哪个网站可以做图片链接郑州网站seo推广
1. 判别分析简介
判别分析(Discriminant Analysis) 是一种统计方法,用于在已知分类的样本中构建分类器,并根据特征变量对未知类别的样本进行分类。常见的判别分析方法包括线性判别分析(Linear Discriminant Analysis, LDA) 和 二次判别分析(Quadratic Discriminant Analysis, QDA)。
2. 判别分析原理
2.1 线性判别分析(LDA):
- 线性判别分析假设每个类别的数据在特征空间中服从高斯分布,并且各类别共享相同的协方差矩阵。
- 目标是找到一个投影方向,使得投影后不同类别的样本在该方向上的投影值具有最大的可分性。
- 判别函数为线性函数: δ k ( x ) = x T Σ − 1 μ k − 1 2 μ k T Σ − 1 μ k + log ( π k ) \delta_k(x) = x^T \Sigma^{-1} \mu_k - \frac{1}{2} \mu_k^T \Sigma^{-1} \mu_k + \log(\pi_k) δk(x)=xTΣ−1μk−21μkTΣ−1μk+log(πk) ,其中 μ k \mu_k μk 是第 k k k 类的均值向量, Σ \Sigma Σ 是协方差矩阵, π k \pi_k πk 是第 k k k 类的先验概率。
- 二次判别分析(QDA):
- 二次判别分析不假设各类别的协方差矩阵相同,因此判别函数为二次函数。
- 判别函数为: δ k ( x ) = − 1 2 log ∣ Σ k ∣ − 1 2 ( x − μ k ) T Σ k − 1 ( x − μ k ) + log ( π k ) \delta_k(x) = -\frac{1}{2} \log|\Sigma_k| - \frac{1}{2} (x - \mu_k)^T \Sigma_k^{-1} (x - \mu_k) + \log(\pi_k) δk(x)=−21log∣Σk∣−21(x−μk)TΣk−1(x−μk)+log(πk),其中 Σ k \Sigma_k Σk 是第 k k k 类的协方差矩阵。
3. 案例分析
3.1 数据集介绍
我们将生成一个包含两个类别(Class 1 和 Class 2)的数据集,每个类别各有50个样本。每个样本包含两个特征(Feature 1 和 Feature 2)。
3.2 数据生成
我们使用mvnrnd函数生成多元正态分布的随机数,可以通过调整mu和sigmal来改变数据的混乱程度。
% 生成数据
rng(1); % 设置随机种子以保证可重复性% 类别1的数据
mu1 = [2, 3];
sigma1 = [2, 1.5; 1.5, 2];
data1 = mvnrnd(mu1, sigma1, 50);% 类别2的数据
mu2 = [5, 6];
sigma2 = [2, -1.5; -1.5, 2];
data2 = mvnrnd(mu2, sigma2, 50);% 合并数据
data = [data1; data2];
labels = [ones(50, 1); ones(50, 1) * 2];% 可视化数据
figure;
scatter(data1(:,1), data1(:,2), 'r', 'filled');
hold on;
scatter(data2(:,1), data2(:,2), 'b', 'filled');
xlabel('Feature 1');
ylabel('Feature 2');
legend('Class 1', 'Class 2');
title('Generated Data for Discriminant Analysis');
hold off;
生成数据以后,绘制数据的散点图如下:

3.3 线性判别分析模型
我们将使用线性判别分析(LDA)对数据进行分类:
% 打乱数据
randIndex = randperm(length(labels));
data = data(randIndex, :);
labels = labels(randIndex, :);% 拆分训练集和测试集
cv = cvpartition(labels, 'HoldOut', 0.3);
trainData = data(training(cv), :);
trainLabels = labels(training(cv));
testData = data(test(cv), :);
testLabels = labels(test(cv));% 训练QDA模型
qdaModel = fitcdiscr(trainData, trainLabels, 'DiscrimType', 'quadratic');% 预测
predictedLabels = predict(qdaModel, testData);% 计算准确率
accuracy = sum(predictedLabels == testLabels) / length(testLabels);
fprintf('QDA Classification Accuracy: %.2f%%\n', accuracy * 100);% 可视化判别边界
figure;
gscatter(data(:,1), data(:,2), labels, 'rb', 'oo');
hold on;% 绘制决策边界
xrange = linspace(min(data(:,1)), max(data(:,1)), 100);
yrange = linspace(min(data(:,2)), max(data(:,2)), 100);
[x, y] = meshgrid(xrange, yrange);
xy = [x(:) y(:)];
predGrid = predict(qdaModel, xy);
predGrid = reshape(predGrid, size(x));contour(x, y, predGrid, [1.5 1.5], 'k', 'LineWidth', 2);
xlabel('Feature 1');
ylabel('Feature 2');
legend('Class 1', 'Class 2', 'Decision Boundary');
title('QDA Decision Boundary');
hold off;
得到线性判别分析模型分类的准确率为93.33%。
分类结果可视化如下:
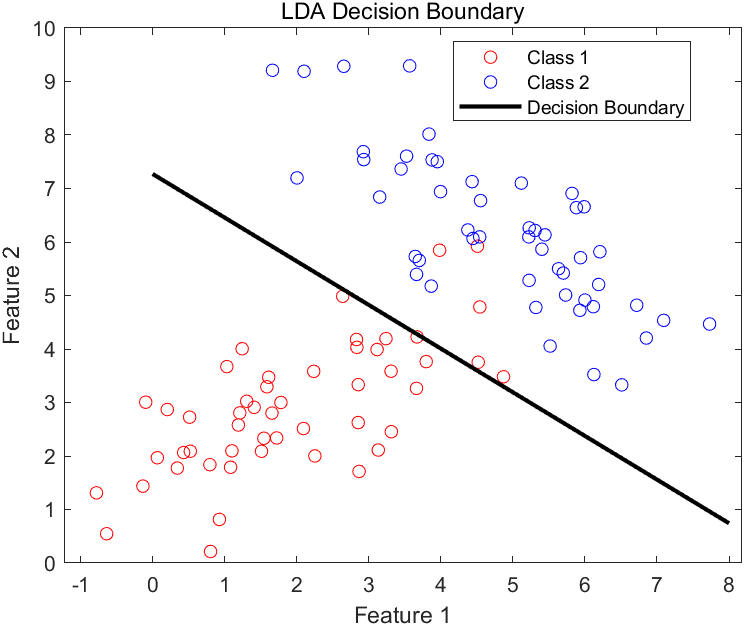
3.4 二次判别分析模型
我们将使用二次判别分析(QDA)对数据进行分类:
% 打乱数据
randIndex = randperm(length(labels));
data = data(randIndex, :);
labels = labels(randIndex, :);% 拆分训练集和测试集
cv = cvpartition(labels, 'HoldOut', 0.3);
trainData = data(training(cv), :);
trainLabels = labels(training(cv));
testData = data(test(cv), :);
testLabels = labels(test(cv));% 训练QDA模型
qdaModel = fitcdiscr(trainData, trainLabels, 'DiscrimType', 'quadratic');% 预测
predictedLabels = predict(qdaModel, testData);% 计算准确率
accuracy = sum(predictedLabels == testLabels) / length(testLabels);
fprintf('QDA Classification Accuracy: %.2f%%\n', accuracy * 100);% 可视化判别边界
figure;
gscatter(data(:,1), data(:,2), labels, 'rb', 'oo');
hold on;% 绘制决策边界
xrange = linspace(min(data(:,1)), max(data(:,1)), 100);
yrange = linspace(min(data(:,2)), max(data(:,2)), 100);
[x, y] = meshgrid(xrange, yrange);
xy = [x(:) y(:)];
predGrid = predict(qdaModel, xy);
predGrid = reshape(predGrid, size(x));contour(x, y, predGrid, [1.5 1.5], 'k', 'LineWidth', 2);
xlabel('Feature 1');
ylabel('Feature 2');
legend('Class 1', 'Class 2', 'Decision Boundary');
title('QDA Decision Boundary');
hold off;
得到二次判别分析模型分类的准确率为96.67%。
分类结果可视化如下:
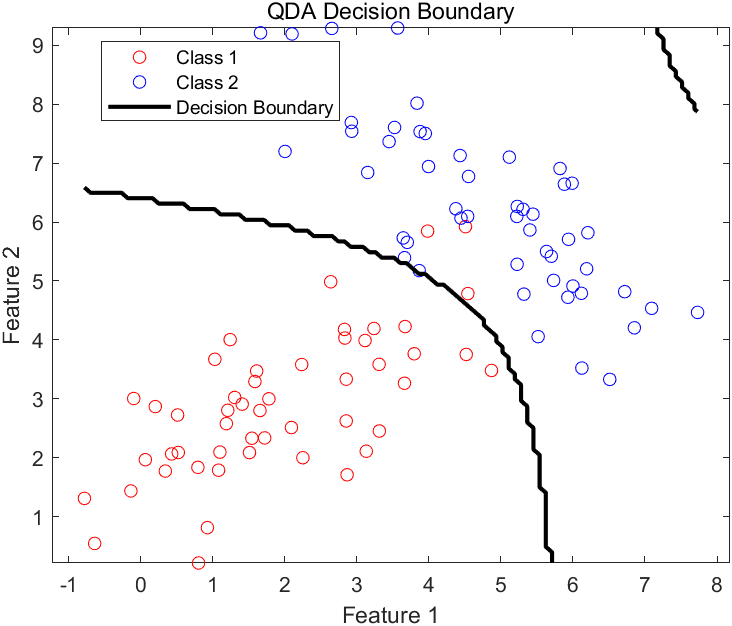
4. 总结
判别分析是一种有效的分类方法,通过对特征空间中数据分布的建模,可以实现对未知样本的分类。本文通过一个具体的案例展示了如何生成数据并使用MATLAB实现线性判别分析模型和二次判别分模型,并进行了分类准确率的计算和决策边界的可视化。