码类型是UTF-8;(2)<students></students> : 此处表示root元素,可由程序员自主决定(3)<stu></stu> : 此处表示students元素的一个子元素,可以有任意多个(4)id : 此处为stu元素的属性(5)name,age,sex,score : 此处为stu元素的子元素,理论上子元素可以无限嵌套
-->
<students><stu id="1"><name>Cyan</name><age>21</age><sex>male</sex><score>423</score></stu><stu id="2"><name>Five</name><age>20</age><sex>female</sex><score>418</score></stu>
</students>二、XML语法
0.文件结构 :
1° 文档声明
2° 元素
3° 属性
4° 注释
5° CDATA 区 、特殊字符
1.文档声明 :
<?xml version="1.0" encoding="utf-8" ?>表示文档说明,用于说明文档信息,声明要放在 XML 文档的第一行。
xml : 表示文件类型是XML文件;
version="1.0" : 文档符合 XML1.0 规范;
encoding="utf-8" : 表示文档的编码类型是UTF-8(UTF-8是主流编码);PS : XML中注释的格式与HTML中相同。
2. 元素 :
1° 关于根元素——
①每个XML文档必须有且只有一个根元素。
②根元素是一个完全包括文档中其他所有元素的元素。
③根元素的起始标记要放在所有其他元素的起始标记之前;根元素的结束标记要放在所有其他元素的结束标记之后。2° 关于普通XML元素——
①XML 元素指 XML 文件中出现的标签,一个标签分为开始标签和结束标签,若一个标签没有标签体,以<age></age>为例,可以简写为<age/>。
②一个标签中也可以嵌套若干子标签,并且允许有同名的元素存在;但所有标签都必须合理的嵌套,绝对不允许交叉嵌套。3° 关于XML元素的命名规则——
①区分大小写,eg : <P>和<p>是两个不同的标记。
②不能以数字开头。
③中间不能包含空格。
④名称中间不能包含冒号(:)。
⑤如果标签单词需要间隔,建议使用下划线。
代码演示 :
<?xml version="1.0" encoding="UTF-8" ?><root> <!-- Has one and only one root element --><bough><branch><branch/> <!-- non-tagBody's Abbreviation --></branch></bough><Bough> <!-- That's two different tag. --><branch><!--<3p></3p> can't be allowed<my name></my name> can't be allowed<my:name></my:name> can't be allowed;<my_name></my_name> is allowed.--></branch></Bough>
</root>3.属性 :
1° XML中属性的使用,和HTML中的类似;一个元素可以有多个属性,多个属性之间用空格分隔。区别——
①HTML中,同名的属性不会报错,而是只生效首次定义的属性;而在XML中,特定的属性名称在同一个元素标记中只能出现一次,否则直接报错"Duplicate attribute 属性名"。
②HTML中,属性值可以有&字符,&字符会影响属性的作用效果;而在XML中,属性值不能包括& 字符,否则直接报错。
2° XML中,当属性值中含有',外部用"分隔;当属性值中含有",外部则用'分隔;即内单外双,内双外单。
代码演示 :
<?xml version="1.0" encoding="UTF-8" ?><root><bough id="1" name="bough'1"> <!-- 属性值内有单引号,外面用双引号 --><branch color="cyan"></branch></bough><bough id="2" name='bough"1'> <!-- 属性值内有双引号,外面用单引号 --><!--<branch color="cyan" color="pink"></branch> //多个color不被允许--><!--<branch color="&id"></branch> //&id不被允许--></bough>
</root>4.注释 :
1. <!--XML中的注释与HTML中用法相同- ->
2. 注释内容中不要出现--;
3. 不要把注释放在标记中间;错误写法 <Name <!--the name-->>TOM</Name>
4. 注释不能嵌套;
5. 可以在除标记以外的任何地方放注释
5.CDATA节 :
若XML中有些内容不想让解析引擎执行,而是当作原始内容处理(即当做普通文本处理),可以使用 CDATA 将其包括起来,CDATA 节/元素中的所有字符都会被当作简单文本,而不是 XML 标记。
格式如下:
<![CDATA[
需要保存的文本写在这儿(eg : 代码片段)
]]>
PS:<![CDATA[ ]]>中可以输入任意字符(]]>除外);但不能嵌套使用。
代码演示 :
<?xml version="1.0" encoding="UTF-8" ?><root><code><![CDATA[<script type="text/javascript">window.onload = function () {//查找 id=language 下所有 li 节点var btn_4 = document.getElementById("btn_4");btn_4.onclick = function () {//此处缩小了dom对象的范围!var lis = document.getElementById("language").getElementsByTagName("li");alert("lis = " + lis); //HTMLCollectionfor (var i = 0; i < lis.length; ++i) {alert("lis[" + i + "] = " + lis[i].innerText);}}}</script>]]></code>
</root>PS : XML转义符 :
对于一些单个字符,若想显示其原始样式,也可以使用转义的形式予以处理,转义字符在解析时会被解析成对应的文本。XML中的转义字符有点类似于HTML中的“字符实体”,但又有所区别。
常见转义字符如下——
转义符 对应符号 < < > > & & " " &apos '
三、Dom4j
1.关于XML解析技术 :
1° XML解析技术是指,将XML文档映射为一棵xml dom树,之后可以通过相应的Java技术来对dom树中的元素进行增删查改。不管是HTML文件还是XML文件,都属于标记型文档,都可以通过w3c组织提供的dom技术来解析,dom就是这样一种XML解析技术。
2° XML DOM (XML Document Object Model) 定义了访问和操作 XML 文档的标准方法。DOM 把 XML 文档作为树结构来查看。能够通过 DOM 树来访问所有元素。可以修改或删除它们的内容,并创建新的元素。元素,它们的文本,以及它们的属性,都被认为是节点,其中,document对象表示的是整个文档(可以是 html 文档,也可以是 xml 文档)。(联系JavaScript DOM树的结构图)
3° XML解析技术的历史 :
早期 JDK 为我们提供了两种 xml 解析技术 DOM 和 Sax——
(1)dom 解析技术是 W3C 组织制定的,而所有的编程语言都结合自身语言特点对这个解析技术进行了实现。 of course, Java 对 dom 技术解析也做了实现。
(2)sun 公司在 JDK5 版本对 dom 解析技术进行升级,产生了SAX(Simple API for XML )SAX解析,它是以类似事件机制通过回调告诉用户当前正在解析的内容;是一行一行的读取 xml 文件进行解析的;不会创建大量的 dom 对象。 所以它在解析 xml 的时候,在性能上优于 Dom 解析。
第三方的 XML 解析技术
(1)jdom 在 dom 基础上进行了封装。
(2)dom4j 又对 jdom 进行了封装,是当前主流的XML解析技术。
(3)pull主要用在 Android 手机开发,与sax非常类似,都是通过事件机制解析xml文件。
2° Dom4j介绍 :
1. Dom4j 是一个简单、灵活的开放源代码的库(用于解析/处理 XML 文件)。Dom4j 是由早期开发 JDOM 的人分离出来而后独立开发的。
2. 与 JDOM 不同的是,Dom4j 使用接口和抽象基类,虽然 Dom4j 的 API 相对要复杂一些,但它提供了比 JDOM 更好的灵活性。
3. Dom4j 是一个非常优秀的 Java XML API,具有性能优异、功能强大和极易使用的特点。现在很多软件采用的 Dom4j。
4. 使用 Dom4j 开发,需下载 dom4j 相应的 jar 文件.PS:Dom4j官方API文档——dom4j 1.6.1 API。
3.Dom4j使用 :
1° 获取Document对象的三种方式
(1)读取 XML 文件,获得 document 对象(目前还在使用)
SAXReader reader = new SAXReader(); //创建一个解析器
Document document = reader.read(new File("src/input.xml"));//XML Document
(2)解析 XML 形式的文本,得到 document 对象.(联系XML传输,应用场景不同)
String text = "<members></members>";
Document document = DocumentHelper.parseText(text);
(3)主动创建 document 对象. Document document = DocumentHelper.createDocument(); //创建根节点 (无中生有)
Element root = document.addElement("members")
2° 代码演示
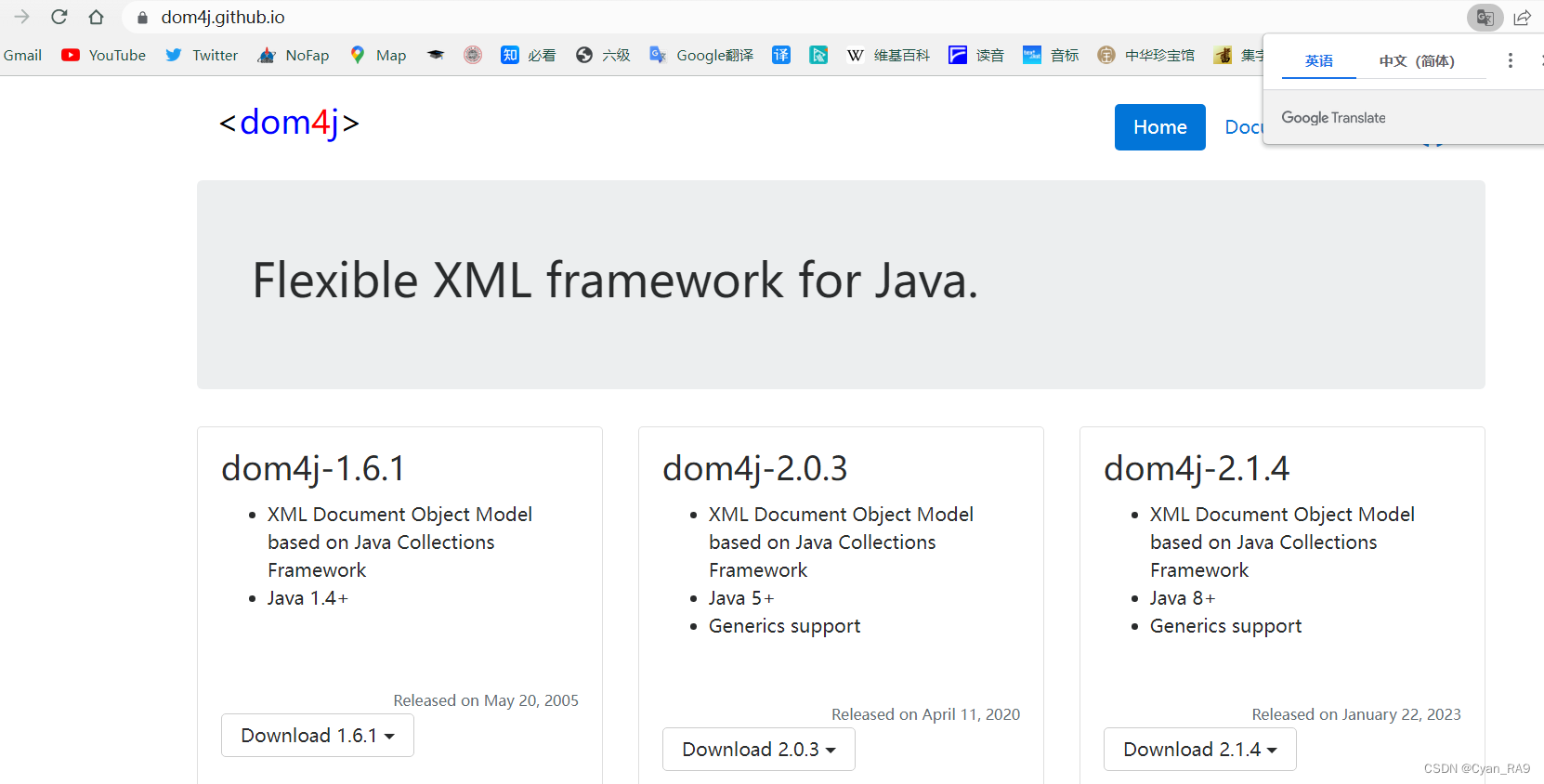
1>准备工作(引入jar包)
删去后缀,在Dom4j官网,下载jar包(版本不同不影响,XML的语法多年不变),如下图所示 :
演示的XML文件代码如下 :
<?xml version="1.0" encoding="UTF-8" ?><students><stu id="1"><name>Cyan</name><age>21</age><sex>male</sex><score>425</score></stu><stu id="2"><name>Kyrie</name><age>31</age><sex>male</sex><score>100</score></stu>
</students>
2>遍历和获取XML文件的元素
以Dom4j_Demo类为演示类,代码如下 :
package xml;import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import org.junit.jupiter.api.Test;import javax.xml.transform.sax.SAXResult;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.util.List;/*** @author : Cyan_RA9* @version : 21.0*/
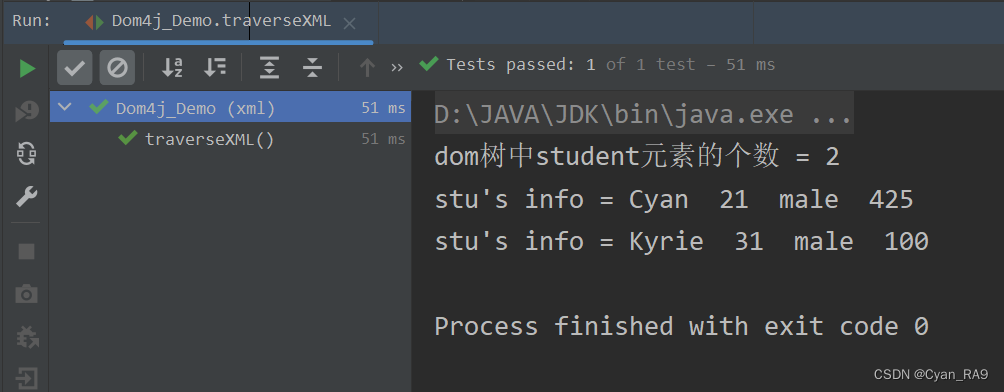
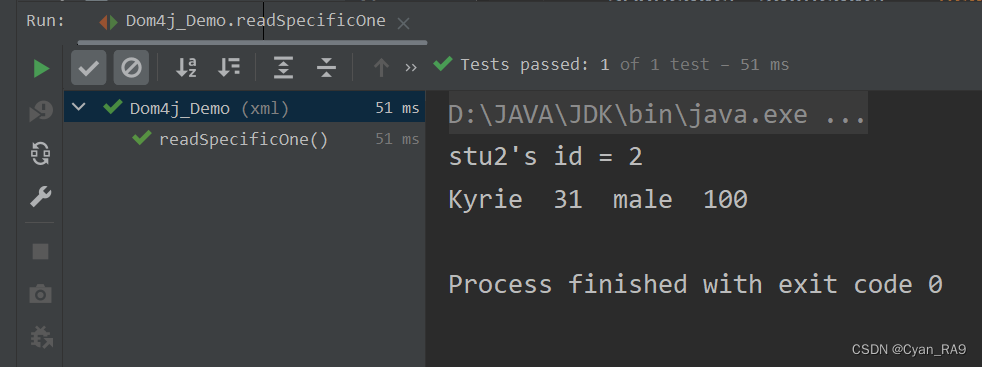
public class Dom4j_Demo {/*XML dom 树的结构———document(DefaultDocument)rootElement(DefaultElement)content(ArrayList)elementData(Object[])DefaultText(line feed) or DefaultElement(stu)-->...same*///遍历XML元素@Testpublic void traverseXML() throws FileNotFoundException, DocumentException {SAXReader saxReader = new SAXReader(); //得到一个解析器!Document document = saxReader.read(new FileInputStream("src/xml/dom4j_test.xml"));//1.先得到根结点Element rootElement = document.getRootElement();//2.得到根结点下的student元素List<Element> stus = rootElement.elements("stu");System.out.println("dom树中student元素的个数 = " + stus.size());for (Element stu : stus) {//3.注意区别elements方法和element方法的区别Element name = stu.element("name");Element age = stu.element("age");Element sex = stu.element("sex");Element score = stu.element("score");System.out.println(("stu's info = " + name.getText() + " " + age.getText() + " " +sex.getText() + " " + score.getText()));}}//获取XML指定元素/结点@Testpublic void readSpecificOne() throws DocumentException, FileNotFoundException {//得到一个解析器对象SAXReader saxReader = new SAXReader();//加载xml文件Document document = saxReader.read(new FileInputStream("src\\xml\\dom4j_test.xml"));//1.获取dom树的根结点Element rootElement = document.getRootElement();//2.获取stu对象的集合List<Element> stus = rootElement.elements("stu");//3.根据下标来获取指定的元素Element stu2 = (Element) stus.get(1);//4.attributeValue方法,可以获取元素的属性(同名属性是唯一的)System.out.println("stu2's id = " + stu2.attributeValue("id"));System.out.println((stu2.element("name").getText() + " " + stu2.element("age").getText() +" " + stu2.element("sex").getText() + " " + stu2.element("score").getText()));}
}
运行结果 :
四、XML总结
1° XML是一种可扩展的标记语言,其扩展性灵活性都达到了相当高度,目前XML最主流的使用就是作为配置文件。
2° XML文档最基本的结构是文档声明,元素, 属性, 注释, 也可能有CDATA元素,五部分。每部分的语法格式要熟悉。
3° 对于Dom4j,熟悉Dom4j的xml dom树的结构,掌握最基本的Dom4j对XML元素的获取。
System.out.println("END----------------------------------------------------------------------------");