免费电商网站建设平台千锋教育介绍
文章目录
- 机器学习公平性
- 评估指标
- 群体公平性指标
- 个人公平性指标
- 引起机器学习模型不公平的潜在因素
- 提升机器学习模型公平性的措施
机器学习公平性
定义: 机器学习公平性主要研究如何通过解决或缓解“不公平”来增加模型的公平性,以及如何确保模型的输出结果能够让不同的群体、个人都有平等的机会获得利益。然而,受文化和环境的影响,人们对公平性的理解存在一定的主观性。到目前为止,公平性尚未有统一的定义及度量指标。
公平性主要分为群体公平性和个体公平性两类:群体公平性指标侧重于衡量决策(模型结果)对不同群体的偏见程度;个体公平性指标主要侧重于衡量决策对不同个体的偏见程度。
评估指标
假设S为敏感信息的特征(如种族、性别、年龄、民族等),“S=1”表示该群体在社会中为“强势群体”,较少受到歧视,“S≠1”表示该群体在某些方面为“弱势群体”,存在潜在的受到歧视的风险,如少数族裔、老年人、女性等。Y为模型的真实标签,Ŷ为模型预测的结果,Ŷ=1表示模型预测结果为正面(有利于该样本个体的标签),P表示某条件下的概率。
群体公平性指标
群体公平性指标本质上是比较算法在两类或多类群体上的分类结果。
不平等影响(Disparate Impact,DI):模型对于两个不同的群体预测为正类的概率比值
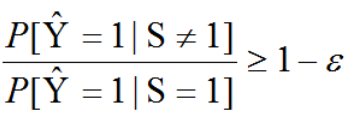
群体均等(Demographic parity,DP):将两个不同群体预测为正类的预测概率差值
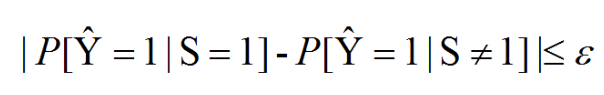
补偿几率(Equalized odds):群体之间假阳性概率(false-positive rates)之差和群体之间真阳性概率(true-positive rates)之差,差值越小则认为模型越公平
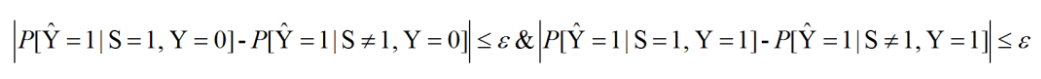
机会均等(Equal Opportunity):不同群体的真阳性概率之差,指标越小代表越公平
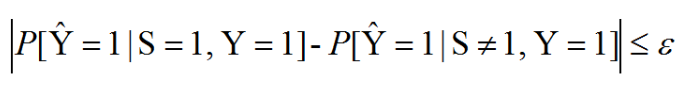
个人公平性指标
个体公平性是衡量决策对不同个体的偏见程度。
个体公平性指标:个体公平性指标是指对于两个个体,如果非敏感信息特征相似,则模型应给出相似的预测结果。
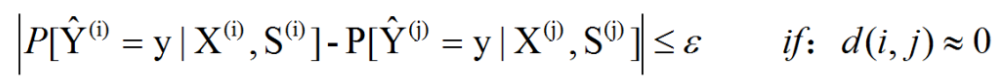
反事实公平性指标:如果一个决策与敏感属性不同的反事实世界中采取的决策一致,那么这个决策对于个体而言是公平的,是一种基于因果推断的公平性定义。
引起机器学习模型不公平的潜在因素
按照机器学习的生命周期可把引起模型不公平的因素归为四类:数据偏差、算法偏差、评估偏差和部署偏差
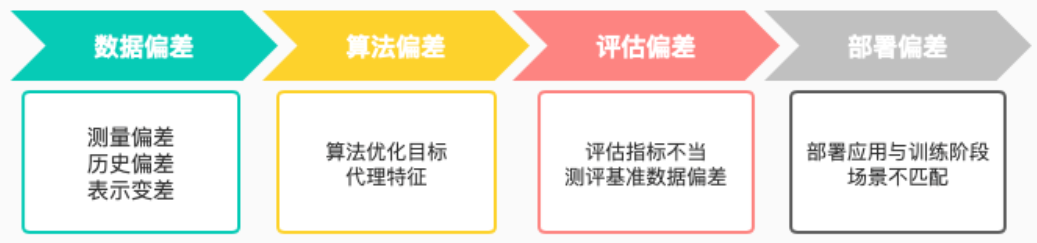
数据偏差主要包括收集数据过程中的测量偏差(Measuring Bias)、蕴含社会文化和习俗的城建信息渗透到数据中产生的历史偏差(Historical Bias)以及训练数据没有充分代表所有预测样本空间带来的表示偏差(Representation Bias)。
算法偏差主要指算法的优化目标带来的不公平风险,以及与敏感特征相关的“代理”特征带来的不公平风险。算法总是会以减少训练过程中模型的输出和真实标签的总体差异为优化目标,当数据类别不平衡时,模型对多数群体的准确率更高。敏感属性的代理特征是指看似非敏感特征,但实际上与敏感特征相关联,因此算法在学习的过程中利用了敏感特征的信息。
评估偏差包括由于算法评测的基准数据不能完全代表目标群体产生的偏见,以及由于评估指标的不当导致选取看似公平而实际并不公平的模型所产生的偏差。
部署偏差是指部署应用的场景与训练阶段场景不匹配产生的偏差。
提升机器学习模型公平性的措施
增加模型公平性的措施分为三类:预处理(数据处理),中间处理(模型训练)和后处理

预处理
- 删除特征,即删除可能会引起歧视的敏感信息以及敏感信息相关的特征;
- 更改数据集的标签,可以先使用原始的数据训练带有不公平性的分类器,使用这个分类器对数据进行分类,在每个群体中根据预测分类的置信度排序,更改置信度过低样本的标签;
- 更改权重,在训练的过程中,特征和标签会被赋予权重,可以通过调整特征的权重来减少模型的不公平性;
- 公平表征,在一些深度学习任务中,会先使用模型提取数据的表征,然后将数据的表征输入分类模型,训练分类器。
中间处理
- 目标函数加入惩罚项。在机器学习中,正则项是用来惩罚模型的复杂度,降低模型过拟合的风险。有研究认为,参照正则项加入惩罚项用于保证分类模型的公平性,一种做法是将假阳率和假阴率的信息参照正则项的方式加入损失函数中,用来惩罚模型的不公平性。
- 分类模型加入约束,通过在模型优化过程中增加约束的方式平衡公平性和准确性。
- 基于特权信息的学习。在训练阶段,模型使用敏感信息(作为特权信息)特征加速模型的收敛来提升模型效果,而在预测阶段则不使用敏感信息。
后处理
- 使用不同的阈值修正预测结果。
- 对不同的群体使用不同的分类器。
以上三种策略各有优缺点。预处理的方法较为简单,可以在大多数分类问题中使用,缺点是会降低模型的可解释性。建模中的处理方式较为灵活,可以根据特定的情况调整,缺点则是较为复杂,并且不同的算法之间难以复用。后处理的方式和预处理一样,也可以适用于大多数分类问题,但是这种方法可能会影响模型效果,而且在人为改动模型输出结果的情况下也有一定的伦理风险。