什么网站可以做设计兼职卡一卡二卡三入口2021
1.RDD的数据是过程数据
RDD之间进行相互迭代计算(Transaction的转换),当执行开启后,代表老RDD的消失
RDD的数据是过程数据,只在处理的过程中存在,一旦处理完成,就不见了。
这个特性可以最大化的利用资源,老旧的RDD没有用了,就从内存中清理,给后续的计算腾出内存空间。内存中只存在一个RDD
2.RDD的缓存
当然,Spark也有缓存技术,Spark提供了缓存API,可以让我们通过调用API,将指定的RDD数据保留在内存或者硬盘上。保留了RDD的血缘关系。
RDD的缓存技术是分散存储的,分区数据各自存储到Executor所在的服务器上。
(有时候一个前置RDD,会被多个后续RDD使用,所以需要持久化一下)
3.RDD的CheckPoint
CheckPoint也是将RDD的数据保存起来,但是它仅支持硬盘存储,但是它不保留血缘关系。
CheckPoint技术是将RDD各个分区的数据集中存储到HDFS上
(有时候一个前置RDD,会被多个后续RDD使用,所以需要持久化一下)
4.Jieba库用于中文分词
5.广播变量
使用场景:有时候一个Executor会处理多个分区数据,这些分区数据是接受相同的数据的,这个时候就不需要数据源一一给这些分区发一份分区数据了,只需要给这个Executor发一份数据就好,其所管辖的分区共享这份相同的数据。可以节约资源,降低IO,节约内存。
使用方式:使用boardcast()接口,将本地需要发送给分区的变量标记为广播变量就可以了
本地集合对象 和 分布式集合对象(RDD)进行关联的时候,需要将本地集合对象 封装为广播变量。可以节省网络IO的次数,Executor的内存占用
6.累加器
可以实现分布式的累加功能(将各个分区的值累加到一起)
Spark为我们提供了专门的累加器变量
7.小总结
广播变量解决了什么问题?
分布式集合RDD和本地集合进行关联使用的时候,降低内存占用以及减少网络IO的传输,提高性能。
累加器解决了什么问题?
分布式代码的执行过程中,进行全局累加。
---------------------------------------------------------------------------------------------------------------------------------
---------------------------------------------------------------------------------------------------------------------------------Spark内核调度(重点理解)
8.DAG
DAG:有向无环图,有方向没有形成闭环的一个执行流程图(其实就是代码的一个执行流程图(RDD的转换。。。。RDD的执行)罢了,眼睛看着代码就能分析出来)
eg:

上图中,有三个DAG。
此外:上图也可以看出,一个程序Application,可能有多个Job(一条执行路线就是一个Job,可以理解为上图程序做了三件事(也可以说一个Action会产生一个Job(一个应用程序内的子任务)))
一个Application中,可以有多个JOB,每一个JOB内含一个DAG,同时每一个JOB都是由一个Action产生的。
带有分区关系的DAG图:其实就是在有向无环的DAG图中把分区关系画出来而已。
9.DAG的宽窄依赖和阶段划分
窄依赖:父RDD的一个分区,全部将数据发给子RDD的一个分区
宽依赖:父RDD的一个分区,将数据发给子RDD的多个分区。宽依赖的别名:shuffle
10.DAG的阶段划分
对于Spark来说,会根据DAG,按照宽依赖划分不同的DAG阶段
划分依据:从后向前,遇到宽依赖,就划分出一个阶段,称之为stage
在stage的内部,一定都是窄依赖。
例如下图的两个stage:
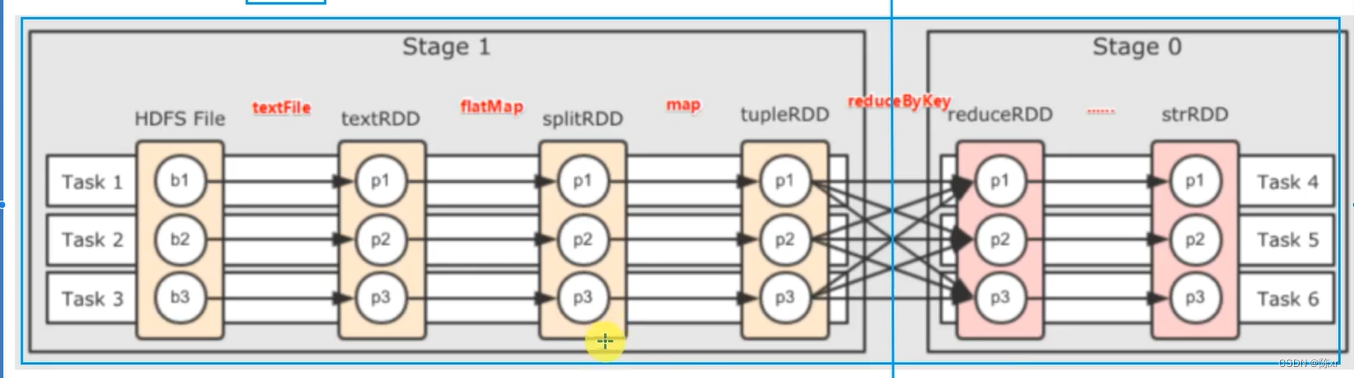
11.Spark是怎么做内存计算的?DAG的作用?Stage阶段划分的作用?
1.Spark会产生DAG图
2.DAG图会基于分区和宽窄依赖关系划分阶段
3.一个阶段内部都是窄依赖,窄依赖内,如果形成前后1:1的分区对应关系,就可以产生许多内存迭代计算的管道
4.这些内存迭代计算的管道,就是一个个具体的执行Task
5.一个Task是一个具体的线程,任务跑在一个线程内,就是走内存计算了。
12.Spark为什么比MapReduce快?
1.Spark的算子十分丰富,MapReduce算子匮乏(Map和Reduce),MapReduce这个编程模型,很难在一套MR任务中处理复杂的任务,很多复杂的任务,是需要写多个MapReduce进行串联,多个MR串联通过磁盘交互数据。
2.Spark可以执行内存迭代,算子之间形成DAG,基于依赖划分阶段之后,在阶段内形成内存迭代管道。但是MapReduce的Map和Reduce之间的交互依旧是通过硬盘来交互的。
综上总结:
a.编程模型上Spark占优(算子丰富)
b.算子交互上,和计算上可以尽量多的内存计算而非磁盘迭代
13.Spark的并行度
在同一时间内,有多少个Task在同时运行
推荐设置全局并行度,不要针对RDD改分区,这可能会影响内存迭代管道的构建,或者会产生额外的Shuffle。
确保是CPUh核心数量的整数倍,最小是2倍,最大一般10倍或者更高均可。
14.Spark的任务调度
Spark的任务,由Driver进行调度,这个工作包含:
a.逻辑DAG的产生
b.分区DAG的产生
c.Task划分
d.将Task分配给Executor并监控其工作
15.Driver内的两个组件
DAG调度器
工作内容:将逻辑的DAG图进行处理,最终得到逻辑上的Task划分
Task调度器
工作内容:基于DAG Schedule的产出,来规划这些逻辑的task,应该在哪些物理的executor上运行,以及监控它们的运行。
16.Spark中的名词概念汇总
Application/应用:用户代码提交到Spark去运行的时候,这就是一个应用。一个Application由一个Driver去控制它的运行。
Application jar:如果是Java语言编写的程序,可以打成一个Application jar的jar包。
Driver program:程序main方法的入口,也是程序的调度者和管理者,也负责构建SparkContext。
Cluster manager/集群管理器:一个外部服务,用于管理整个集群的资源,也就是Master角色的东西
Deploye mode/部署模式:一般用YARN模式(又分为客户端模式 和 集群模式)
Worder node/Worker角色:单台服务器的资源管理者,负责在单个机器内去提供Spark程序运行所需要的资源。
Executor/程序的运行启动器:内部可以分为许多Task,可以理解为真正干活的。
Task/一个工作线程:它是Executor内最小的一个工作单元,这个工作单元对整个Spark任务进行任务的干活。
Job/并行化的计算集合:Job归属于Application,一个Application可以有多个Job。
Stage/阶段:在Job内部基于DAG关系图可以划分出许多Stage(划分依据:宽依赖),每个stage内部都是窄依赖,又因为是窄依赖,便可以构建内存迭代的管道,然后去设定并行的Task。
层级关系梳理:
1.一个Spark环境可以运行多个Application
2.一个代码跑起来,会成为一个Application
3.Application内部可以有多个Job
4.每个Job由一个Action产生,并且每个Job有自己的DAG执行图
5.一个Job的DAG图,会基于宽窄依赖划分成不同的阶段。
6.不同的阶段内,会基于分区数量,形成多个并行的内存迭代管道
7.每一个内存迭代管道形成一个Task(DAG调度器划分将Job内划分具体的task任务,一个Job被划分出来的task在逻辑上称之为这个Job的taskset)
以上就是Spark程序的运行原理,重点理解。