做苗木的哪个网站效果好搜索引擎有哪些平台
文章目录
- python爬虫 -爬取微博热搜数据
- 1. 第一步:安装requests库和BeautifulSoup库
- 2. 第二步:获取爬虫所需的header和cookie
- 3. 第三步:获取网页
- 4. 第四步:解析网页
- 5. 第五步:分析得到的信息,简化地址
- 6. 第六步:爬取内容,清洗数据
- 7. 爬取微博热搜的代码实例以及结果展示
python爬虫 -爬取微博热搜数据
python爬虫六部曲:
-
第一步:安装requests库和BeautifulSoup库
-
第二步:获取爬虫所需的header和cookie
-
第三步:获取网页
-
第四步:解析网页
-
第五步:分析得到的信息,简化地址:
-
第六步:爬取内容,清洗数据
1. 第一步:安装requests库和BeautifulSoup库
在程序中引用两个库的书写是这样的:
import requests
from bs4 import BeautifulSoup
以pycharm为例,在pycharm上安装这两个库的方法。在菜单【文件】–>【设置】->【项目】–>【Python解释器】中,在所选框中,点击软件包上的+号就可以进行查询插件安装了。有过编译器插件安装的hxd估计会比较好入手。具体情况就如下图所示。
2. 第二步:获取爬虫所需的header和cookie
以爬取微博热搜的爬虫程序为例。获取header和cookie是一个爬虫程序必须的,它直接决定了爬虫程序能不能准确的找到网页位置进行爬取。
- 首先进入微博热搜的页面,按下F12,就会出现网页的js语言设计部分,找到网页上的Network部分。如下图所示:
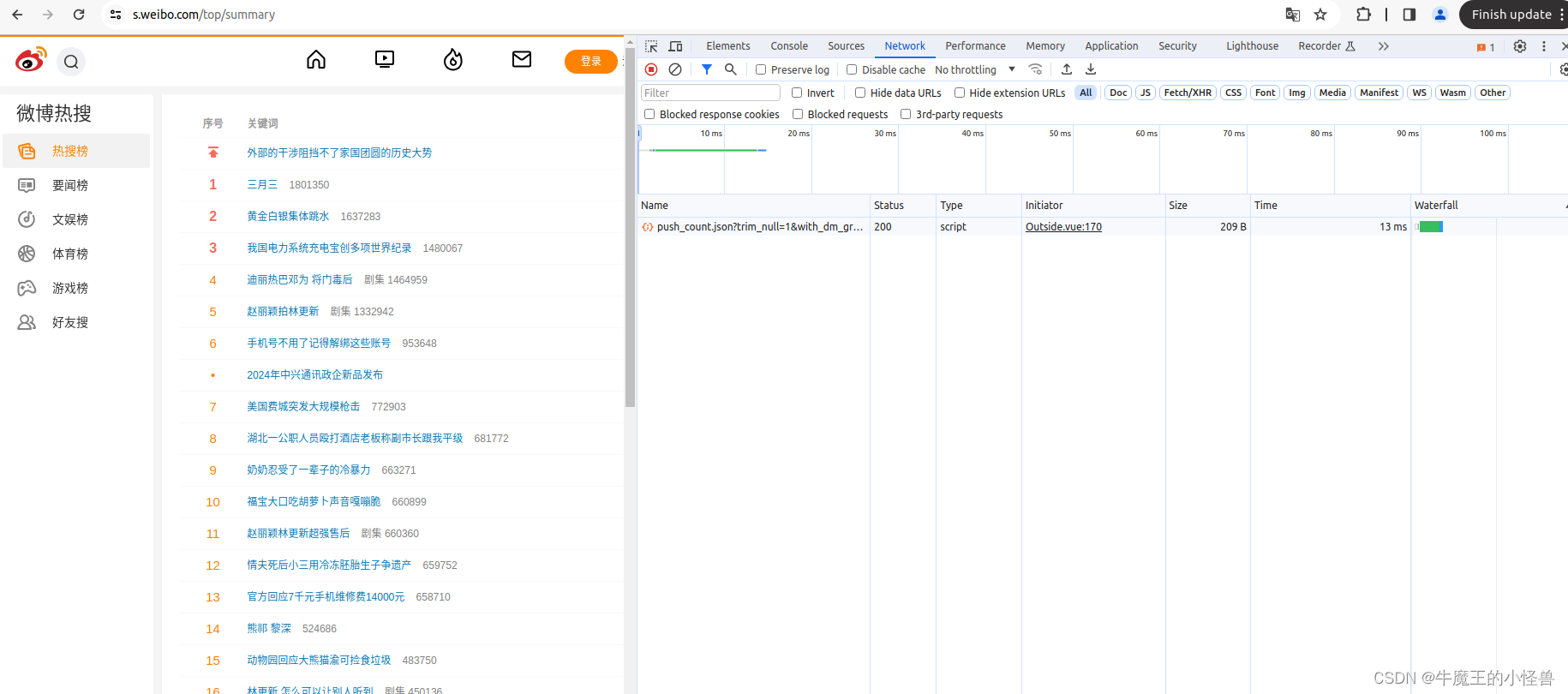
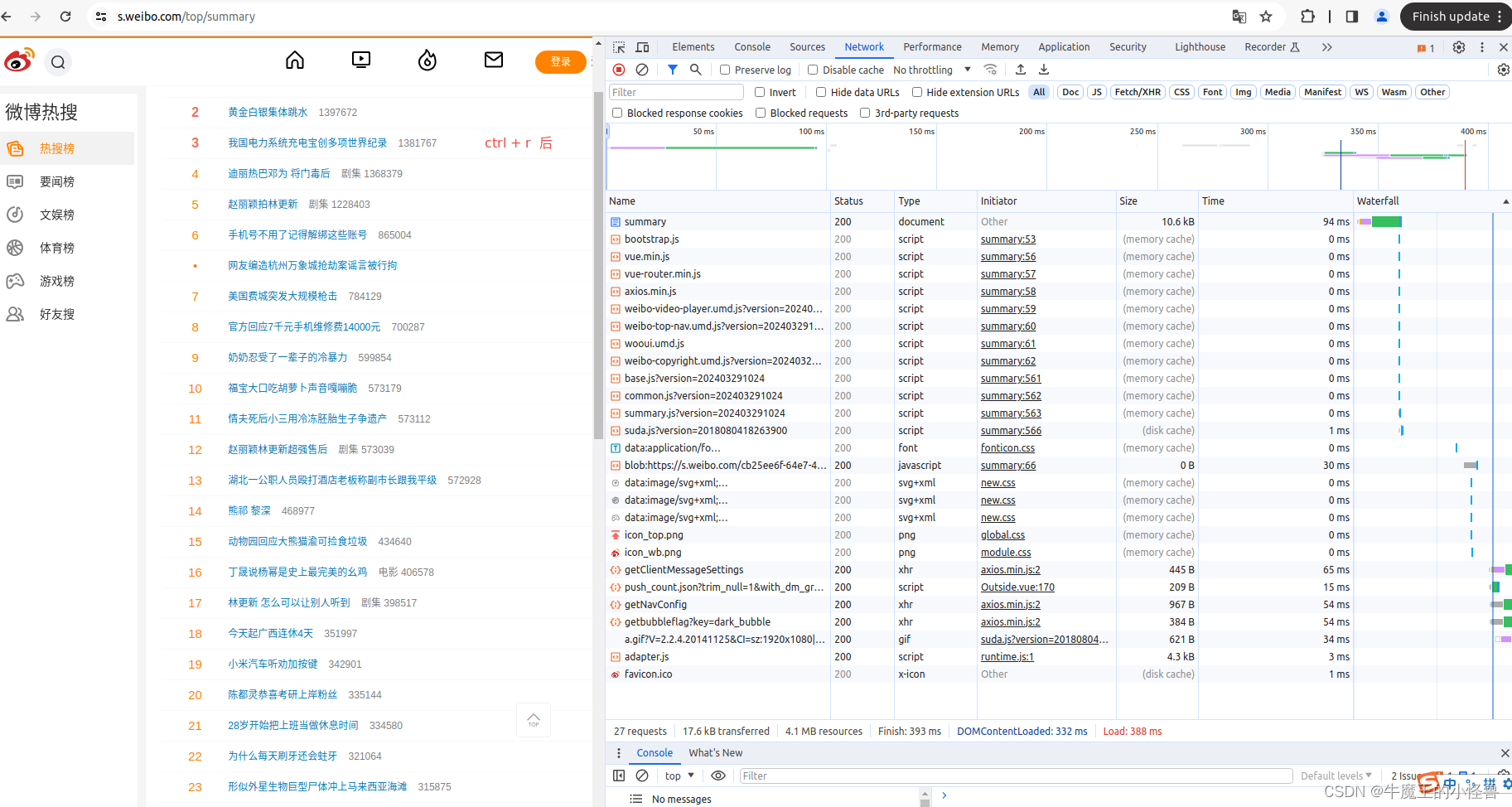
- 然后按下ctrl+R刷新页面,此时法线右边 NetWork 部分出现很多信息。
(如果进入后就有所需要的信息,就不用刷新了),当然刷新了也没啥问题。
-
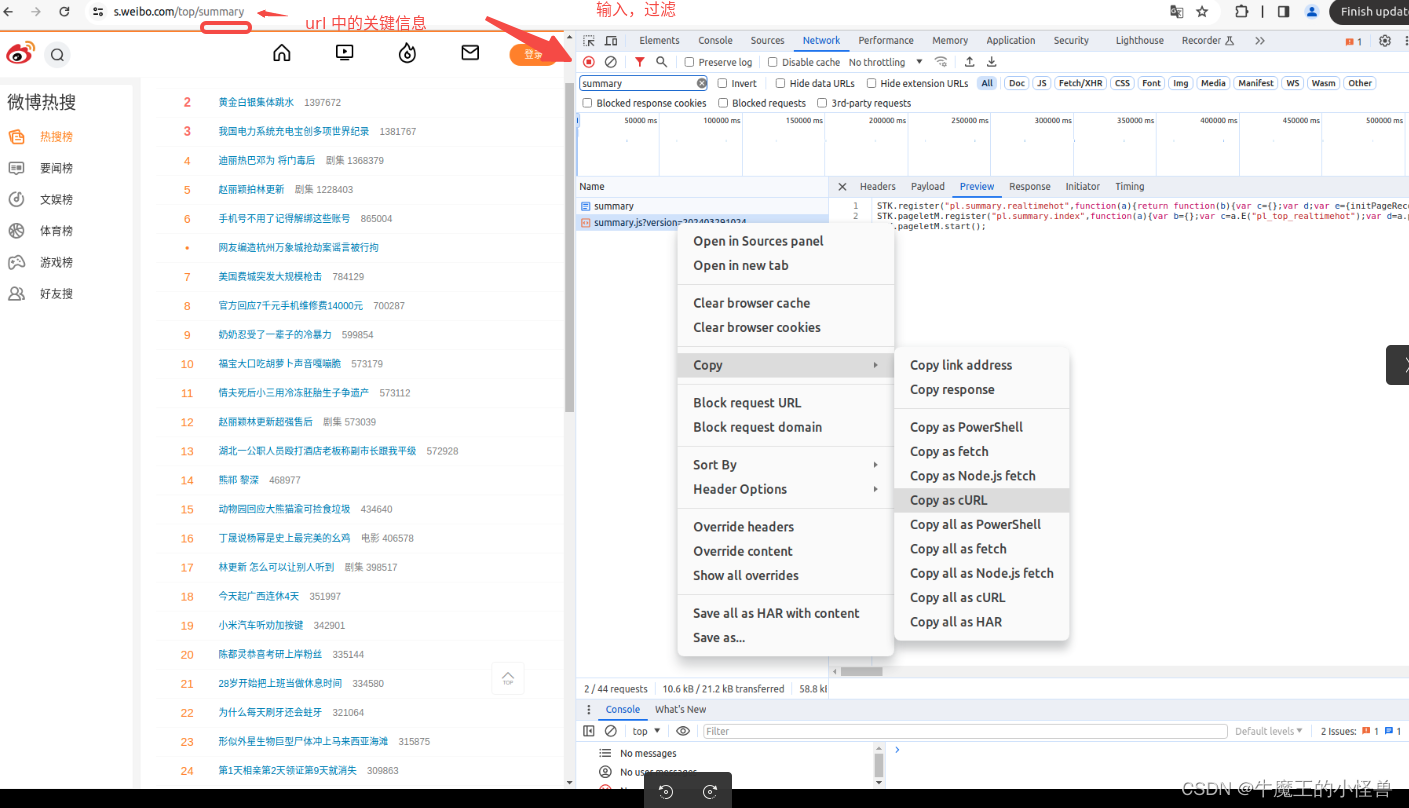
过滤网络信息,并拷贝其 cURL 信息 ,
在 Network --> Filter 中,依据网址(https://s.weibo.com/top/summary)中的关键信息进行过滤,如: summary。 然后,我们浏览Name这部分,找到我们想要爬取的文件(网络信息),鼠标右键,选择copy,复制下网页的URL。过滤后,有效信息会少很多,如下所示。选中所需的条目,右键 --> Copy --> Copy as cURL
- 利用工具 Convert curl commands to code https://curlconverter.com/python/ 进行转换
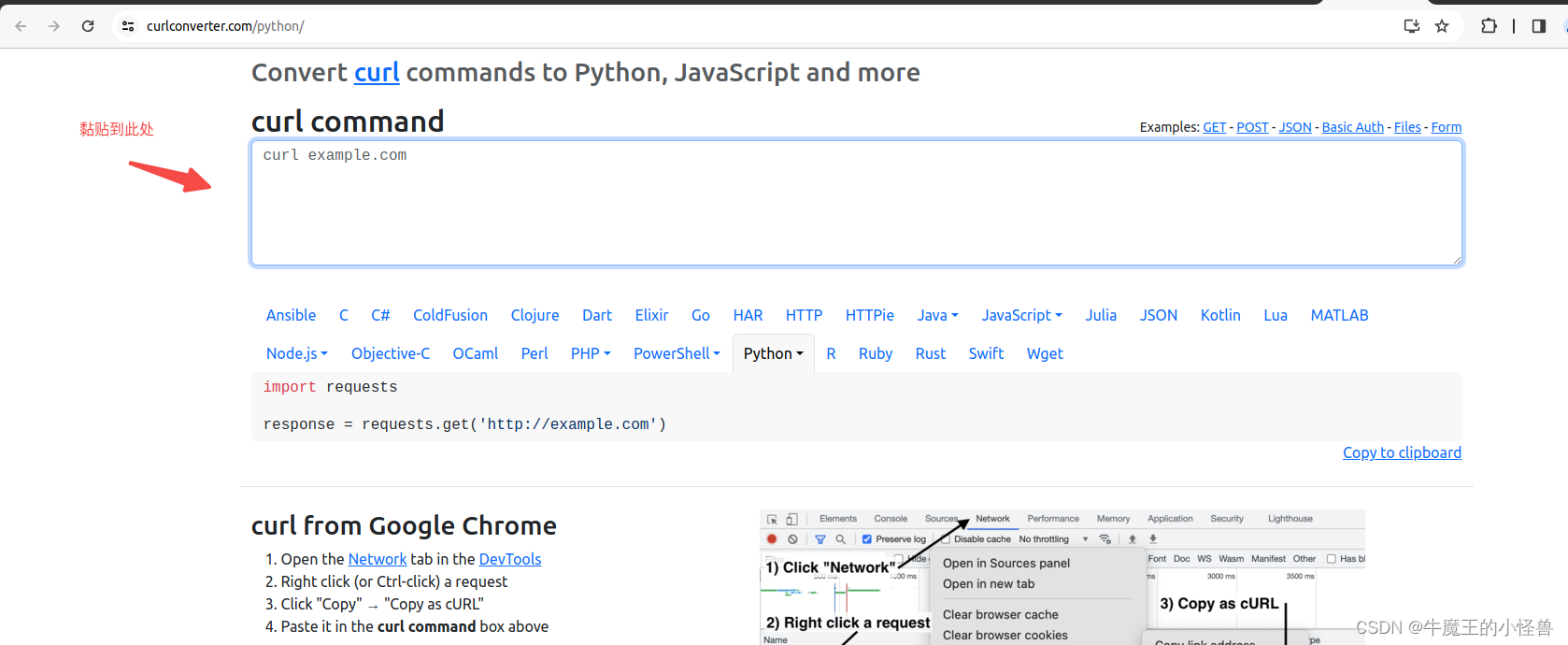
转换后信息如下图所示,选择【Copy to clipboard】,并黏贴到Pycharm开发环境中即可直接使用:
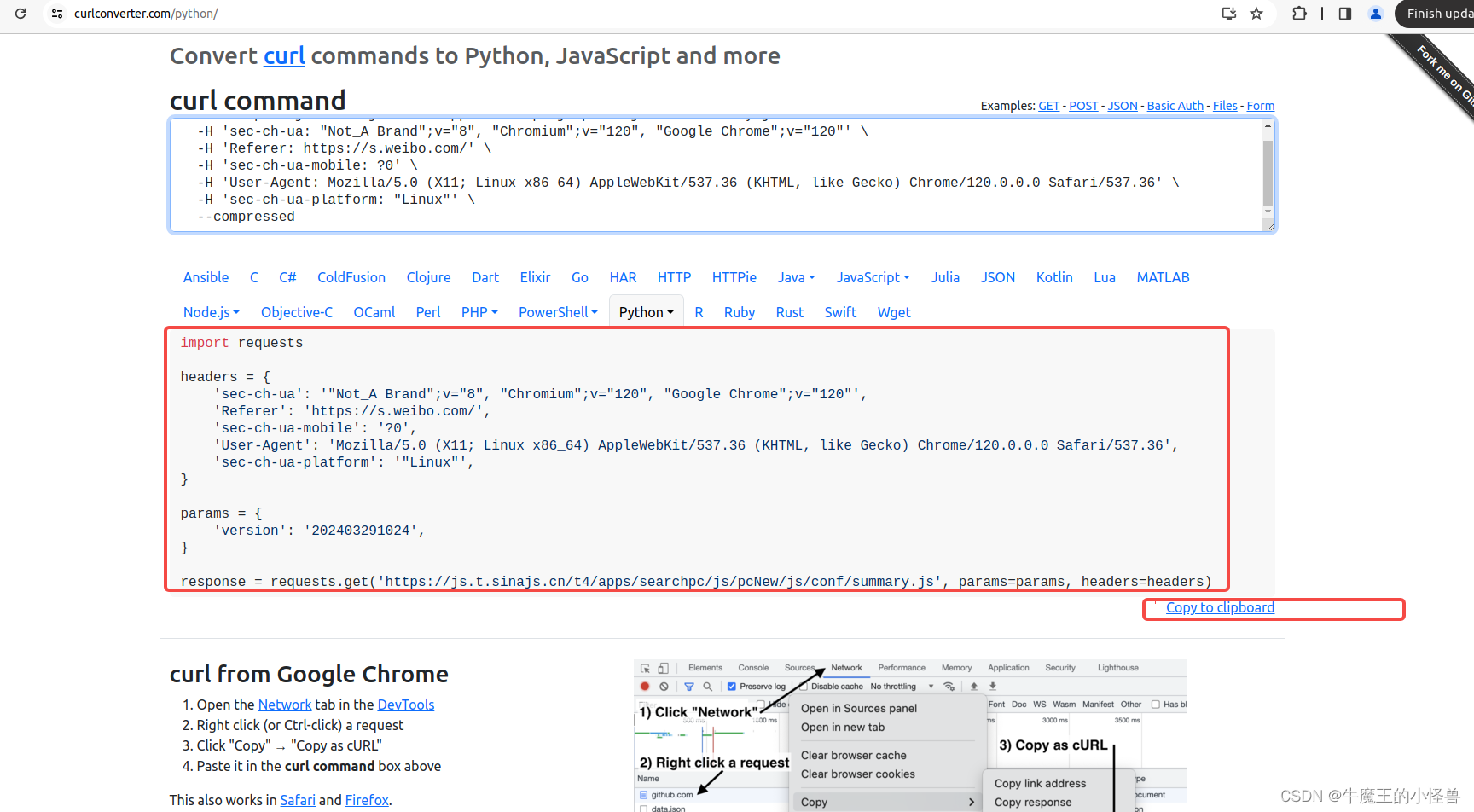
拷贝到 pycharm 中,可直接作为源代码使用:
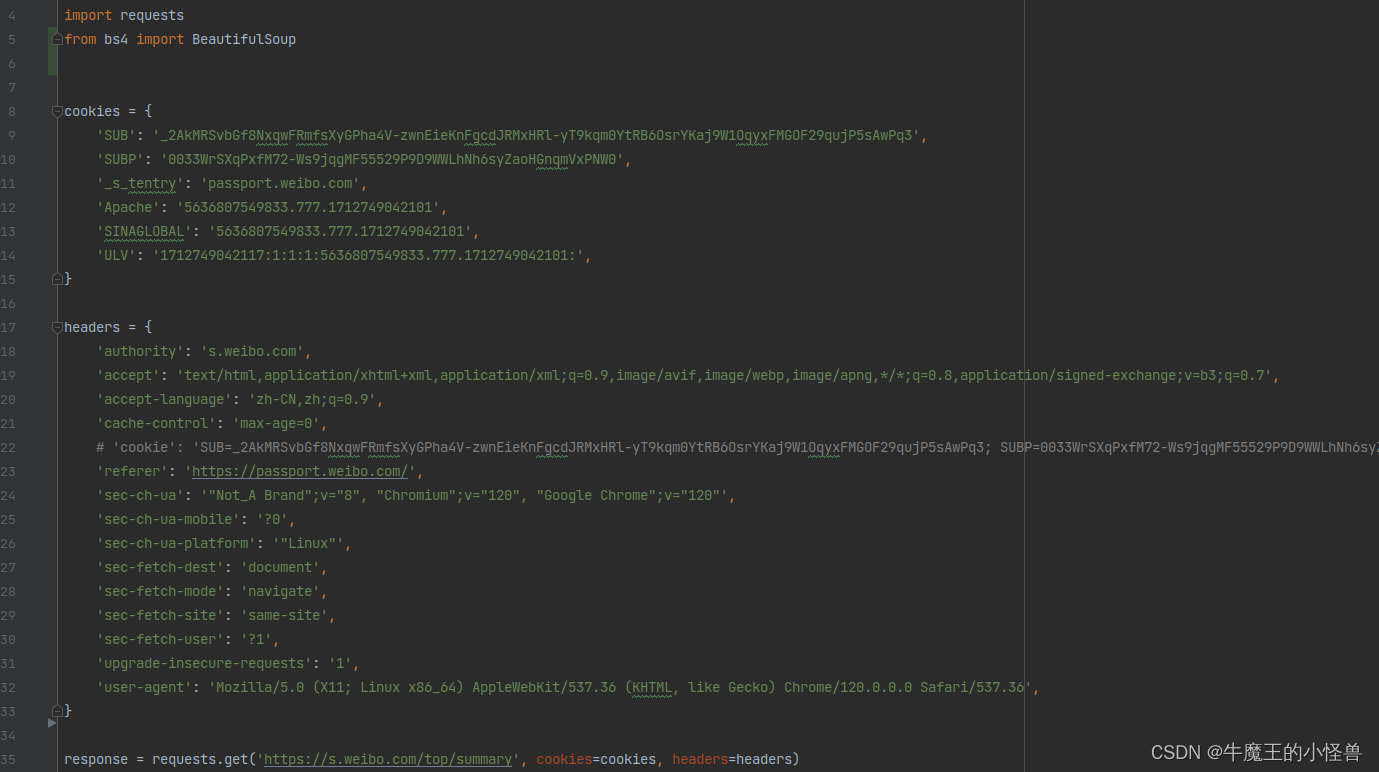
3. 第三步:获取网页
通过requests.get() 即可获取网页内容:
response = requests.get('https://s.weibo.com/top/summary', cookies=cookies, headers=headers)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
print(f'soup value= {soup}')4. 第四步:解析网页
这个时候,我们需要回到网页: 【按下F12】–> 【找到网页的Elements部分 --> 【选中左上角的小框带箭头的标志】,进入【内容选择模式】,如下图,当点击(或鼠标移动到)对应网页内容时,这个时候网页就会自动在右边显示出你获取网页部分对应的代码。


在找到想要爬取的页面部分的网页内容后,在响应条目(如:“赵丽颖拍林更新”)上右键,退出【内容选择模式】。
然后将鼠标放置于 【Element】中对应的代码上,右键 -> copy --> selector。就如图所示。


5. 第五步:分析得到的信息,简化地址
黏贴到文本文件中信息如下:
#pl_top_realtimehot > table > tbody > tr:nth-child(6) > td.td-02
同理再黏贴:
#pl_top_realtimehot > table > tbody > tr:nth-child(8) > td.td-02 > a
其实刚才复制的selector就相当于网页上对应部分存放的地址。由于我们需要的是网页上的一类信息,所以我们需要对获取的地址进行分析,提取。
当然,就用那个地址也是可行的,就是只能获取到你选择的网页上的那部分内容。
可以发现几个地址有很多相同的地方,唯一不同的地方就是tr部分。由于tr是网页标签,后面的部分就是其补充的部分,也就是子类选择器。可以推断出,该类信息,就是存储在tr的子类中,我们直接对tr进行信息提取,就可以获取到该部分对应的所有信息。所以提炼后的地址为:
#pl_top_realtimehot > table > tbody > tr > td.td-02 > a
这个过程对js类语言有一定了解的hxd估计会更好处理。不过没有js类语言基础也没关系,主要步骤就是,保留相同的部分就行,慢慢的试,总会对的。
6. 第六步:爬取内容,清洗数据
这一步完成后,我们就可以直接爬取数据了。用一个标签存储上面提炼出的像地址一样的东西。标签就会拉取到我们想获得的网页内容。
# 爬取内容
content = "#pl_top_realtimehot > table > tbody > tr > td.td-02 > a"
之后我们就要soup和text过滤掉不必要的信息,比如js类语言,排除这类语言对于信息受众阅读的干扰。这样我们就成功的将信息,爬取下来了。
# 清洗数据
a = soup.select(content)将数据存储到文件夹中,所以会有wirte带来的写的操作。想把数据保存在哪里,或者想怎么用,就看读者自己了。
# 数据存储
fo = open("./weibo_down.txt", 'a', encoding="utf-8")
for i in range(0, len(a)):a[i] = a[i].textfo.write(a[i] + '\n')fo.close()
7. 爬取微博热搜的代码实例以及结果展示
import osimport requests
from bs4 import BeautifulSoupcookies = {'SUB': '_2AkMRSvbGf8NxqwFRmfsXyGPha4V-zwnEieKnFgcdJRMxHRl-yT9kqm0YtRB6OsrYKaj9W1OqyxFMGOF29qujP5sAwPq3','SUBP': '0033WrSXqPxfM72-Ws9jqgMF55529P9D9WWLhNh6syZaoHGnqmVxPNW0','_s_tentry': 'passport.weibo.com','Apache': '5636807549833.777.1712749042101','SINAGLOBAL': '5636807549833.777.1712749042101','ULV': '1712749042117:1:1:1:5636807549833.777.1712749042101:',
}headers = {'authority': 's.weibo.com','accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7','accept-language': 'zh-CN,zh;q=0.9','cache-control': 'max-age=0',# 'cookie': 'SUB=_2AkMRSvbGf8NxqwFRmfsXyGPha4V-zwnEieKnFgcdJRMxHRl-yT9kqm0YtRB6OsrYKaj9W1OqyxFMGOF29qujP5sAwPq3; SUBP=0033WrSXqPxfM72-Ws9jqgMF55529P9D9WWLhNh6syZaoHGnqmVxPNW0; _s_tentry=passport.weibo.com; Apache=5636807549833.777.1712749042101; SINAGLOBAL=5636807549833.777.1712749042101; ULV=1712749042117:1:1:1:5636807549833.777.1712749042101:','referer': 'https://passport.weibo.com/','sec-ch-ua': '"Not_A Brand";v="8", "Chromium";v="120", "Google Chrome";v="120"','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"Linux"','sec-fetch-dest': 'document','sec-fetch-mode': 'navigate','sec-fetch-site': 'same-site','sec-fetch-user': '?1','upgrade-insecure-requests': '1','user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
}response = requests.get('https://s.weibo.com/top/summary', cookies=cookies, headers=headers)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
print(f'soup value= {soup}')# 爬取内容
content = "#pl_top_realtimehot > table > tbody > tr > td.td-02 > a"# 清洗数据
a = soup.select(content)# 数据存储
fo = open("./weibo_down.txt", 'a', encoding="utf-8")
for i in range(0, len(a)):a[i] = a[i].textfo.write(a[i] + '\n')fo.close()