推荐一下做年会视频的网站永久不收费的软件app
温馨提示:文末有 CSDN 平台官方提供的学长 QQ 名片 :)
1. 项目简介
本文详细探讨了一基于深度学习的可食用植物图像识别系统。采用TensorFlow和Keras框架,利用卷积神经网络(CNN)进行模型训练和预测,并引入迁移学习模型,取得91%的高准确率。通过搭建Web系统,用户能上传待测可食用植物图片,系统实现了自动实时的分类识别。该系统不仅展示了深度学习在生物学领域的实际应用,同时为用户提供了一种高效、准确的野外可食用支付分类识别服务。
【演示视频】基于卷积神经网络的野外可食用植物分类系统
2. 卷积神经网络
2.1 卷积层
卷积层作为输入层后的第一层,主要目的是提取输入的特征表示。卷积层是由多个特征图组成,每个特征图由多个神经元组成,每个神经元通过卷积核与上一层特征图的局部区域相连。卷积核是一个带权值的矩阵,用于提取和计算不同的特征映射。
2.1.1 卷积核
卷积核,又叫滤波器,给定输入图像,输入图像中一个小区域中像素,加权后成为输出图像中的每个对应像素,其中权值即为卷积核。也就是说,卷积核实际上可以理解为是一个权值矩阵。
卷积所得的输出的计算公式为:

式中:Xi为输入特征图,Yj为输出特征图,权值记为Wij,bj是其偏置参数。
2.1.2 卷积运算
如图所示,对应相乘:-1x1+1x(-1)+2x0+1x(-1)+(-1)x(-2)+2x3+0x1+(-1)x2+(-2)x(-2)=7,完成了一次卷积运算,可以将卷积核作为一个权值矩阵,对图片不同位置进行运算时,共享权值。卷积神经网络每一层输出的特征图上的像素点在输入图片上映射的区域大小叫做感受野(绿色框)。
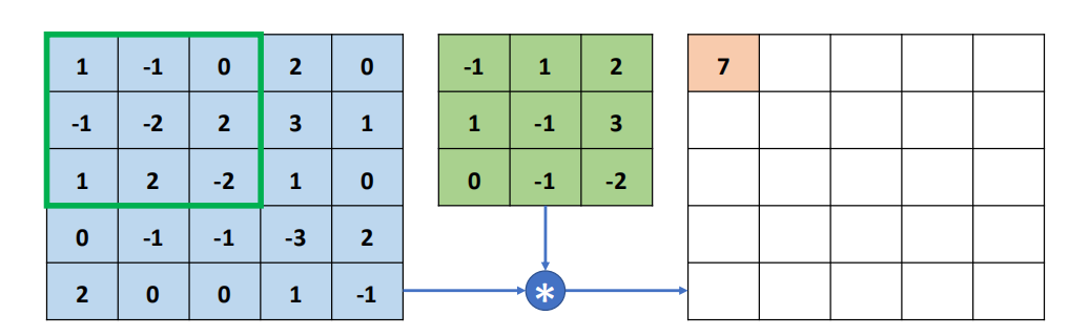
2.1.3 多通道卷积运算
灰度图:灰度图像只有一个通道,把白色与黑色之间按对数关系分为若干等级,称为灰度。灰度分为256阶(0-255),数字越大越接近白色,越小越接近黑色 。
RGB图:彩色图有三个通道,是通过对红R、绿(G)、蓝(B)三个颜色通道的变化以及它们相互之间的叠加来得到各式各样的颜色的,RGB即是代表红、绿、蓝三个通道的颜色。(每像素颜色16777216(256 * 256 * 256)种)其中R、G、B由不同的灰度级来描述,每个分量有256级灰度(0-255)
多通道卷积运算:多通道输入,单核卷积,卷出来之后相加(以三通道,单核卷积为例子)
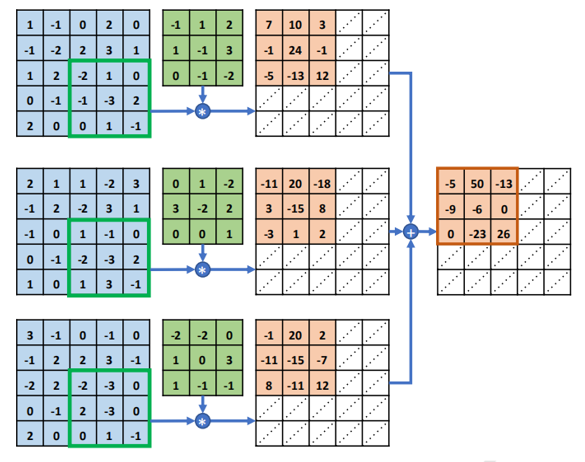
简单说,卷积是乘法,通道间是加法
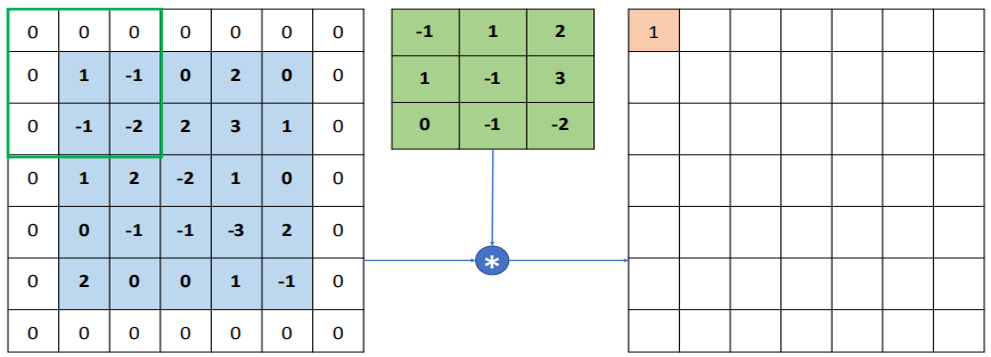
2.1.4 padding
以下图为例,5x5的图片矩阵,经过3x3的卷积核,滑动步长为1的卷积运算,得到的特征图大小为:(5-3+1)x(5-3+1)
很明显,随着卷积次数的增加,卷积后的矩阵会越变越小,而且图像的边缘计算次数会小于图像的内部。
所以进行padding操作,即边缘补0,如下图所示,变成了(7-3+1)x(7-3+1)=5x5,得到的特征图大小个原来一样
这样解决了图像越卷越小和边缘计算次数少的问题
2.2 池化层
2.2.1 原理和计算方法
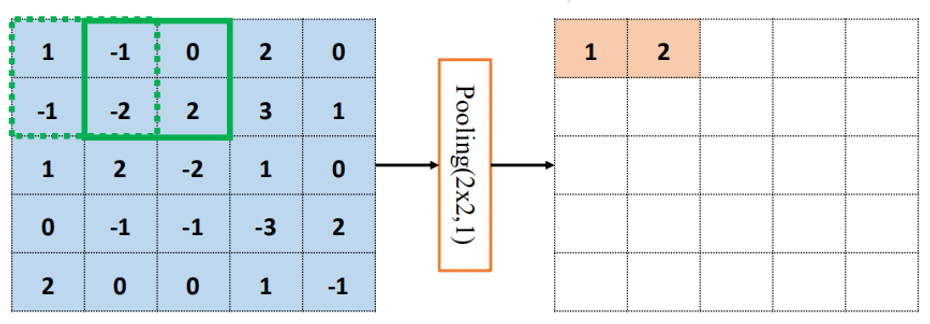
基于局部相关性的思想,通过从局部相关的一组元素中进行采样或信息聚合,从而得到新的元素值。
平均池化层:从局部相关元素集中计算平均值并返回
x = avg({1,0,-2,1})=0
最大池化层:从局部相关元素集中选取最大的一个元素值
x = max({1,0,-2,1})=1
2.2.2 池化层选择
特征提取的误差主要来自两个方面:
(1)邻域大小受限造成的估计值方差增大;
(2)卷积层参数误差造成估计均值的偏移。
平均池化层能减小第一种误差,更多的保留图像的背景信息,最大池化层能减小第二种误差,更多的保留纹理信息。
2.3 Flatten层
用于将输入层的数据压成一维的数据,因为卷积层处理的是二维数据,全连接层只能接收一维数据,所以用在卷积层和全连接层之间,
2.4 激活函数
激活函数的主要作用是提供网络的非线性建模能力。如果没有激活函数,那么该网络仅能够表达线性映射,此时即便有再多的隐藏层,其整个网络跟单层神经网络也是等价的。因此也可以认为,只有加入了激活函数之后,深度神经网络才具备了分层的非线性映射学习能力。
3. 可食用植物分类建模
3.1 加载数据集
该数据集包含了 4005 个可食用植物的图片。数据集的创建者将图片分为了 52 个类别,利用 TensorFlow 的 `tf.keras.preprocessing.image_dataset_from_directory` 函数进行数据集的加载。
plt.figure(figsize=(20, 10))for images, labels in train_ds.take(1):labels = [tf.argmax(i) for i in labels] for i in range(30):ax = plt.subplot(5, 10, i + 1)plt.imshow(images[i].numpy().astype("uint8"))plt.title(class_names[labels[i]])plt.axis("off")
folders = os.listdir('dataset')train_number = []
class_num = []for folder in folders:train_files = os.listdir('./dataset/' + folder)train_number.append(len(train_files))class_num.append(folder)# 不同类别数量,并进行排序
zipped_lists = zip(train_number, class_num)
sorted_pairs = sorted(zipped_lists)
tuples = zip(*sorted_pairs)
train_number, class_num = [ list(t) for t in tuples]# 绘制不同类别数量分布柱状图
plt.figure(figsize=(21,10))
plt.bar(class_num, train_number)
plt.xticks(class_num, rotation='vertical', fontsize=16)
plt.title('不同类别可食用植物样本数量分布柱状图', fontsize=30)
plt.show()
3.2 卷积神经网络模型构建
model = models.Sequential([layers.experimental.preprocessing.Rescaling(1./255, input_shape=(img_height, img_width, 3)),layers.Conv2D(16, (3, 3), activation='relu', input_shape=(img_height, img_width, 3)), # 卷积层1,卷积核3*3 layers.MaxPooling2D((2, 2)), # 池化层1,2*2采样layers.Conv2D(32, (3, 3), activation='relu'), # 卷积层2,卷积核3*3layers.MaxPooling2D((2, 2)), # 池化层2,2*2采样layers.Conv2D(64, (3, 3), activation='relu'), # 卷积层3,卷积核3*3layers.Dropout(0.2), layers.Flatten(), # Flatten层,连接卷积层与全连接层layers.Dense(128, activation='relu'), # 全连接层,特征进一步提取layers.Dense(len(class_names)) # 输出层,输出预期结果
])model.summary() # 打印网络结构3.3 模型训练与评估
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStoppingepochs = 20# 保存最佳模型参数
checkpointer = ModelCheckpoint('best_model.h5',monitor='val_accuracy',verbose=1,save_best_only=True,save_weights_only=True)# 设置早停
earlystopper = EarlyStopping(monitor='val_accuracy', min_delta=0.001,patience=10, verbose=1)history = model.fit(train_ds,validation_data=val_ds,epochs=epochs,callbacks=[checkpointer, earlystopper]
) 3.4 基于迁移学习的模型优化
3.4 基于迁移学习的模型优化
构建VGG模型结构,加载预训练的 VGG16 模型权重:
VGG16_model_con = models.Sequential([
#两次使用64个3*3的卷积核,池化后维度(112,112,64)layers.Conv2D(64, (3, 3),padding='same', activation='relu',name='block1_conv1', input_shape=(img_height, img_width, 3)), layers.Conv2D(64, (3, 3), padding='same',activation='relu',name='block1_conv2'), layers.AveragePooling2D(pool_size=(2,2),strides=(2,2), name = 'block1_pool'),
#两次使用128个3*3的卷积核,池化后维度(56,56,128) layers.Conv2D(128, (3, 3),padding='same',activation='relu',name='block2_conv1'), layers.Conv2D(128, (3, 3),padding='same',activation='relu',name='block2_conv2'), layers.AveragePooling2D(pool_size=(2,2),strides=(2,2), name = 'block2_pool'),
#三次使用256个3*3的卷积核,池化后维度(28,28,256)layers.Conv2D(256, (3, 3), padding='same',activation='relu',name='block3_conv1'), layers.Conv2D(256, (3, 3), padding='same',activation='relu',name='block3_conv2'), layers.Conv2D(256, (3, 3),padding='same',activation='relu',name='block3_conv3'), layers.AveragePooling2D(pool_size=(2,2),strides=(2,2), name = 'block3_pool'),
#三次使用512个3*3的卷积核,池化后维度(14,14,512)layers.Conv2D(512, (3, 3),padding='same',activation='relu',name='block4_conv1'), layers.Conv2D(512, (3, 3),padding='same',activation='relu',name='block4_conv2'), layers.Conv2D(512, (3, 3),padding='same',activation='relu',name='block4_conv3'), layers.AveragePooling2D(pool_size=(2,2),strides=(2,2), name = 'block4_pool'), layers.Conv2D(512, (3, 3),padding='same',activation='relu',name='block5_conv1'), layers.Conv2D(512, (3, 3),padding='same',activation='relu',name='block5_conv2'), layers.Conv2D(512, (3, 3),padding='same',activation='relu',name='block5_conv3'), layers.AveragePooling2D(pool_size=(2,2),strides=(2,2), name = 'block5_pool'),
])
VGG16_model_con.summary()# 加载模型参数
VGG16_model_con.load_weights('./vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5')
# 冻结前13层网络参数 保证加载的预训练参数不被改变
for layer in VGG16_model_con.layers[:13]:layer.trainable = False
Epoch 1/40 101/101 [==============================] - ETA: 0s - loss: 3.9311 - accuracy: 0.0471 Epoch 1: val_accuracy improved from -inf to 0.15231, saving model to best_model.h5 101/101 [==============================] - 220s 2s/step - loss: 3.9311 - accuracy: 0.0471 - val_loss: 3.5434 - val_accuracy: 0.1523 Epoch 2/40 101/101 [==============================] - ETA: 0s - loss: 3.2008 - accuracy: 0.2253 Epoch 2: val_accuracy improved from 0.15231 to 0.40574, saving model to best_model.h5 101/101 [==============================] - 220s 2s/step - loss: 3.2008 - accuracy: 0.2253 - val_loss: 2.4415 - val_accuracy: 0.4057 Epoch 3/40 101/101 [==============================] - ETA: 0s - loss: 2.0040 - accuracy: 0.4863 Epoch 3: val_accuracy improved from 0.40574 to 0.67291, saving model to best_model.h5 ...... 101/101 [==============================] - 235s 2s/step - loss: 0.0106 - accuracy: 0.9981 - val_loss: 0.5884 - val_accuracy: 0.9089 Epoch 17/40 101/101 [==============================] - ETA: 0s - loss: 0.0069 - accuracy: 0.9984 Epoch 17: val_accuracy did not improve from 0.90886 101/101 [==============================] - 225s 2s/step - loss: 0.0069 - accuracy: 0.9984 - val_loss: 0.6261 - val_accuracy: 0.9076 Epoch 17: early stopping
4.5 模型加载预测
加载训练后的模型权重,对待测试植物图片进行类别预测:
from PIL import Image
import numpy as npfor cate in class_names:test_dir = f"./dataset/{cate}"files = os.listdir(test_dir)img = Image.open("./dataset/{}/{}".format(cate, files[0])) img = np.array(img)plt.imshow(img)image = tf.image.resize(img, [img_height, img_width])img_array = tf.expand_dims(image, 0)predictions = VGG16_model_all.predict(img_array) pred_class = class_names[np.argmax(predictions)]if pred_class == cate:plt.title(f"实际类别:{cate}, 预测结果为:{pred_class}", color='green', size=18)else:plt.title(f"实际类别:{cate}, 预测结果为:{pred_class}", color='red', size=18)plt.show()
4. 可食用植物分类系统
4.1 首页介绍与注册登录
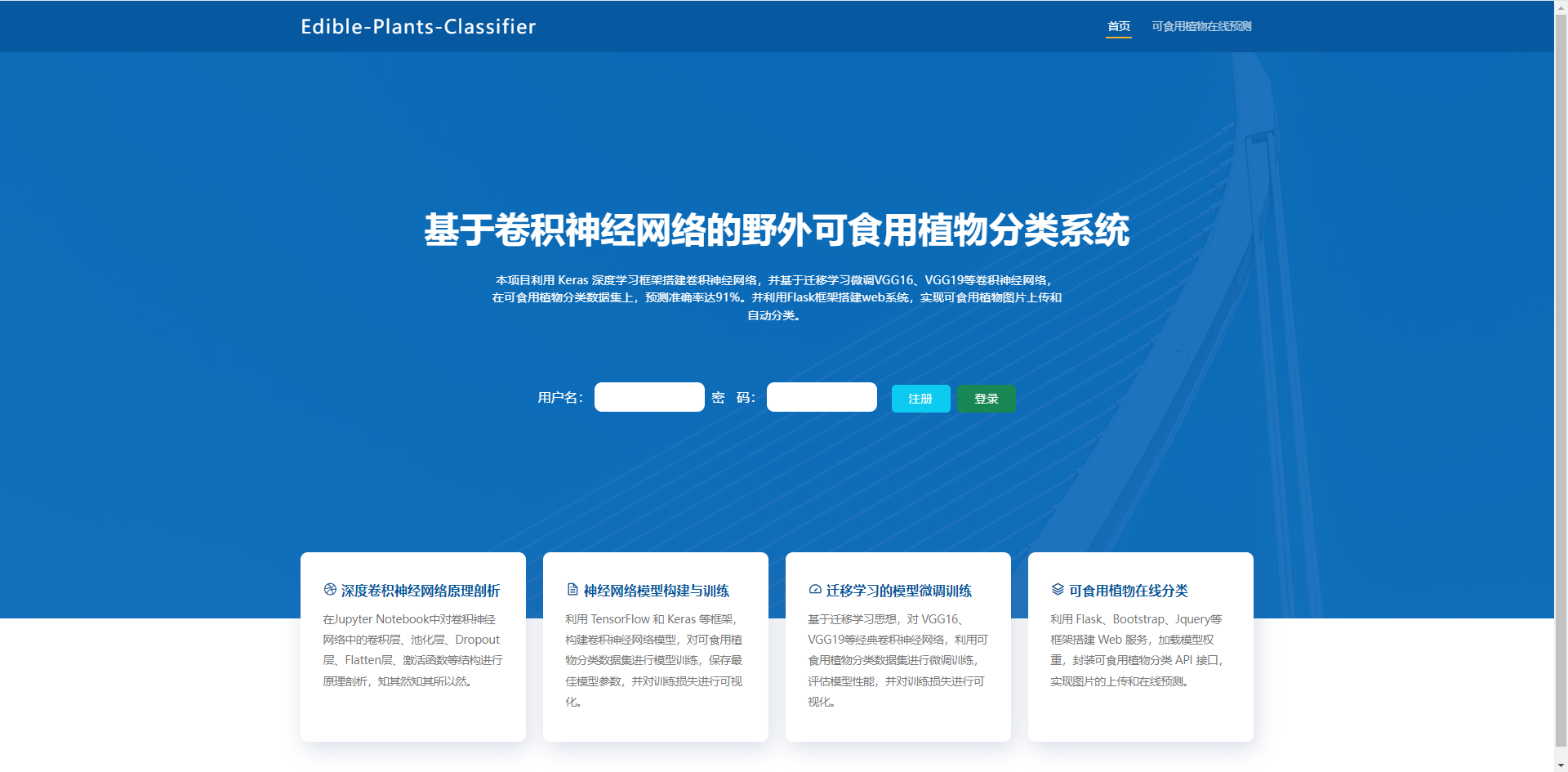
4.2 可食用植物在线预测

5. 结论
本文详细探讨了一基于深度学习的可食用植物图像识别系统。采用TensorFlow和Keras框架,利用卷积神经网络(CNN)进行模型训练和预测,并引入迁移学习模型,取得91%的高准确率。通过搭建Web系统,用户能上传待测可食用植物图片,系统实现了自动实时的分类识别。该系统不仅展示了深度学习在生物学领域的实际应用,同时为用户提供了一种高效、准确的野外可食用支付分类识别服务。
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。技术交流、源码获取认准下方 CSDN 官方提供的学长 QQ 名片 :)
精彩专栏推荐订阅:
1. Python数据挖掘精品实战案例
2. 计算机视觉 CV 精品实战案例
3. 自然语言处理 NLP 精品实战案例
