中国建设银行官网站纪念币预约微商引流的最快方法是什么
文章目录
- 1.翻转链表
- 2.链表内指定区间翻转
- 3. 链表中的节点每k个一组翻转
- 4. 合并两个排序的链表
- 5. 合并k个排序的链表
- 6. 判断链表是否有环
- 7. 链表中倒数第k个节点
- 8. 删除链表中的倒数第k和节点
- 9. 两个链表的第一个公共节点
- 10.链表的入环节点
- 11. 链表相加(二)
- 12. 单链表排序
- 13.判断一个链表是否是回文结构
- 14. 链表的奇偶重排
- 15.删除有序链表中重复的元素I
- 16.删除有序链表中重复的元素||
1.翻转链表

❤️❤️ 算法思路: 设置一个指针pre,这个pre指向的是工作节点也就是在链表中挨个遍历的cur的前一个节点,初始的时候设置pre指向为null,因为要翻转链表,链表中的最后一个节点指向为null。逐个遍历链表中的每一个节点,每次遍历节点的前一个节点。curNext = cur.next 然后节点指定翻转当前节点指向前一个节点 cur.next = pre,然后更新pre的指向,指向为cur 即 pre = cur 然后工作节点cur 继续遍历链表的后续节点。
//翻转链表
public Node reverse(Node head){if(head == null || head.next == null){return head;}Node cur = head;Node curNext = null;Node pre = null;while (cur != null){//记录当前节点的后置节点curNext = cur.next;//当前节点的next指针指向前置节点,那么此时就实现了一个节点的翻转cur.next = pre;//前置节点指向更新pre = cur;//当前节点继续遍历cur = curNext;}//.最后cur 为空,pre是cur 的前置节点,那么此时的pre就是翻转后链表的头节点return pre;
}
2.链表内指定区间翻转

❤️❤️ 算法思路: 其实就是翻转链表的一个变种,翻转链表的一部分,找到翻转链表的头节点和尾节点,还有就是翻转链表头节点的前一个节点和翻转链表的最后一个节点的后一个节点。把部分链表翻转之后,进行拼接。

//翻转链表中的一部分
public Node reverseSub(Node head,int m,int n){if(head == null || head.next == null || m == n){return head;}Node dummy = new Node(-1);dummy.next = head;Node pre = dummy;//得到翻转链表的头节点的前一个节点for(int i = 0;i < m - 1;i++){pre = pre.next;}//翻转链表的最后一个节点Node rightNode = pre;for(int i = 0; i < n - m + 1;i++){rightNode = rightNode.next;}//翻转链表的头节点Node leftNode = pre.next;pre.next = null;System.out.println(rightNode.val);Node curNext = rightNode.next;rightNode.next = null;reverse(leftNode);pre.next = rightNode;leftNode.next = curNext;return dummy.next;
}
3. 链表中的节点每k个一组翻转

❤️❤️ 算法思路: 因为要翻转链表,那么我们可以联想到使用栈,栈是先进后出的,那么此时我们把节点添加到栈中,等到栈中添了k个节点之后,然后我们把这些节点依次从栈中取出来并且连接每个节点,那么这就反转了一组链表片段。如果在遍历链表的时候,如果这一组不够k个,那么我们就直接把剩下的几个节点添加到反转链表的末尾即可

public Node kCountsReverse(Node head,int k){if(head == null || head.next == null) {return head;}//使用栈,把链表中的节点压到栈中,进栈的时候,一边计数,如果此时的这个计数的结果等于k 那么就退出,把栈中的节点弹出来//并且连接在一起。如果不够k个一组,那么就直接拼到翻转链表的后面Stack<Node> stack = new Stack<>();Node dummy = new Node(-1);Node p = dummy; //添加后续节点while(true){int count = 0;Node cur = head;while(cur != null && count != k){stack.push(cur);count++;cur = cur.next;}//如果不构成一组,但是此时cur == nullif(count != k){//直接拼接p.next = head;break;}while(!stack.empty()){p.next = stack.pop();p = p.next;}p.next = cur;head = cur;}return dummy.next;
}
4. 合并两个排序的链表

❤️❤️ 算法思路: 首先判定先决条件如果在待排序的链表中,有一个链表为空,那么就直接返回另一个链表,如果两个链表都为空,那么就直接输出null。如果两个链表都不为空,那么就进行排序,设置一个虚拟节点dummy,然后设置一个连接链表的指针p,这个指针p用来遍历整个链表,起先这个指针p指向节点dummy.

public Node sort(Node head1,Node head2){if(head1 == null && head2 == null){return null;}if(head1 == null){return head2;}if(head2 == null){return head1;}Node dummy = new Node(-1);Node p = dummy;Node cur1 = head1;Node cur2 = head2;while(cur1 != null && cur2 != null){if(cur1.val <= cur2.val){p.next = cur1;cur1 = cur1.next;}else{p.next = cur2;cur2 = cur2.next;}p = p.next;}if(cur1 != null){p.next = cur1;}if(cur2 != null){p.next = cur2;}return dummy.next;
}
5. 合并k个排序的链表
两种方法,方法一使用归并排序,方法二:使用堆

❤️❤️算法思路方法一:使用归并排序思想,根据归并排序思想,我们把这k个链表一直分,一直分,分到 这个组合有两个链表,我们两个链表进行合并,然后再返回排序好的链表。总的来说就是先分后合。这里我们可以把每个链表看成一个元素,就是list之间进行分治然后在合并

public Node func(List<Node> list){if(list == null){return null;}return process(list,0,list.size() - 1);
}
public Node process(List<Node> list,int left,int right){if(left > right){return null;}else if(left == right){return list.get(left);}int mid = (left + right) >> 1; Node head1 = process(list,left,mid);Node head2 = process(list,mid + 1,right);//调用上面我们写的排序两个已经排序好的链表中的那个题目的代码return sort(head1,head2);
}
❤️❤️**算法思路方法二:**使用优先队列。其实我们在题目中可以不进行指定创建出来的queue对象是小顶堆,其实创建出来的queue对象默认就是一个小顶堆。就是把这k个链表的头节点,都加到小顶堆中,让每个链表的头节点进行比较,在小顶堆中,值域较小的节点就在堆顶,然后我们创建出一个虚拟节点,用于来连接排序好的链表,还有设置指针p.如果小顶堆不为空,那么就的弹出小顶堆的堆顶元素,并且保存堆顶元素,使用指针p 连接弹出的这个节点,然后判断弹出的这个节点有没有后继节点,如果有就添加到小顶堆中。继续使用小顶堆,找出最小的节点,使用p指针,继续拼接

public Node func2(List<Node> list){if(list == null){return null;}PriorityQueue<Node> queue = new PriorityQueue<>((v1,v2)->(v1.val - v2.val));//把每个链表的头节点都加到小跟堆中for(int i = 0;i < list.size();i++){//如果k个链表中的头节点,不为空,那么就把这个节点添加到小跟堆中if(list.get(i) != null){queue.offer(list.get(i));}}Node dummy = new Node(-1);Node p = dummy;while(!queue.isEmpty()){//如果此时的小跟堆不为空,那么此时就弹出堆中最小的元素,也就是堆顶元素Node node = queue.poll();p.next = node;p = p.next;//如果堆顶元素在链表中还有下一个节点,那么就把下一个节点添加到小顶堆中,继续下一次比较if(node.next != null){queue.offer(node.next);}}return dummy.next;
}
6. 判断链表是否有环

❤️❤️算法思路: 其实这是一个非常经典的面试题,这个题目考察的是快慢指针,起初让快慢指针同时位于链表的头节点,然后遍历链表,让慢指针一次遍历一个节点,让快指针一次遍历两个节点(跳跃两个节点),如果是环形链表,那么此时的快指针和慢指针一定会在某一个位置相遇
public boolean isCycle(Node head){if(head == null){return false;}if(head.next == null) {return true;}Node slow = head;Node fast = head;while(fast.next != null && fast.next.next != null){slow = slow.next;fast = fast.next.next;if(slow == fast){return true; }}return false;
}
7. 链表中倒数第k个节点

❤️❤️算法思想: 设置两个指针,一个是快指针,一个是慢指针,先让快指针遍历k步,那么此时的慢指针和快指针之间就相差k个节点,那么此时让慢指针和快指针一块遍历链表,一次遍历一个节点,直到快指针指向的节点为null,那么此时的慢指针就指向了链表的倒数第k个节点
ublic Node func2(Node head,int k){//设置一个指针,先让这个快指针走k步,然后设置一个慢指针,快指针和慢指针一块走,知道快指针遍历到了null节点,//那么此时就找到了链表的倒数第k个节点Node slow = head;Node fast = head;int count = 0;while(count != k){if(fast != null){count++;fast = fast.next;}else{return null;}}while(fast != null){slow = slow.next;fast = fast.next;}return slow;
}
8. 删除链表中的倒数第k和节点

❤️❤️算法思路: 首先我们要设置一个虚拟节点,然后让这个虚拟节点的next指针指向头结点,因为在题目中有可能删除头结点。然后我们和上题是一样的设置两个指针,一个快指针,一个慢指针,快指针先遍历k步,因为我们最终要找到的是删除节点的前一个节点,然后让这前一个节点的next指针指向删除节点的后一个节点。所以此时我们的循环条件就由原来的fast != null 变成了 fast.next != null 这样快指针和慢指针一次走一步,然后直到fast.next == null 那么我们此时就找到了链表的倒数第k + 1 个节点,就是删除节点的前一个节点,然后它的next指针指向删除节点的后一个节点。

public Node func3(Node head,int k){if(head == null){return null;}Node dummy = new Node(-1);dummy.next = head;Node slow = dummy;Node fast = dummy;for(int i = 0;i < k;i++){fast = fast.next;}while(fast.next != null){slow = slow.next;fast = fast.next;}slow.next = slow.next.next;return dummy.next;
}
9. 两个链表的第一个公共节点

❤️❤️ 算法思路: 首先得到两个链表的长度,让长的链表减去短的链表的长度,得到的差值,让长链表走差值步,然后两个链表中的指着一步一个走,知道两个链表的节点重合
public Node func4(Node head1,Node head2){if(head1 == null || head2 == null){return null;}int count1 = getCount(head1);int count2 = getCount(head2);int num = Math.abs(count1 - count2);if(count1 > count2){while(num != 0){head1 = head1.next;num--;}}else{while(num != 0){head2 = head2.next;num--;}}while(head1 != head2){head1 = head1.next;head2 = head2.next;}return head1;
}
10.链表的入环节点


❤️❤️算法思想: 首先判断链表是否有环,如果链表是无环的,那么就不存在这个链表的入环节点,然后就是当快指针和慢指针走到一块的时候,此时就记住这个节点,然后让慢指针指向链表的头部,然后两个指针一块走,直到两个指针相遇。
public Node getCycle(Node head){Node slow = head;Node fast = head;while(fast.next != null && fast.next.next != null){slow = slow.next;fast = fast.next.next;if(slow == fast){return slow;}}return null;
}
public Node cycleNode(Node head){if(head == null || head.next == null){return null;}Node fast = getCycle(head);if(fast == null){return null;}Node slow = head;while(slow != fast){slow = slow.next;fast = fast.next;}return slow;
}
11. 链表相加(二)

❤️❤️算法思想: 其实就相当于是两个数字在相加,数字在相加的时候,是从个位开始相加的,那么我们此时只有把链表翻转之后,才能相加,并且在相加的时候要注意进位,相加完之后,得到翻转的结果之后,把链表进行翻转
public Node getSum(Node head1,Node head2){if(head1 == null && head2 == null){return null;}if(head1 == null){return head2;}if(head2 == null){return head1;}int carry = 0;//翻转链表Node newHead1 = reverse(head1);Node newHead2 = reverse(head2);Node dummy = new Node(-1);Node p = dummy;while(newHead1 != null || newHead2 != null){int sum = (newHead1 == null ? 0 : newHead1 .val) + (newHead2 == null ? 0 : newHead2.val) + carry;carry = sum >= 10 ? sum / 10 : 0;sum = sum >= 10 ? sum % 10 : sum;Node node = new Node(sum);p.next = node;p = p.next;newHead1 = newHead1 == null ? null : newHead1.next;newHead2 = newHead2 == null ? null : newHead2.next;}if(carry != 0){p.next = new Node(carry);}return reverse(dummy.next);
}
12. 单链表排序

❤️❤️算法思想: 其实这个题还是很简单的,我们可以改成归并排序,其实这个归并排序思想就是把链表从中间分开,每次都进行分,知道把链表分成单个的节点,然后在里用两个有序链表构成一个新的有序的大链表就行了。这个就是典型的归并排序。
public class Solution {/*** * @param head ListNode类 the head node* @return ListNode类*/public ListNode sortInList (ListNode head) {//保证时间复杂度为O(n * logn)if(head == null || head.next == null){return head;}//每次都断开中间节点ListNode temp = getMid(head);ListNode head1 = sortInList(head);ListNode head2 = sortInList(temp);return marge(head1,head2);}private ListNode marge(ListNode head1, ListNode head2) {ListNode dummy = new ListNode(-1);ListNode p = dummy;while(head1 != null && head2 != null){if(head1.val <= head2.val){p.next = head1;head1 = head1.next;} else{p.next = head2;head2 = head2.next;}p = p.next;}if(head1 != null){p.next = head1;}if(head2 != null){p.next = head2;}return dummy.next;}private ListNode getMid(ListNode head) {ListNode slow = head;ListNode fast = head;while(fast.next != null && fast.next.next != null){slow = slow.next;fast = fast.next.next;}ListNode temp = slow.next;slow.next = null;return temp;}
}
13.判断一个链表是否是回文结构

❤️❤️算法思想:找到链表的中间节点,把中间节点之后的链表节点全部翻转,然后让一个指针指向链表的头节点,让一个指针指向翻转链表的头节点,然后两个指针一个向右遍历,一个向左遍历,在遍历的过程中判断,节点中的val值是否是相同的。
public class Solution {/**** @param head ListNode类 the head* @return bool布尔型*/private ListNode getMid(ListNode head) {ListNode slow = head;ListNode fast = head;while(fast.next != null && fast.next.next != null){slow = slow.next;fast = fast.next.next;}return slow;}//方法二翻转部分链表public boolean isPail (ListNode head) {if(head == null){return false;}//找到链表的中间节点ListNode preNewHead = getMid(head);ListNode newHead = preNewHead.next;preNewHead.next = null;ListNode cur = reverse(newHead);while(head != null && cur != null){if(head.val != cur.val){return false;}head = head.next;cur = cur.next;}return true;}private ListNode reverse(ListNode head) {ListNode pre = null;ListNode cur = head;while(cur != null){ListNode curNext = cur.next;cur.next = pre;pre = cur;cur = curNext;}return pre;}
}14. 链表的奇偶重排

❤️❤️算法思想: 首先呢,这是一种笨办法,我们把原链表中所有的全部节点添加到栈中,并且把每个节点之前的连接断开,在栈中添加节点的时候我们还要进行奇数,要知道在栈中得到了多少个节点,然后设置两个虚拟节点和两个遍历指针p1,p2,然后我们把栈中的节点弹出来根据此时的count判断此时这个是偶数位节点和时奇数位节点,然后拼好两个链表,然后把两个链表进行翻转,然后两个链表拼接。
public static Node func2(Node head){Stack<Node> stack = new Stack<>();Node dummy1 = new Node(-1);Node p1 = dummy1;Node dummy2 = new Node(-2);Node p2 = dummy2;Node cur = head;int count = 0;while(cur != null){Node curNext = cur.next;cur.next = null;stack.push(cur);count++;cur = curNext;}while(count != 0){//奇数if(count % 2 == 1){p1.next = stack.pop();p1 = p1.next;}else{//偶数p2.next = stack.pop();p2 = p2.next;}count--;}//因为此时的两个链表是有栈得到的,那么此时它们的排列顺序是不对的,那么此时我们把这两个链表进行翻转Node node1 = reverse(dummy1.next);Node node2 = reverse(dummy2.next);Node ret = node1;while(node1.next != null){node1 = node1.next;}//得到奇数链表的最后一个节点,和偶数链表的最后一个节点相连node1.next = node2;return ret;
}
15.删除有序链表中重复的元素I

❤️❤️算法思想:先判断该链表是不是一个空链表,如果是空链表,那么就直接返回null,如果该链表只有一个节点,那么就直接返回head。因为要删除相同的节点,并且保留重复节点中的一个节点,那现在就比如说,此时有 cur,cur.next这个两个指针指向的节点,这两个节点的值域中的val是一样的,那么此时我们就保留cur这个位置上的节点,删除cur.next这个指针指向的节点。判断当前节点和当前节点的下一个节点相同,那么此时我们就不在返回的链表上添加这个节点。
图示:

import java.util.*;
public class Solution {public ListNode deleteDuplicates (ListNode head) {//如果此时的头节点为空,或者是此时只有一个节点if(head == null || head.next == null){return head;}//设置虚拟节点,因为在删除元素的时候,可能会对于头节点有影响ListNode dummy = new ListNode(-1);ListNode p = dummy;ListNode cur = head;while(cur != null){//如果在遍历的时候遇到了相同的节点,那么此时就一直遍历,不在返回链表中插入新的节点if(cur.next != null && cur.val == cur.next.val){while(cur.next != null && cur.val == cur.next.val){cur = cur.next;}}p.next = cur;cur = cur.next;p = p.next;}//dummy.next表示的是返回链表的头节点return dummy.next;}
}
16.删除有序链表中重复的元素||

❤️❤️算法思想:其实这道题是上一道题的一个延伸,就是把链表中重复的的节点都删除了。那么此时我们就把预先设置的虚拟节点,看做为要返回链表的头节点,令工作节点cur = dummy 判断cur.next 和 cur.next.next是不是相同的节点,然后记录一下这两个节点的值,在判断cur.next.next之后有没有相同的节点,如果有cur.next = cur.next.next.
图示:
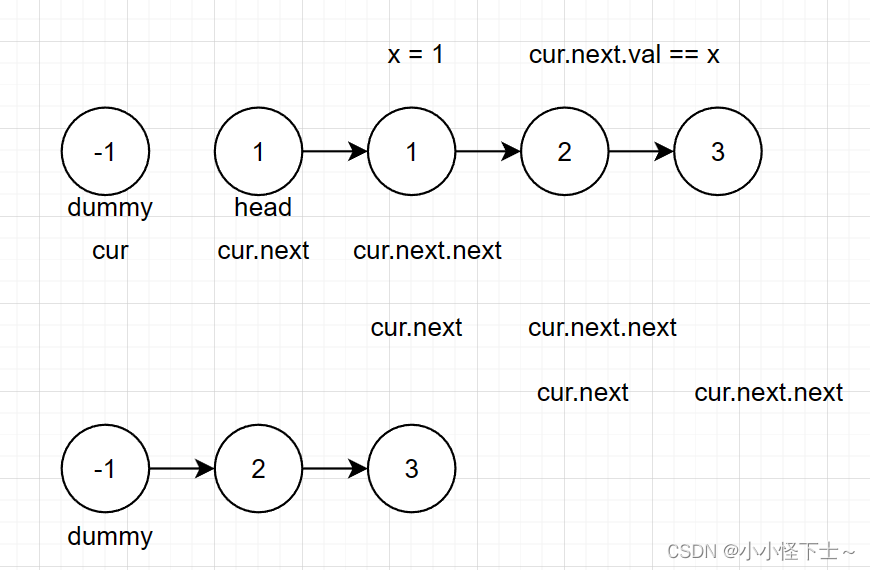
import java.util.*;
public class Solution {public ListNode deleteDuplicates (ListNode head) {if(head == null || head.next == null){return head;}ListNode dummy = new ListNode(-1);ListNode cur = dummy;dummy.next = head;while(cur.next != null && cur.next.next != null){if(cur.next.val == cur.next.next.val){int x = cur.next.val;while(cur.next != null && cur.next.val == x){cur.next = cur.next.next;}}else{cur = cur.next;}}return dummy.next;}
}