滕州英文网站建设大连网站推广
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- Q1:卷积网络和传统网络的区别
- Q2:卷积神经网络的架构
- Q3:卷积神经网络中的参数共享,也是比传统网络的优势所在
- 4、 具体的实现代码+网络搭建
前言
深度学习pytorch系列第三篇啦,之前更了FC,NN,这篇是卷积神经网络(cNN)模型实现手写数字识别,依然是重在理解哈,具体的理解内容我都以注释的形式放在了代码中,我就直接放代码了,因为我把一些知识点和理解的东西用注释的形式写了
首先是关于卷积神经网络的一些点
Q1:卷积网络和传统网络的区别
传统网络只适合结构化数据,不适合图像数据,由于图像数据的数据量大(表现为像素点多),传统网络需要使用的参数量太大
Q2:卷积神经网络的架构
卷积神经网络包括:输入层,卷积层,池化层,全连接层
重点介绍卷积层!!
卷积就是针对每个区域去计算特征。可以这样做的原因是:图片是有像素点构成的,针对每个像素点进行处理,需要的参数量过于庞大,并且相邻的像素点之间是存在联系的
特征图的个数与卷积核的个数一致。每个卷积核通过对输入特征图进行卷积操作,生成一个输出特征图。因此,卷积核的个数决定了输出的特征图的个数。
使用不同的卷积核学习同一个位置,可以得到不同的特征图,从而使特征多样化
卷积核的大小一般使用3*3
卷积核的大小规格一般是固定的,卷积核的数量理论上是越多越好
卷积层涉及的参数有:滑动窗口步长,卷积核尺寸,边缘填充,卷积核个数
卷积结果计算公式:长:h2=(h1-Fh+2p)/s +1 宽:w2=(w1-Fw+2p)/s +1
其中:w1,h1表示输入的宽度,长度;w2和h2表示输出特征图的宽度、长度,F表示卷积核的长和宽,s表示滑动窗口的补偿,p表示边界填充
经过卷积操作后,特征图的长和宽也可以保持不变
池化层的作用就是筛选好的特征,pool是只筛选位置的,channel是全部使用的
池化也称为下采样,(一次只能下采样原来的一半,不能直接224-16)
卷积神经网络由多个block组成,重点就在于怎么设计这个block的组成
关于卷积神经网络的层数,带权重参数的就算是一层,6个conn+1个fc,就可以说是7层网络结构
Q3:卷积神经网络中的参数共享,也是比传统网络的优势所在
同一个卷积核在各个位置上的参数都是一致的
权重参数的个数与输入数据的大小无关
4、 具体的实现代码+网络搭建
# 读取数据
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchvision import datasets,transforms
# transforms 进行预处理,比如进行tensor转换
import matplotlib.pyplot as plt
import numpy as np
#全连接:batch*28*28,全连接各个像素点之间无关
# cnn:batch*1*28*28 ,多了一个参数channel,卷积会综合考虑一个窗口之间的关系,因此各个像素点并不是独立的,卷积网络更适合处理图像数据
# 定义超参数
input_size = 28 #图像的总尺寸28*28
num_classes = 10 #标签的种类数
num_epochs = 3 #训练的总循环周期
batch_size = 64 #一个撮(批次)的大小,64张图片
# 训练集
train_dataset = datasets.MNIST(root='./data',train=True,transform=transforms.ToTensor(),download=True)
# 测试集
test_dataset = datasets.MNIST(root='./data',train=False,transform=transforms.ToTensor())# 构建batch数据
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,batch_size=batch_size,shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,batch_size=batch_size,shuffle=True)
# 卷积网络模块构建
# 一般卷积层,relu层,池化层可以写成一个套餐
# 注意卷积最后结果还是一个特征图,需要把图转换成向量才能做分类或者回归任务
# 定义一个网络
class CNN(nn.Module):def __init__(self):# 构造函数# 卷积网络一般是组合进行的:conv pool relu可以当一个组合super(CNN, self).__init__()self.conv1 = nn.Sequential( # 输入大小 (1, 28, 28)nn.Conv2d( # 2d卷积做任务in_channels=1, # 灰度图out_channels=16, # 要得到几多少个特征图,就是卷积核的个数,相当于有16个卷积核kernel_size=5, # 卷积核大小 5*5的stride=1, # 步长padding=2, # 如果希望卷积后大小跟原来一样,需要设置padding=(kernel_size-1)/2 if stride=1,一般是这么希望的# 如果不能整除pytorch采用向下取整), # 输出的特征图为 (16, 28, 28)nn.ReLU(), # relu层nn.MaxPool2d(kernel_size=2), # 进行池化操作(2x2 区域), 输出结果为: (16, 14, 14),一般是pooling后是之前的一半)self.conv2 = nn.Sequential( # 下一个套餐的输入 (16, 14, 14)nn.Conv2d(16, 32, 5, 1, 2), # 输出 (32, 14, 14)nn.ReLU(), # relu层nn.Conv2d(32, 32, 5, 1, 2),nn.ReLU(),nn.MaxPool2d(2), # 输出 (32, 7, 7))self.conv3 = nn.Sequential( # 下一个套餐的输入 (32, 7, 7)nn.Conv2d(32, 64, 5, 1, 2), # 输出 (64, 7, 7)nn.ReLU(), # 输出 (64, 7, 7))# 只有pool的时候才会筛选特征self.out = nn.Linear(64 * 7 * 7, 10) # 全连接层得到的结果,最后的任务是10分类任务,进行一个wx+b的操作去做分类def forward(self, x):x = self.conv1(x)x = self.conv2(x)x = self.conv3(x)x = x.view(x.size(0), -1) # flatten操作,结果为:(batch_size, 32 * 7 * 7),和reshape操作一样# reshape操作:总的大小是不变的,提供一个维度后,后边的维度自动计算# 比如当前的x:64*7*7,x.size:64,也就是要从三维转成两维,总的大小不变,就变为64*49这样,-1可以简单的看成一个占位符号# 变换维度,开始是64*7*7,转成batchsize*特征个数,比如64*49output = self.out(x)return output
# 定义准确率
def accuracy(predictions, labels):pred = torch.max(predictions.data, 1)[1] # 最大值是多少,最大值的索引,只要索引就可以rights = pred.eq(labels.data.view_as(pred)).sum()return rights, len(labels)
# 训练网络模型
# 实例化
net = CNN()
# 损失函数
criterion = nn.CrossEntropyLoss()
# 优化器,学习率是0.001
optimizer = optim.Adam(net.parameters(), lr=0.001) # 定义优化器,普通的随机梯度下降算法
# 开始训练循环
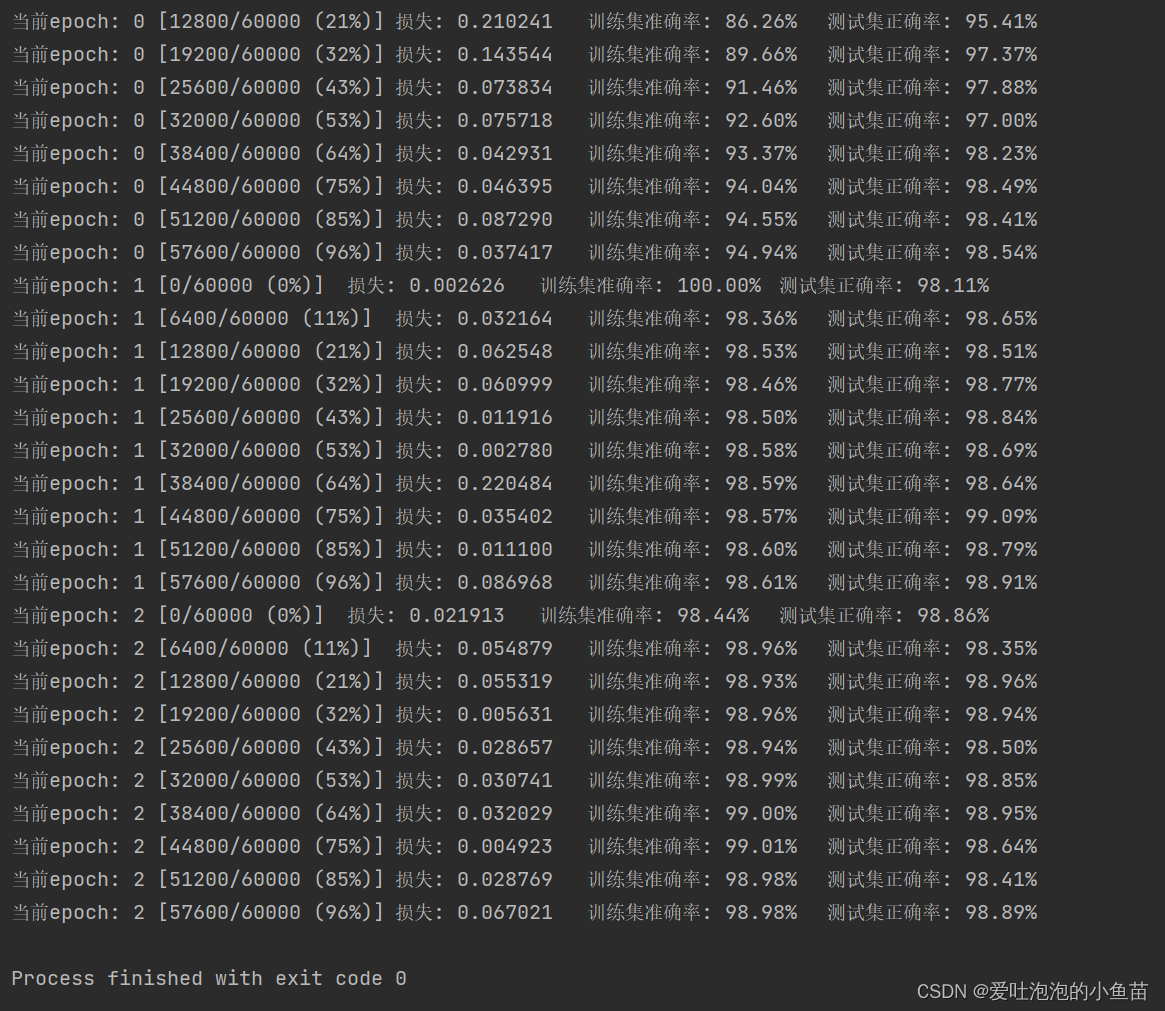
for epoch in range(num_epochs):# 当前epoch的结果保存下来train_rights = []for batch_idx, (data, target) in enumerate(train_loader): # 针对容器中的每一个批进行循环net.train()output = net(data)loss = criterion(output, target)optimizer.zero_grad()loss.backward()optimizer.step()right = accuracy(output, target)train_rights.append(right)# 每一个batch都进行训练,每一百个batch进行一次评估if batch_idx % 100 == 0:net.eval()val_rights = []for (data, target) in test_loader:output = net(data)right = accuracy(output, target)val_rights.append(right)# 准确率计算train_r = (sum([tup[0] for tup in train_rights]), sum([tup[1] for tup in train_rights]))val_r = (sum([tup[0] for tup in val_rights]), sum([tup[1] for tup in val_rights]))print('当前epoch: {} [{}/{} ({:.0f}%)]\t损失: {:.6f}\t训练集准确率: {:.2f}%\t测试集正确率: {:.2f}%'.format(epoch, batch_idx * batch_size, len(train_loader.dataset),100. * batch_idx / len(train_loader),loss.data,100. * train_r[0].numpy() / train_r[1],100. * val_r[0].numpy() / val_r[1]))
实现结果