好看的扁平化网站seo关键词查询排名软件
AI 云原生开发的核心在于 “模型能力 × AI 开发平台”。在本次开发体验中,以 Trae 作为 IDE 环境,结合火山方舟通过 MCP 协议无缝调用模型服务与云端工具,再加上豆包大模型1.6强大的思考、多模态等能力,形成了一套真正的端到端 Agent 构建流程。下面我们开始正文分享!
Doubao-Seed-1.6系列模型
2025春季Force大会这次火山引擎带来Doubao-Seed-1.6系列模型

体验地址: https://console.volcengine.com/ark/region:ark+cn-beijing/experience/chat
豆包大模型1.6,由三个模型组成:
- doubao-seed-1.6-thinking:在深度思考方面的强化版, 对比doubao-1.5-thinking,在coding、math、 逻辑推理等基础能力上进一步提升,且支持了视觉理解 。
- doubao-seed-1.6:能力多面手,同时支持thinking/non-thinking/自适应思考三种模式 。non-thinking对比上一代模型在推理、数学、代码、专业知识等方面,有全面的提升。自适应思考,模型可以根据prompt难度自动决定是否思考,在效果接近thinking模式情况下,大幅减少tokens开销。此外,该模型还针对前端编程能力做了加强 。
- doubao-seed-1.6-flash,具备极致的速度,tpot仅需10ms,同时支持文本和视觉理解,文本理解能力超过上一代lite。
豆包1.6重点能力:推理能力、多模态理解能力、GUI操作能力

下面是具体的对比和介绍,大家可以看下这个表格
| 特性 | Doubao-Seed-1.6-thinking/250615 | Doubao-Seed-1.6/250615 | Doubao-Seed-1.6-flash/250615 |
|---|---|---|---|
| 一句话说明 | 思考能力强化、支持多模态、256K长上下文 | 支持thinking/non-thinking/auto三种思考模式、支持多模态、256K长上下文 | 极致速度、支持多模态、256K长上下文 |
| 模型简介 | 思考能力大幅强化,对比Doubao-1.5-thinking-pro,在Coding、Math、逻辑推理等基础能力上进一步提升,支持视觉理解。支持256k上下文窗口,输出长度支持最大16k tokens | 全新多模态深度思考模型,同时支持auto/thinking/non-thinking三种思考模式。non-thinking模式下,模型效果对比Doubao-1.5-pro/250115大幅提升。支持256k上下文窗口,输出长度支持最大16k tokens | 推理速度极致的多模态深度思考模型,TPOT仅需10ms;同时支持文本和视觉理解,文本理解能力超过上一代lite,视觉理解比肩友商pro系列模型。支持256k上下文窗口,输出长度支持最大16k tokens |
不同技术参数的对比
| 规格项 | Doubao-Seed-1.6-thinking | Doubao-Seed-1.6 | Doubao-Seed-1.6-flash |
|---|---|---|---|
| 输入 | 文本、图片、视频 | 文本、图片、视频 | 文本、图片、视频 |
| 输出 | 文本 | 文本 | 文本 |
| 是否输出思考过程 | ✅ 思考内容:reasoning_content 思考token统计:reasoning_tokens ❌ 不支持关闭思考 | ✅ 思考内容:reasoning_content 思考token统计:reasoning_tokens 默认开启思考 支持enabled、disabled、auto | ✅ 思考内容:reasoning_content 思考token统计:reasoning_tokens 默认开启思考 支持enabled、disabled |
| 推理速度(TPOT) | 30 ms | 30 ms | 10 ms |
| Function calling | ✅ | ✅ | ✅ |
| Structured Outputs | ✅ JSON Object ✅ JSON Schema | ✅ JSON Object ✅ JSON Schema | ✅ JSON Object ✅ JSON Schema |
| 批量推理 | ✅ | ✅ | ✅ |
| 上下文窗口 | 256k | 256k | 256k |
| 最大思维链长度 | 32k | 32k | 32k |
| 最大输入 | 224k | 224k | 224k |
| 最大输出 | 16k,默认4k | 16k,默认4k | 16k,默认4k |
同时豆包1.6也支持的思考模式灵活配置了,可以更加节省token预算,Doubao-Seed-1.6支持三种模式:
// 开启thinking,默认设置,模型一定先思考后回答
"thinking": {"type": "enabled"
}// 关闭thinking,模型不会进行思考,直接回答问题
"thinking": {"type": "disabled"
}// 模型自适应思考,模型自主判断是否需要思考,简单题目直接回答
"thinking": {"type": "auto"
}
其中Doubao-Seed-1.6-flash (支持两种模式),不支持auto
// 开启thinking,默认设置,模型一定先思考后回答
"thinking": {"type": "enabled"
}// 关闭thinking,模型不会进行思考,直接回答问题
"thinking": {"type": "disabled"
}
关于限流与计费可以参考下面表格,我们可以看到还是比较划算的,,另外可以支持高并发请求,之前我用来标注数据发现火山TPM最抗打了。
| 项目 | Doubao-Seed-1.6-thinking | Doubao-Seed-1.6 | Doubao-Seed-1.6-flash |
|---|---|---|---|
| 默认限流(toB) | RPM:3W TPM:500W | RPM:3W TPM:500W | RPM:3W TPM:500W |
| 默认限流(内部业务) | RPM:1.2W TPM:120W | RPM:1.2W TPM:120W | RPM:1.2W TPM:120W |
| 计费 | • 方式:按token后付费 • 免费额度: 50万 token • 全新模式,待发布 | • 方式:按token后付费 • 免费额度: 50万 token • 全新模式,待发布 | • 方式:按token后付费 • 免费额度: 50万 token • 全新模式,待发布 |
下面笔者简单测试了一些能力,简直效果超出想象
- 请帮我生成一个天气页面

只能说太能写了,然后效果超级好

- 多模态理解能力测试
最近在读论文,刚好可以拿一个论文的图片来测试狭隘豆包1.6的多模态能力
我现在需要总结这两张饼图的内容。首先看左边的 (a) 图,标题是 “Distributions of RAG Paradigms”,也就是 RAG 范式的分布。里面有四个部分:Useless Doc(r0)占 20.7%,Single-Doc Support(r1)占 20.9%,Multi-Doc Support(r2)占 18.0%,还有 Single-Doc Answer(r3)?不对,等一下,左边图里的部分应该是:Useless Doc (r0) 20.7%,Multi-Doc Answer (r4) 19.2%?不对,左边图的标签是:上面蓝色的是 Multi-Doc Answer (r4) 19.2%,右边黄色的是 Single-Doc Answer (r3) 21.2%,下面粉色的是 Multi-Doc Support (r2) 18.0%,左边绿色的是 Single-Doc Support (r1) 20.9%,左上角蓝色的是 Useless Doc (r0) 20.7%。对,左边图是五个部分吗?等一下,饼图是分成五块吗?左边图的标签有五个:Useless Doc (r0) 20.7%,Multi-Doc Answer (r4) 19.2%,Single-Doc Answer (r3) 21.2%,Multi-Doc Support (r2) 18.0%,Single-Doc Support (r1) 20.9%。总和是 20.7+19.2=39.9,加 21.2 是 61.1,加 18 是 79.1,加 20.9 是 100,对,五个部分。左边图展示了不同 RAG 范式的分布情况,其中 Single-Doc Answer(单一文档回答,r3)占比最高,为 21.2%;其次是 Single-Doc Support(单一文档支持,r1)20.9% 和 Useless Doc(无用文档,r0)20.7%,三者占比相近,均在 20% 左右;Multi-Doc Answer(多文档回答,r4)占 19.2%,Multi-Doc Support(多文档支持,r2)占比最低,为 18.0%。然后看右边的 (b) 图,标题是 “Distributions of Data Sources”,即数据来源的分布。里面有五个部分:ShareGPT_V3 占 19.3%,SlimOcar 占 25.0%,Lmsys-Chat-1M 占 24.1%,WizardLM 占 17.0%,GPT4-Alpaca 占 14.6%。右边图的分布是:SlimOcar 占比最高,为 25.0%;其次是 Lmsys-Chat-1M,占 24.1%,两者合计接近 50%;接下来是 ShareGPT_V3 占 19.3%,WizardLM 占 17.0%,GPT4-Alpaca 占比最低,为 14.6%。总结的时候需要分别说明两张图的主题、各部分的占比情况以及主要结论(比如占比最高的部分,各部分的分布特点)。
上面是思考过程,我们看到也是非常正确,不管是文字识别还是数字提取,对图片内容理解非常正确

总结图片内容

火山方舟 MCP
官方地址:https://www.volcengine.com/mcp-marketplace
火山引擎MCP Hub,集成了丰富的官方云服务及优质三方生态工具。支持用户快速跳转至 火山方舟 或 其他支持 MCP 协议的平台(如 Trae、Cursor、Python 等),支持Remote MCP,Local MCP 部署方式。同时,通过打通大模型应用开发环境 Trae+火山方舟模型服务+MCP Market,火山提供一站式端到端的大模型落地应用解决方案。
- 优势参考:
MCP作为大模型领域的开源工具协议,主要解决Agent开发的三个问题:- 链接Agent 开发:目前完成与Al编程工具Trae打通,并且支持方舟、扣子等火山应用构建体系
- 链接云服务:agent开发完,需要在云的计算、网络、存储等环境部署,通过MCP可以一键拉起相关云产品,打通开发到部署的最后一公里
- 链接大模型工具生态:gent开发依赖大量工具,如通信、财经、地理信息等工具,火山mcp提供了全栈的生态工具
我们可以在火山方舟极速体验模型与MCP结合的效果:
访问地址:https://www.volcengine.com/experience/ark?model=doubao-seed-1-6-thinking-250615
点击对话框中的MCP按钮,我们可以配置已有MCP能力

比如我们这里开启了飞常准的MCP,我们测试下效果
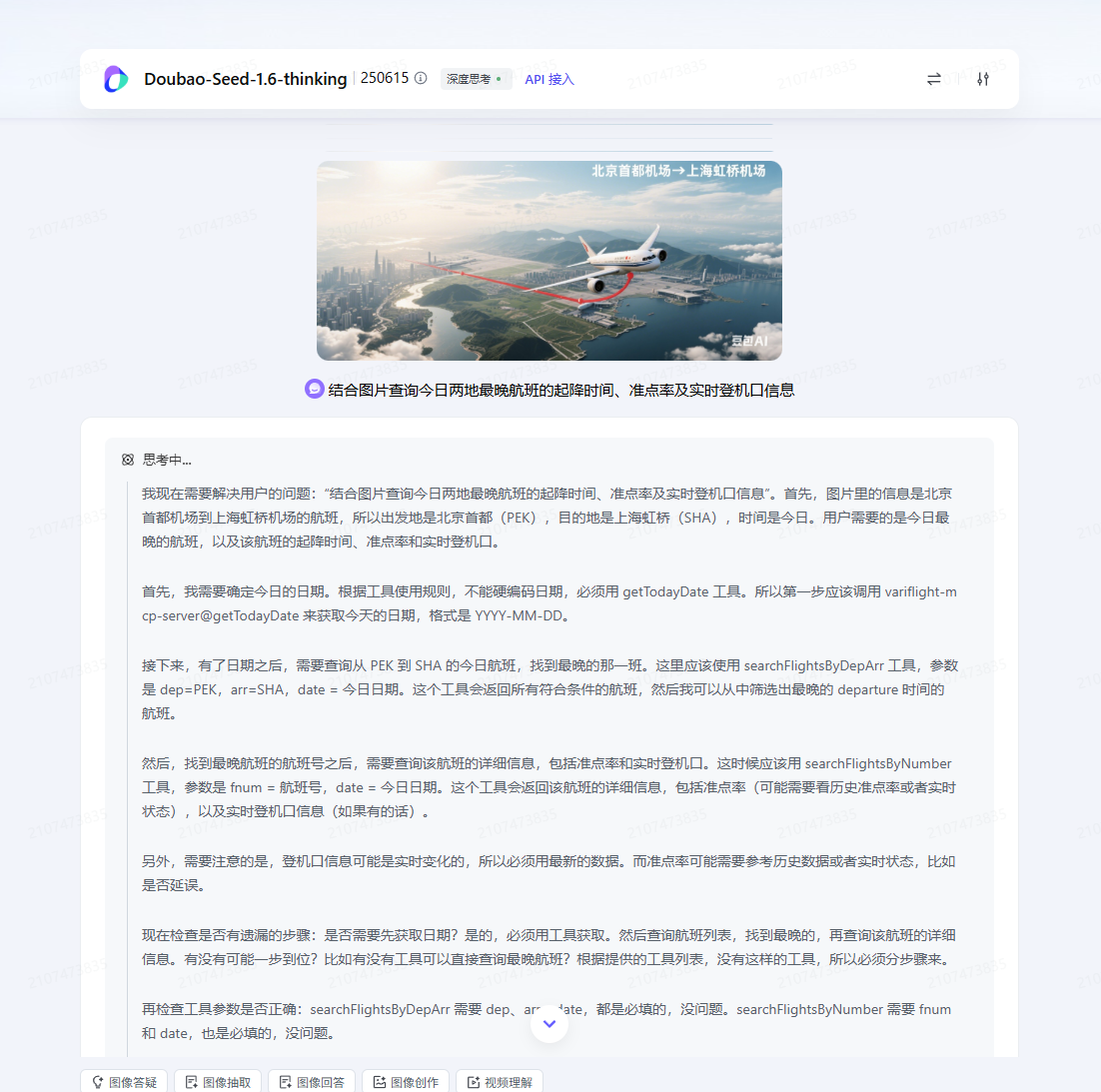
通过调用MCP然后获取航班信息,给出的航班信息如下,这个能力体验还是不错的,大家可以尝试更多MCP效果

基于豆包1.6大模型构建Arxiv论文阅读智能体
下面我们通过Trae编辑器来实现论文阅读MCP集成以及智能体构建
我们将下面代码粘贴到MCP配置中
{"mcpServers": {"arxiv-mcp-server": {"command": "uv","args": ["--directory","g:\\Projects\\arxiv-mcp-server","run","arxiv-mcp-server","--storage-path","C:\\path\\to\\paper\\storage"]}}
}
正常确认之后,我们可以看到MCP的运行状态

上面绿色对号代表正常运行了
在构建好Paper Reading 的MCP之后,我们可以继续配置智能体,将构建好的MCP集成到智能体对话能力中

然后我们对话框中加入智能体
这里提一下火山方舟的PromptPilot,可以快速帮我们构造和优化提示语,提升开发效率

PromptPilot 通过交互式引导与提示词优化,帮助开发者将模糊需求转化为精准指令
- 平台能力:火山方舟Prompt Pilot是一款面向大模型应用落地的使能平台,覆盖从Prompt构建这一基础环节出发,通过用户反馈与数据驱动机制,精准识别和表达用户任务意图,自动生成解决方案,并实现线上Badcase检测与运行时持续优化,构建起一条贯通大模型应用落地全过程的闭环链路。
- 平台功能:Prompt Pilot提供了Prompt工程(包括Prompt生成、调试、智能优化、版本管理等),AI工程(包括知识加工、问题工程、答案工程、thought工程、metric工程、tools工程等),联动精调,Solution Out,任务定制的评估服务等功能,并提供具有probe/反馈等功能的sdk与线上环境形成联动,持续检测/回流线上badcase,助力大模型应用的持续优化。
这里我们通过火山方舟Prompt Pilot优化一下Arxiv论文解读的提示语

体验网址:https://promptpilot.volcengine.com/startup
大家也可以尝试下效果,写prompt的效率太高了!
下面我们尝试下效果:
请帮我解读下这个论文:FedRAG: A Framework for Fine-Tuning Retrieval-Augmented Generation Systems,
论文链接为:https://www.arxiv.org/abs/2506.09200

我们可以看到MCP有执行论文搜索,论文下载以及论文解读的过程,下面是正在下载论文
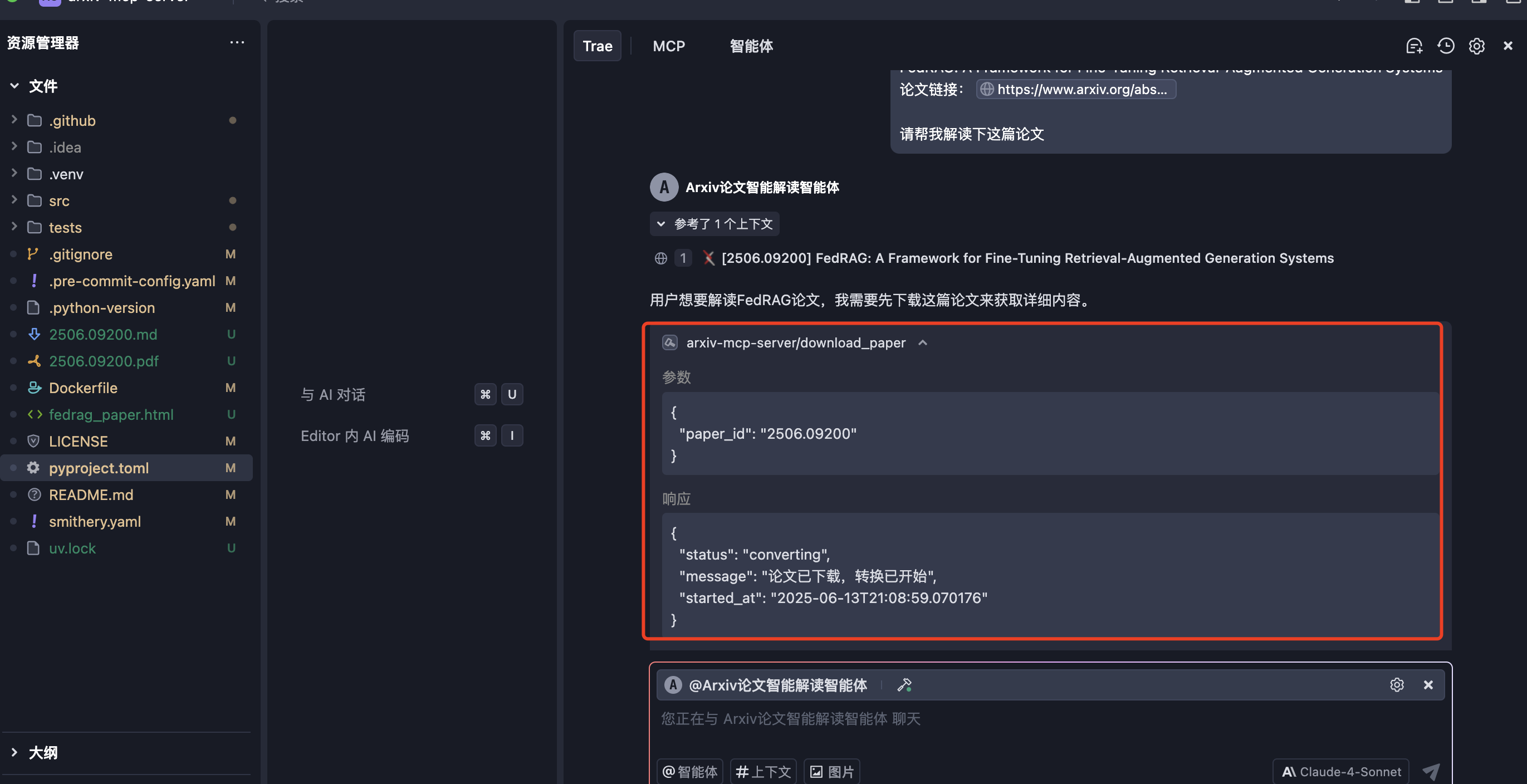
下一步是对论文内容进行转换

这个解读效率还是比较高的

这里提一下veFaaS官方推出的 MCP server,自然语言的方式驱动Serverless应用的开发、部署、上线流程,适用于 Serverless 服务的运维排障
我们通过添加veFass mcp,将论文解读内容部署发布成一个网页
官方介绍地址:https://www.volcengine.com/mcp-marketplace/detail?name=veFaaS%20MCP
{"mcpServers": {"mcp_server_vefaas_function": {"url": "替换成自己的内容"}}
}

然后将json内容粘贴到MCP配置输入框中

我们接续在聊天框中输入指令,将论文解读内容发布成一个网页:
请帮我把这个网页发布到veFass,给我返回可以访问的地址

最后可以点开返回地址,查看网页

结语
火山引擎AI云原生的核心在于打造了全新的Agent开发范式:“模型能力 × AI开发平台”,通过强大的模型底座与智能化开发工具的深度融合,为开发者提供端到端的AI应用构建解决方案。
在模型层面,豆包大模型1.6系列展现出卓越的综合能力。其中,Doubao-Seed-1.6-thinking在深度思考方面实现突破性提升,在编程、数学、逻辑推理等核心能力上全面增强,并新增视觉理解能力;Doubao-Seed-1.6作为能力多面手,独创性地支持thinking/non-thinking/自适应思考三种模式,既保证了推理质量,又大幅降低了token成本,特别针对前端编程能力进行了专项优化;而Doubao-Seed-1.6-flash则以10ms的极致推理速度,在保持高质量多模态理解的同时,为实时应用场景提供了强有力支撑。
在平台工具层面,火山引擎构建了完整的智能化开发生态。火山方舟PromptPilot通过交互式引导与智能优化机制,帮助开发者将模糊的业务需求精准转化为高效的模型指令,显著提升了Prompt工程的效率与质量。更为重要的是,火山方舟通过MCP(Model Context Protocol)协议实现了开发与部署的无缝衔接,开发者可以直接调用云服务资源,彻底解决了传统AI应用从开发到生产环境部署的"最后一公里"问题。
这种"模型+平台"的创新架构,不仅降低了AI应用开发的技术门槛,更是为企业级AI应用的规模化落地提供了完整的解决方案,真正实现了从想法到产品的快速迭代与部署。