找外包公司做网站给源码吗宁波抖音seo搜索优化软件
1 目标站点分析
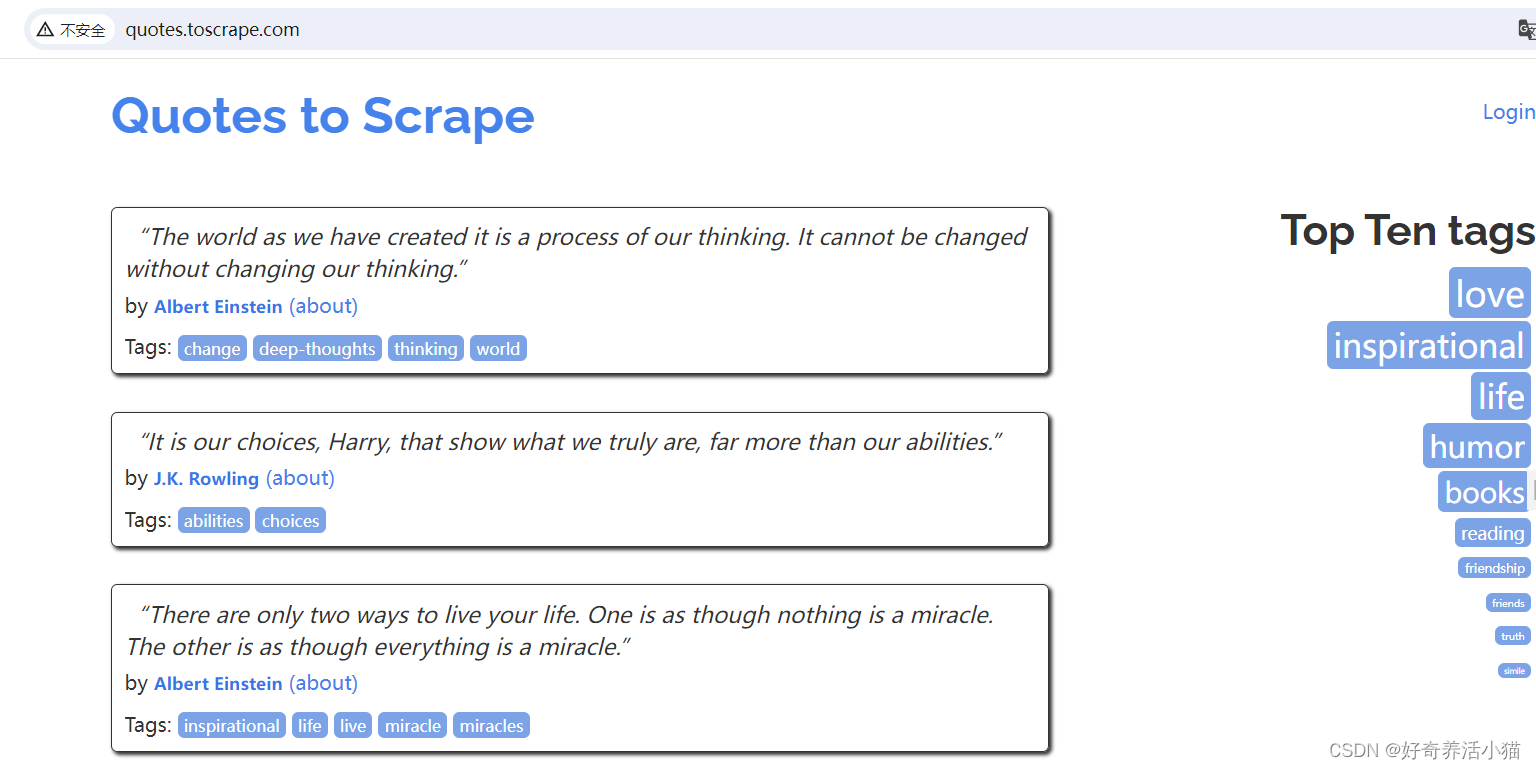
抓取网站:http://quotes.toscrape.com/
主要显示了一些名人名言,以及作者、标签等等信息:
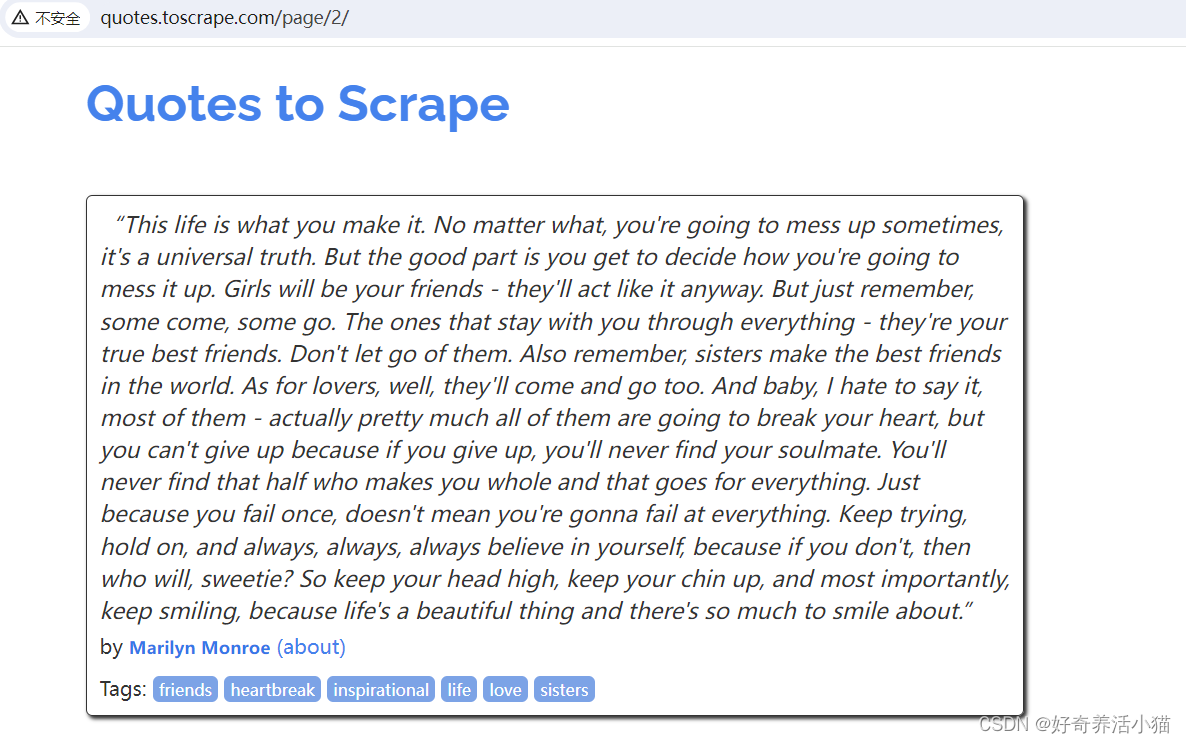
点击next,page变为2:
2 流程框架
- 抓取第一页:请求第一页的URL并得到源代码,进行下一步分析。
- 获取内容和下一页链接:分析源代码,提取首页内容,获取下一页链接等待进一步爬取。
- 翻页爬取:请求下一页信息,分析内容并请求再下一页链接。
- 保存爬取内容:将爬取结果保存为特定格式如文本,数据库。
3 代码实战
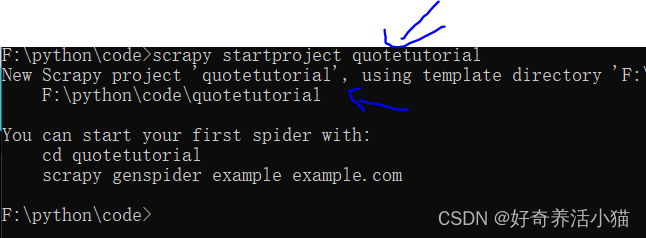
新建一个项目
scrapy startproject quotetutorial
创建一个spider(名为quotes):

使用pycharm来打开已经在本地生成的项目:

scrapy.cfg:配置文件
items.py:保存数据的数据结构
middlewares.py:爬取过程中定义的一些中间件,可以用来处理Request,Response以及Exceptions等操作,也可以用来修改Request, Response等相关的配置
pipelines.py:项目管道,可以用来输出一些items
settings.py:定义了许多配置信息
quotes.py:主要的运行代码
执行这个爬虫程序:
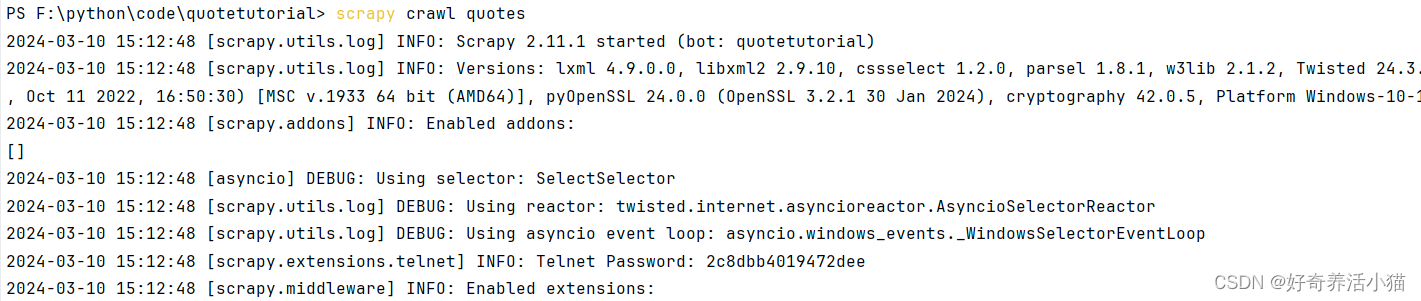
可以看到控制台中打印出了许多调试信息,可以看出,它和普通的爬虫不太一样,Scrapy提供了很多额外的输出。
抓取第一页

1.更改QuotesSpider这个类,通过css选中quote这个区块,
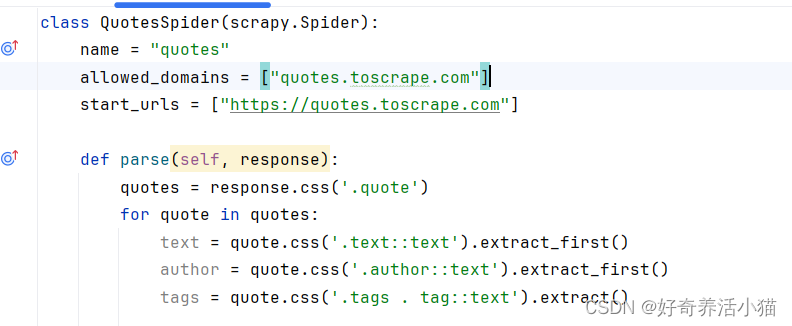
def parse(self, response):quotes = response.css('.quote')for quote in quotes:text = quote.css('.text::text').extract_first()author = quote.css('.author::text').extract_first()tags = quote.css('.tags . tag::text').extract()
这样的解析方法和pyquery非常相似:
.text :指的是标签的class.
::text :是Scrapy特有的语法结构,表示输出标签里面的文本内容.
extract_first() :方法表示获取第一个内容.
extract :会把所有结果都找出来(类似于find和findall).
说明:Scrapy还为我们提供了一个非常强大的工具–shell,在命令行中输入“scrapy shell quotes.toscrape.com”,可以进入命令行交互模式:
例如,直接输入response,回车后会直接执行这条语句。:
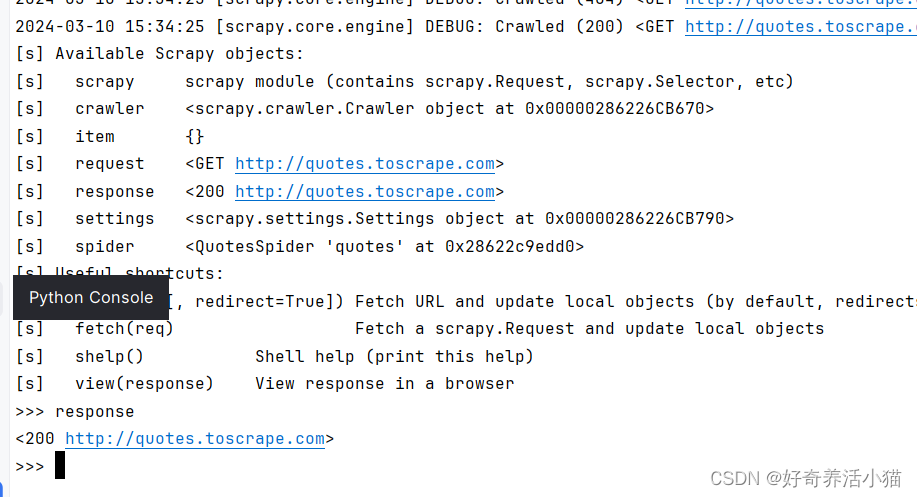
试试刚才写的方法的效果:先查看“response.css(’.quote’)”的输出:

这是一个list类型的数据,里面的内容是Selector选择器,查看第一个结果:此时若直接输入quotes会报错。
先执行quotes = response.css(‘.quote’),然后quotes[0]。

.text和.text::text的区别:data数据的输出和不输出

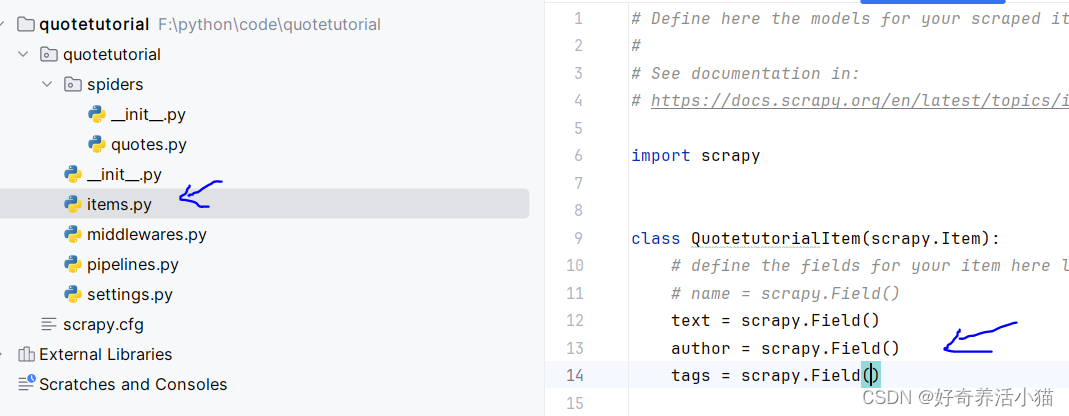
2.借助Scrapy提供的“items.py”定义统一的数据结构,指定一些字段之类的,将爬取到的结果作为一个个整体存下来。根据提示更改文件如下:
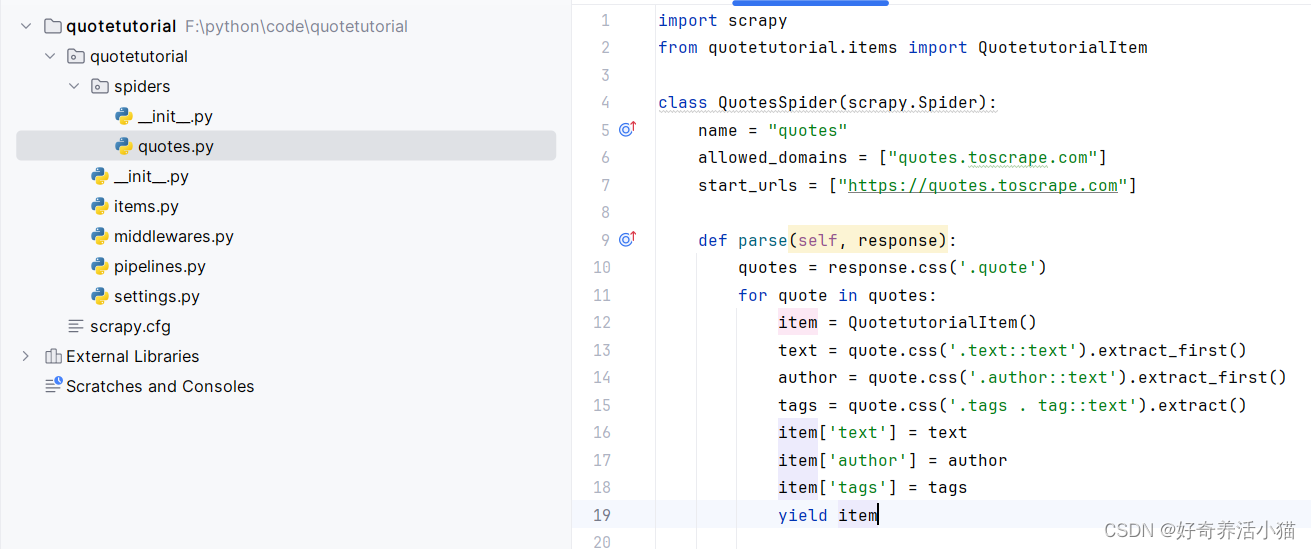
3. 要在parse方法中调用我们刚才定义的items,将提取出的网页信息存储到item,然后调用yield方法将item生成出来。
获取内容和下一页链接
import scrapy
from quotetutorial.items import QuotetutorialItemclass QuotesSpider(scrapy.Spider):name = "quotes"allowed_domains = ["quotes.toscrape.com"]start_urls = ["https://quotes.toscrape.com"]def parse(self, response):quotes = response.css('.quote')for quote in quotes:item = QuotetutorialItem()text = quote.css('.text::text').extract_first()author = quote.css('.author::text').extract_first()tags = quote.css('.tags .tag::text').extract()item['text'] = textitem['author'] = authoritem['tags'] = tagsyield itemnext = response.css('.pager .next a::attr(href)').extract_first()url = response.urljoin(next)yield scrapy.Request(url=url, callback=self.parse)
最后调用Request,第一个参数就是要请求的url,第二个参数“callback”是回调函数的意思,也就是请求之后得到的response由谁来处理,这里我们还是调用parse,因为parse方法就是用来处理索引页的,这就相当于完成了一个递归的调用,可以一直不断地调用parse方法获取下一页的链接并对访问得到的信息进行处理。
再次重新运行程序,可以看到输出了10页的内容,这是因为该网站只有10页内容:
保存爬取到的信息
在原来的命令后面增加“-o 文件名称.json”,爬取完成后就会生成一个“quotes.json”文件,把获取到的信息保存成了标准的json格式。
scrapy crawl quotes -o quotes.json
Scrapy还提供了其它存储格式,比如“jl”格式,在命令行输入如下命令就可以得到jl格式文件。相比于json格式,它没有了最前面和最后面的的大括号,每条数据独占一行:
scrapy crawl quotes -o quotes.jl
或者保存成csv格式:
scrapy crawl quotes -o quotes.csv
它还支持xml、pickle和marshal等格式。
Scrapy还提供了一种远程ftp的保存方式,可以将爬取结果通过ftp的形式进行保存,例如:
scrapy crawl quotes -o ftp://user:pass@ftp.example.com/path/quotes.csv
数据处理
在将爬取到的内容进行保存之前,还需要对item进行相应的处理,因为在解析完之后,有一些item可能不是我们想要的,或者我们想把item保存到数据库里面,就需要借助Scrapy的Pipeline工具。
更改pipelines.py文件:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
from scrapy.exceptions import DropItem
import pymongoclass TextPipeline:def __init__(self):self.limit = 50def process_item(self, item, spider):if item['text']:if len(item['text']) > self.limit:item['text'] = item['text'][0:self.limit].rstrip() + '...'return itemelse:return DropItem('Missing Text')class MongoPipeline(object):def __init__(self, mongo_uri, mongo_db):self.mongo_uri = mongo_uriself.mongo_db = mongo_db@classmethoddef from_crawler(cls, crawler):return cls(mongo_uri=crawler.settings.get('MONGO_URI'),mongo_db=crawler.settings.get('MONGO_DB'))def open_spider(self, spider):self.client = pymongo.MongoClient(self.mongo_uri)self.db = self.client[self.mongo_db]def process_item(self, item, spider):name = item.__class__.__name__self.db['quotes'].insert(dict(item))return itemdef close_spider(self, spider):self.client.close()
更改setting:
MONGO_URI = 'localhost'
MONGO_DB = 'quotestutorial'
pipeline似乎没生效,要想让pipeline生效,需要在settings里面指定pipeline。
后面的序号300和400这样,代表pipeline运行的优先级顺序,序号越小表示优先级越高,会优先进行调用。
MONGO_URI = 'localhost'
MONGO_DB = 'quotestutorial'ITEM_PIPELINES = {'quotetutorial.pipelines.TextPipeline': 300,'quotetutorial.pipelines.MongoPipeline': 400,
}
将程序写好后我们可以再次运行,(命令行输入“scrapy crawl quotes”),可以看到输出的text过长的话,后面就被省略号代替了,同时数据也被存入了MongoDB数据库。