安徽科技网站建设app营销策略有哪些
pandas的数据加载与预处理
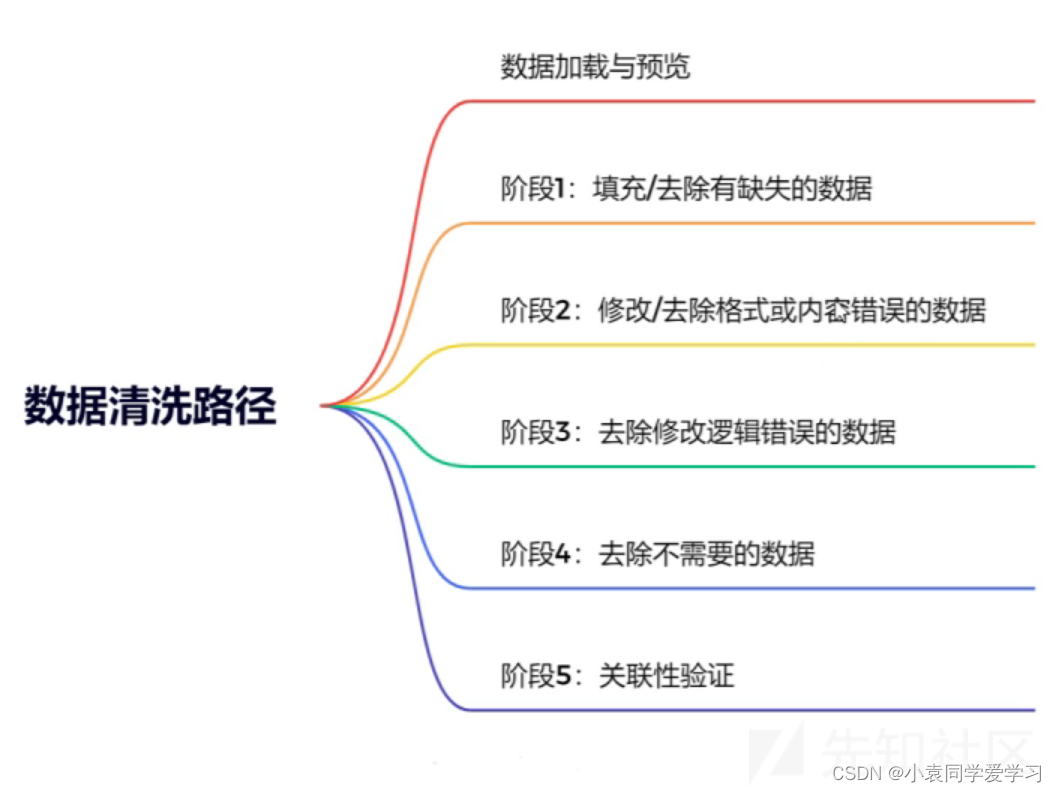
数据清洗:洗掉脏数据
整理分析:字不如表

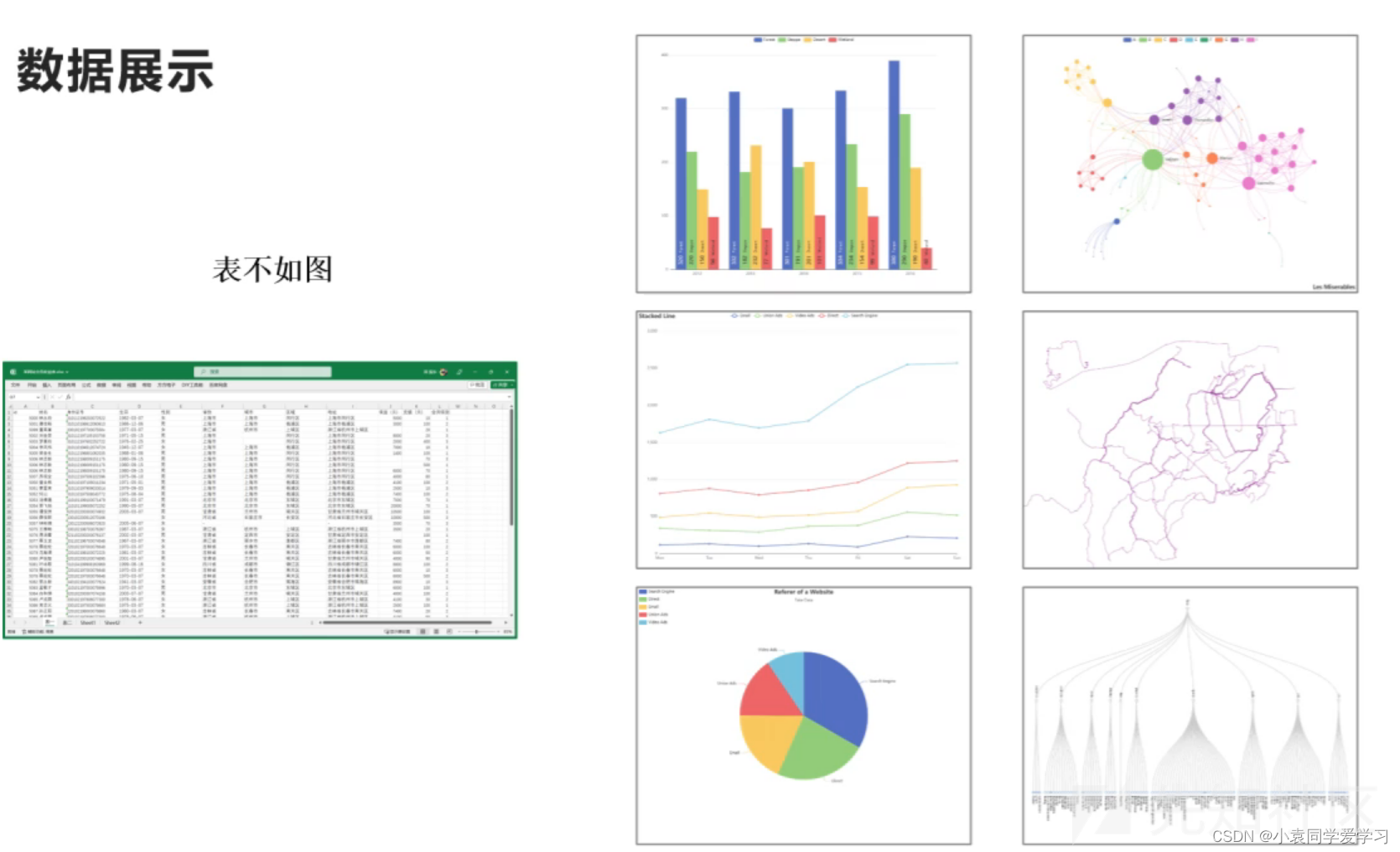
数据展现:表不如图
环境搭建
python+jupyter
anaconda
Jupyter Notebook
Jupyter Notebook可以在网页页面中直接编写代码和运行代码,
代码的运行结果也会直接在代码块下显示的程序。
整合所有的资源
交互性编程体验
零成本重现结果(云运行/在线运行)
运行方法
任意目录打开终端输入
jupyter-notebook
定义端口
jupyter-notebook -port 8899
更换目录
jupyter notebook -generate-config
数据加载与存储
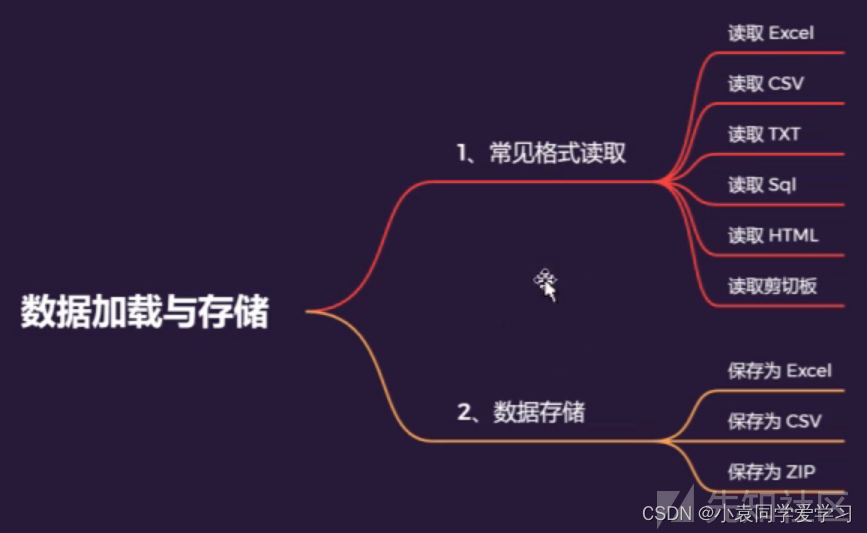
常见格式存储
import pandas as pd
pd.read_excel() # 从exce1的.xls或.xlsx格式读取表格数据
pd.read_csv()#从csv文件读取数据
pd.read_table() # 从txt文件读取数据
pd.read_sq1( )#将sql查询的结果(使用SQLAlchemy) 读取为pandas的DataF rame
pd.read_html( )#读取网页中的表格数据
pd. read_json( )#从json字符串中读取数据
pd.read_xml#从xml文件中读取数据
…………………………………………等等
格式转换
data=pd.read_excel(./1.xlsx)
data.to_csv(./1.csv)
pandas两大数据结构
Series:一维数据(列)
DataFrame:多维数据
常用函数
data. shape
#数据维度,看看数据多少行,多少列
data . head(3)
#检查头数据
data. info()
#查看数据基本信息
data. dtypes
#查看数据类型
data . describe( )
#查看数值数据统计信息
描述性统计分析
data[‘省份’]. unique
#显示某列所有的唯一值
data[‘省份’].value_ counts()
#返回每个元素有多少个
data[‘收益(元) ’ ] . idxmax()
#返回最大值所在索引
data .nlargest(3,‘收益(元)’)
#返回前几个大的元素值所在行
data. sort_ values (by=’’ ,ascending=‘’)
#根据某一列进行排序
查看指定多行、列、行列
data. columns. tolist( )
data[1:5]
data[[’ ip’ ,’ phone’ ] ]
data.loc[ ]
data. iloc []
方法名称 参数 说明 边界
.loc[] [row,columns] 基于标签索引选取数据 前闭后闭
.iloc[] [row,columns] 基于整数索引选取数据 前闭后开
缺失值检查与处理
缺失数据查看和修改
data[ data. isnull().values] #查看缺失值
data.dropna() #删除缺失值
data.fillna() #填充缺失值
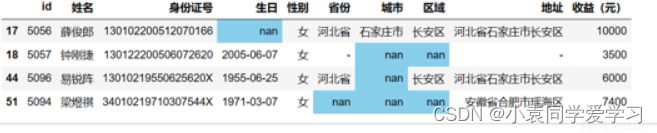
缺失数据高亮
#某网站会员收益表.xlsx
data.isna().sum().sum()
#检查全部缺失值总数
data.isnull().sum( )
#检查每列缺失值
#将缺失值进行高亮
(data[data.isnull().any(1) == True]
style
.highlight_null(nu11_color=‘skyblue’)
.set_table_attributes( ‘style=“font-size: 10px”’))
#填充固定值
datal = data.fillna(
data1
#向下填充
data2 = data. fillna(method=‘bfill’)
data2
#均值填充
data3 = data[‘收益(元)’ ].fillna(data[‘收益(元)’] .mean())
data3. map(lambda cell:‘%.2f’ % cel1)
#大多数时候,我们是从csv文件中导入的数据,此时Dataframe中对应的时间列是字符串或时间戳的形式
type(user[‘create_ time’ ][1])
#运用pd.to_ datetime().可以将对应的列转换为Pandas中的datetime64类型,便于后期的处理
user[ ‘create time’] = pd.to datetime(user[‘create_time’ ],unit=‘s’)
user[‘create_time’] = user[‘create_time’].map(lambda x : pd.to_datetime(x,unit=‘s’))
type(user['create_ time '][1])
#时间序列的索引。和普通索引一样,调用.1oc[row, columns ]进行索引
user1 = user .set_ index(‘create_time’ )
user1.1oc[‘2022-05’]
2022年5月 -2022年7月的数据
user1.1oc[ ’ 2022-05’: ‘2022-07’]
user[ create time’ ].dt.month
重复值检查与处理
data[data.duplicated()] #筛选重复值所在行
data[data.duplicated([‘姓名’])] #筛选指定列.
data.drop_duplicates() #删除重复值所在行
数据修改与筛选
#修改列名
df . rename( columns={
‘姓名’:‘中文名字’,
‘city’ : ’ birthday ’
})
#修改素引所在行
df.set_ index( ‘id’,inplace=True )
df.reset index(inplace=True)
df.drop([’ index’ ])
#修改索引名字
df.rename axis(’ 自加素引’)
#修改某一个值
df.iloc[0,1]=‘林1’
#替换指定的值
df.replace(3, 0, inplace=True )
df.replace(0,3, inplace=True)
df.replace(‘林永玲’ ,3, inplace=True )
df.iloc[0,1]=‘林永玲’
df.head(10)
df.drop(1)#删除指定行
df.drop(df[df[‘收益(元)’ ]>10000] . index)#删除条件行
df.drop(columns=[ ‘省份’], inplace=True )#删除列
df.drop(df.columns[[6,7,8]], axis=1, inplace=True )#删除列(按列号)
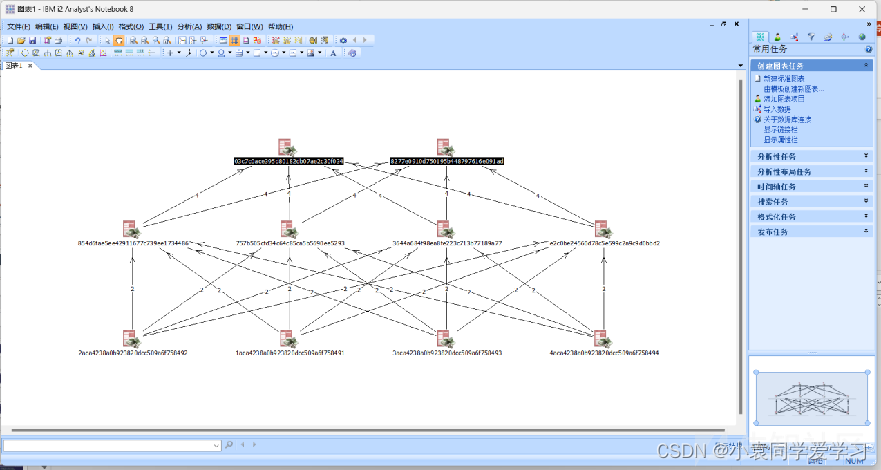
其它分析工具
OpenRefine
IBM i2