知名wordpress架构网站重庆百度地图
目录
一、环境准备
二、安装部署
2.1 二进制安装
2.2 python 3 支持
三、Data X 初体验
3.1 配置示例
3.1.1. 生成配置模板
3.1.2 创建配置文件
3.1.3 运行 DataX
3.1.4 结果显示
3.2 动态传参
3.2.1. 动态传参的介绍
3.2.2. 动态传参的案例
3.3 迸发设置
3.3.1 直接指定
3.3.2 Bps
3.3.3 tps
3.3.4. 优先级
官方参考文档:https://github.com/alibaba/DataX/blob/master/userGuid.md
一、环境准备
-
Linux 操作系统
-
JDK(1.8 及其以上都可以,推荐 1.8):Linux 下安装 JDK 和 Maven 环境_linux安装jdk和maven-CSDN博客
-
Python(2 或者 3 都可以):Spark-3.2.4 高可用集群安装部署详细图文教程_spark高可用-CSDN博客
-
Apache Maven 3.x(只有源码编译安装需要):Linux 下安装 JDK 和 Maven 环境_linux安装jdk和maven-CSDN博客
二、安装部署
2.1 二进制安装
-
1、下载安装 DataX 工具包,下载地址:https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202309/datax.tar.gz
-
2、将下载好的包上传到 Linux 中
-
3、解压安装即可
(base) [root@hadoop03 ~]# tar -zxvf datax.tar.gz -C /usr/local/
- 4、自检脚本
# python {YOUR_DATAX_HOME}/bin/datax.py {YOUR_DATAX_HOME}/job/job.json# 例如:
python /usr/local/datax/bin/datax.py /usr/local/datax/job/job.json
- 5、异常解决
如果执行自检程序出现如下错误:
[main] WARN ConfigParser - 插件[streamreader,streamwriter]加载失败,1s后重试... Exception:Code:[Common-00], Describe:[您提供的配置文件存在错误信息,请检查您的作业配置 .] - 配置信息错误,您提供的配置文件[/usr/local/datax/plugin/reader/._drdsreader/plugin.json]不存在. 请检查您的配置文件.
[main] ERROR Engine -经DataX智能分析,该任务最可能的错误原因是:
com.alibaba.datax.common.exception.DataXException: Code:[Common-00], Describe:[您提供的配置文件存在错误信息,请检查您的作业配置 .] - 配置信息错误,您提供的配置文件[/usr/local/datax/plugin/reader/._drdsreader/plugin.json]不存在. 请检查您的配置文件.at com.alibaba.datax.common.exception.DataXException.asDataXException(DataXException.java:26)at com.alibaba.datax.common.util.Configuration.from(Configuration.java:95)at com.alibaba.datax.core.util.ConfigParser.parseOnePluginConfig(ConfigParser.java:153)at com.alibaba.datax.core.util.ConfigParser.parsePluginConfig(ConfigParser.java:125)at com.alibaba.datax.core.util.ConfigParser.parse(ConfigParser.java:63)at com.alibaba.datax.core.Engine.entry(Engine.java:137)at com.alibaba.datax.core.Engine.main(Engine.java:204)解决方案:将 plugin 目录下的所有的以 _ 开头的文件都删除即可
cd /usr/local/datax/plugin
find ./* -type f -name ".*er" | xargs rm -rf2.2 python 3 支持
DataX 这个项目本身是用 Python2 进行开发的,因此需要使用 Python2 的版本进行执行。但是我们安装的 Python 版本是 3,而且 3 和 2 的语法差异还是比较大的。因此直接使用 python3 去执行的话,会出现问题。
如果需要使用 python3 去执行数据同步的计划,需要修改 bin 目录下的三个 py 文件,将这三个文件中的如下部分修改即可:
-
print xxx 替换为 print(xxx)
-
Exception, e 替换为 Exception as e
# 以 datax.py 为例进行修改
(base) [root@hadoop03 ~]# cd /usr/local/datax/bin/
(base) [root@hadoop03 /usr/local/datax/bin]# ls
datax.py dxprof.py perftrace.py
(base) [root@hadoop03 /usr/local/datax/bin]# vim datax.pyprint(readerRef)print(writerRef)jobGuid = 'Please save the following configuration as a json file and use\n python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json \nto run the job.\n'print(jobGuid)
使用 python3 命令执行自检脚本:
(base) [root@hadoop03 /usr/local/datax/bin]# python3 /usr/local/datax/bin/datax.py /usr/local/datax/job/job.json
三、Data X 初体验
3.1 配置示例
3.1.1. 生成配置模板
DataX 的数据同步工作,需要使用 json 文件来保存配置信息,配置 writer、reader 等信息。我们可以使用如下的命令来生成一个配置的 json 模板,在这个模板上进行修改,生成最终的 json文件。
python3 /usr/local/datax/bin/datax.py -r {reader} -w {writer}将其中的 {reader} 替换成自己想要的 reader 组件名字,将其中的 {writer} 替换成自己想要的 writer 组件名字。
- 支持的 reader:
所有的 reader 都存储于 DataX 安装目录下的 plugin/reader 目录下,可以在这个目录下查看:
(base) [root@hadoop03 /usr/local/datax]# ls
bin conf job lib log log_perf plugin script tmp
(base) [root@hadoop03 /usr/local/datax]# ls plugin/reader/
cassandrareader ftpreader hbase11xsqlreader loghubreader odpsreader otsreader sqlserverreader tsdbreader
clickhousereader gdbreader hbase20xsqlreader mongodbreader opentsdbreader otsstreamreader starrocksreader txtfilereader
datahubreader hbase094xreader hdfsreader mysqlreader oraclereader postgresqlreader streamreader
drdsreader hbase11xreader kingbaseesreader oceanbasev10reader ossreader rdbmsreader tdenginereader- 支持的 writer:
所有的 writer 都存储于 DataX 安装目录下的 plugin/writer 目录下,可以在这个目录下查看:
(base) [root@hadoop03 /usr/local/datax]# ls plugin/writer/
adbpgwriter datahubwriter gdbwriter hdfswriter mongodbwriter odpswriter postgresqlwriter streamwriter
adswriter doriswriter hbase094xwriter hologresjdbcwriter mysqlwriter oraclewriter rdbmswriter tdenginewriter
cassandrawriter drdswriter hbase11xsqlwriter kingbaseeswriter neo4jwriter oscarwriter selectdbwriter tsdbwriter
clickhousewriter elasticsearchwriter hbase11xwriter kuduwriter oceanbasev10writer osswriter sqlserverwriter txtfilewriter
databendwriter ftpwriter hbase20xsqlwriter loghubwriter ocswriter otswriter starrockswriter
例如需要查看 streamreader 和 streamwriter 的配置,可以使用如下操作:
python3 /usr/local/datax/bin/datax.py -r streamreader -w streamwriter这个命令可以将 json 模板直接打印在控制台上,如果想要以文件的形式保存下来,重定向输出到指定文件:
python3 /usr/local/datax/bin/datax.py -r streamreader -w streamwriter > ~/stream2stream.json3.1.2 创建配置文件
创建 stream2stream.json 文件:
(base) [root@hadoop03 ~]# mkdir jobs
(base) [root@hadoop03 ~]# cd jobs/
(base) [root@hadoop03 ~/jobs]# vim stream2stream.json
{"job": {"content": [{"reader": {"name": "streamreader","parameter": {"sliceRecordCount": 10,"column": [{"type": "long","value": "10"},{"type": "string","value": "hello,你好,世界-DataX"}]}},"writer": {"name": "streamwriter","parameter": {"encoding": "UTF-8","print": true}}}],"setting": {"speed": {"channel": 5}}}
}3.1.3 运行 DataX
(base) [root@hadoop03 ~/jobs]# python3 /usr/local/datax/bin/datax.py stream2stream.json
3.1.4 结果显示

3.2 动态传参
3.2.1. 动态传参的介绍
DataX 同步数据的时候需要使用到自己设置的配置文件,其中可以定义同步的方案,通常为 json 的格式。在执行同步方案的时候,有些场景下需要有一些动态的数据。例如:
-
将 MySQL 的数据同步到 HDFS,多次同步的时候只是表的名字和字段不同。
-
将 MySQL 的数据增量的同步到 HDFS 或者 Hive 中的时候,需要指定每一次同步的时间。
-
...
这些时候,如果我们每一次都去写一个新的 json 文件将会非常麻烦,此时我们就可以使用 动态传参
所谓的动态传参,就是在 json 的同步方案中,使用类似变量的方式来定义一些可以改变的参数。在执行同步方案的时候,可以指定这些参数具体的值。
3.2.2. 动态传参的案例
{"job": {"content": [{"reader": {"name": "streamreader","parameter": {"sliceRecordCount": $TIMES,"column": [{"type": "long","value": "10"},{"type": "string","value": "hello,你好,世界-DataX"}]}},"writer": {"name": "streamwriter","parameter": {"encoding": "UTF-8","print": true}}}],"setting": {"speed": {"channel": 1}}}
} 在使用到同步方案的时候,可以使用 -D 来指定具体的参数的值。例如在上述的 json 中,我们设置了一个参数 TIMES,在使用的时候,可以指定 TIMES 的值,来动态的设置 sliceRecordCount 的值。
python3 /usr/local/datax/bin/datax.py -p "-DTIMES=3" stream2stream.json3.3 迸发设置
在 DataX 的处理流程中,Job 会被划分成为若干个 Task 并发执行,被不同的 TaskGroup 管理。在每一个 Task 的内部,都由 reader -> channel -> writer 的结构组成,其中 channel 的数量决定了并发度。那么 channel 的数量是怎么指定的?
-
直接指定 channel 数量
-
通过
Bps计算 channel 数量 -
通过
tps计算 channel 数量
3.3.1 直接指定
在同步方案的 json 文件中,我们可以设置 job.setting.speed.channel 来设置 channel 的数量。这是最直接的方式。在这种配置下,channel 的 Bps 为默认的 1MBps,即每秒传输 1MB 的数据。
3.3.2 Bps
Bps(Byte per second)是一种非常常见的数据传输速率的表示,在 DataX 中,可以通过参数设置来限制总 Job 的 Bps 以及单个 channel 的Bps,来达到限速和 channel 数量计算的效果。
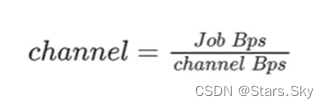
-
Job Bps:对一个 Job 进行整体的限速,可以通过
job.setting.speed.byte进行设置。 -
channel Bps:对单个 channel 的限速,可以通过
core.transport.channel.speed.byte进行设置。
3.3.3 tps
tps(transcation per second)是一种很常见的数据传输速率的表示,在 DataX 中,可以通过参数设置来限制总 Job 的 tps 以及单个 channel 的 tps,来达到限速和 channel 数量计算的效果。
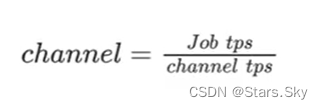
-
Job tps:对一个 Job 进行整体的限速,可以通过
job.setting.speed.record进行设置。 -
channel tps:对单个 channel 的限速,可以通过
core.transport.channel.speed.record进行设置。
3.3.4. 优先级
-
如果同时配置了 Bps 和 tps 限制,以小的为准。
-
只有在 Bps 和 tps 都没有配置的时候,才会以 channel 数量配置为准。
上一篇文章:大数据 DataX 数据同步数据分析入门-CSDN博客