做网站总结与体会百度竞价排名什么意思
DeepLab复现的pytorch实现
本文复现的主要是deeplabv3。使用的数据集和之前发的文章FCN一样,没有了解的可以移步到之前发的文章中去查看一下。
1.该模型的主要结构
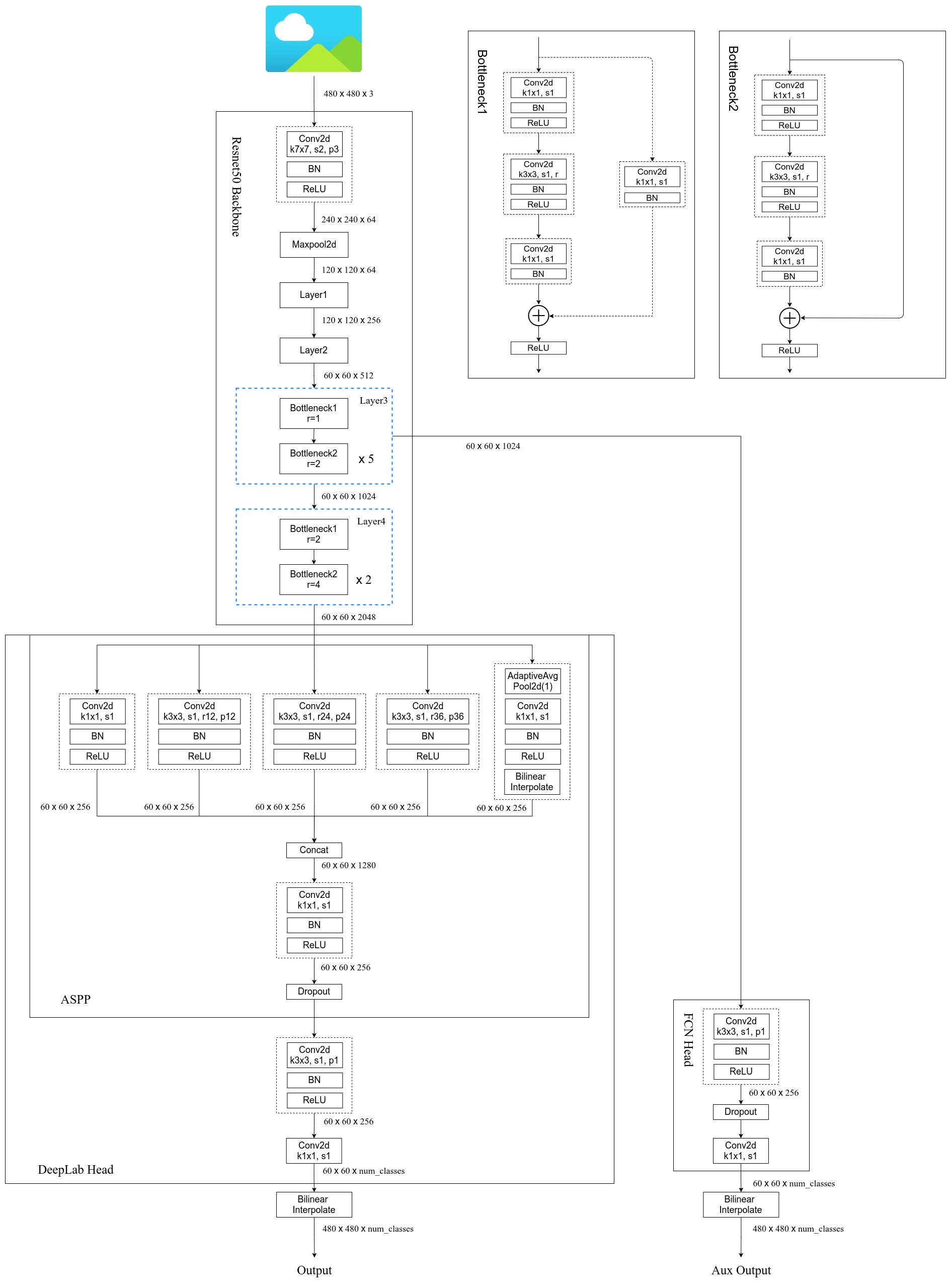
对于代码部分,主要只写了模型部分的,其他部分内容基本和FCN的一致,在下面也会给出完整代码仓库的地址方便大家进行学习。
from collections import OrderedDictfrom typing import Dict, Listimport torch
from torch import nn, Tensor
from torch.nn import functional as F
from .resnet_backbone import resnet50, resnet101
from .mobilenet_backbone import mobilenet_v3_largeclass IntermediateLayerGetter(nn.ModuleDict): # 获取模型指定的中间层输出"""Module wrapper that returns intermediate layers from a modelIt has a strong assumption that the modules have been registeredinto the model in the same order as they are used.This means that one should **not** reuse the same nn.Moduletwice in the forward if you want this to work.Additionally, it is only able to query submodules that are directlyassigned to the model. So if `model` is passed, `model.feature1` canbe returned, but not `model.feature1.layer2`.Args:model (nn.Module): model on which we will extract the featuresreturn_layers (Dict[name, new_name]): a dict containing the namesof the modules for which the activations will be returned asthe key of the dict, and the value of the dict is the nameof the returned activation (which the user can specify)."""_version = 2__annotations__ = {"return_layers": Dict[str, str],}def __init__(self, model: nn.Module, return_layers: Dict[str, str]) -> None:if not set(return_layers).issubset([name for name, _ in model.named_children()]):raise ValueError("return_layers are not present in model")orig_return_layers = return_layersreturn_layers = {str(k): str(v) for k, v in return_layers.items()}# 重新构建backbone,将没有使用到的模块全部删掉layers = OrderedDict()for name, module in model.named_children():layers[name] = moduleif name in return_layers:del return_layers[name]if not return_layers:breaksuper(IntermediateLayerGetter, self).__init__(layers)self.return_layers = orig_return_layersdef forward(self, x: Tensor) -> Dict[str, Tensor]:out = OrderedDict()for name, module in self.items():x = module(x)if name in self.return_layers:out_name = self.return_layers[name]out[out_name] = xreturn outclass DeepLabV3(nn.Module):"""Implements DeepLabV3 model from`"Rethinking Atrous Convolution for Semantic Image Segmentation"<https://arxiv.org/abs/1706.05587>`_.Args:backbone (nn.Module): the network used to compute the features for the model.The backbone should return an OrderedDict[Tensor], with the key being"out" for the last feature map used, and "aux" if an auxiliary classifieris used.classifier (nn.Module): module that takes the "out" element returned fromthe backbone and returns a dense prediction.aux_classifier (nn.Module, optional): auxiliary classifier used during training"""__constants__ = ['aux_classifier']def __init__(self, backbone, classifier, aux_classifier=None):super(DeepLabV3, self).__init__()self.backbone = backboneself.classifier = classifierself.aux_classifier = aux_classifierdef forward(self, x: Tensor) -> Dict[str, Tensor]:input_shape = x.shape[-2:]# contract: features is a dict of tensorsfeatures = self.backbone(x)result = OrderedDict()x = features["out"]x = self.classifier(x)# 使用双线性插值还原回原图尺度x = F.interpolate(x, size=input_shape, mode='bilinear', align_corners=False)result["out"] = xif self.aux_classifier is not None:x = features["aux"]x = self.aux_classifier(x)# 使用双线性插值还原回原图尺度x = F.interpolate(x, size=input_shape, mode='bilinear', align_corners=False)result["aux"] = xreturn resultclass FCNHead(nn.Sequential):def __init__(self, in_channels, channels):inter_channels = in_channels // 4 # 两个//表示地板除,即先做除法,然后向下取整super(FCNHead, self).__init__(nn.Conv2d(in_channels, inter_channels, 3, padding=1, bias=False),nn.BatchNorm2d(inter_channels),nn.ReLU(),nn.Dropout(0.1),nn.Conv2d(inter_channels, channels, 1))class ASPPConv(nn.Sequential):def __init__(self, in_channels: int, out_channels: int, dilation: int) -> None:super(ASPPConv, self).__init__(nn.Conv2d(in_channels, out_channels, 3, padding=dilation, dilation=dilation, bias=False),nn.BatchNorm2d(out_channels),nn.ReLU())class ASPPPooling(nn.Sequential):def __init__(self, in_channels: int, out_channels: int) -> None:super(ASPPPooling, self).__init__(nn.AdaptiveAvgPool2d(1),nn.Conv2d(in_channels, out_channels, 1, bias=False),nn.BatchNorm2d(out_channels),nn.ReLU())def forward(self, x: torch.Tensor) -> torch.Tensor:size = x.shape[-2:]for mod in self:x = mod(x)return F.interpolate(x, size=size, mode='bilinear', align_corners=False)class ASPP(nn.Module):def __init__(self, in_channels: int, atrous_rates: List[int], out_channels: int = 256) -> None:super(ASPP, self).__init__()modules = [nn.Sequential(nn.Conv2d(in_channels, out_channels, 1, bias=False),nn.BatchNorm2d(out_channels),nn.ReLU())]rates = tuple(atrous_rates)for rate in rates:modules.append(ASPPConv(in_channels, out_channels, rate))modules.append(ASPPPooling(in_channels, out_channels))self.convs = nn.ModuleList(modules)self.project = nn.Sequential(nn.Conv2d(len(self.convs) * out_channels, out_channels, 1, bias=False),nn.BatchNorm2d(out_channels),nn.ReLU(),nn.Dropout(0.5))def forward(self, x: torch.Tensor) -> torch.Tensor:_res = []for conv in self.convs:_res.append(conv(x))res = torch.cat(_res, dim=1)return self.project(res)class DeepLabHead(nn.Sequential):def __init__(self, in_channels: int, num_classes: int) -> None:super(DeepLabHead, self).__init__(ASPP(in_channels, [12, 24, 36]),nn.Conv2d(256, 256, 3, padding=1, bias=False),nn.BatchNorm2d(256),nn.ReLU(),nn.Conv2d(256, num_classes, 1))def deeplabv3_resnet50(aux, num_classes=21, pretrain_backbone=False):# 'resnet50_imagenet': 'https://download.pytorch.org/models/resnet50-0676ba61.pth'# 'deeplabv3_resnet50_coco': 'https://download.pytorch.org/models/deeplabv3_resnet50_coco-cd0a2569.pth'backbone = resnet50(replace_stride_with_dilation=[False, True, True])if pretrain_backbone:# 载入resnet50 backbone预训练权重backbone.load_state_dict(torch.load("resnet50.pth", map_location='cpu'))out_inplanes = 2048aux_inplanes = 1024return_layers = {'layer4': 'out'}if aux:return_layers['layer3'] = 'aux'backbone = IntermediateLayerGetter(backbone, return_layers=return_layers)aux_classifier = None# why using aux: https://github.com/pytorch/vision/issues/4292if aux:aux_classifier = FCNHead(aux_inplanes, num_classes)classifier = DeepLabHead(out_inplanes, num_classes)model = DeepLabV3(backbone, classifier, aux_classifier)return modeldef deeplabv3_resnet101(aux, num_classes=21, pretrain_backbone=False):# 'resnet101_imagenet': 'https://download.pytorch.org/models/resnet101-63fe2227.pth'# 'deeplabv3_resnet101_coco': 'https://download.pytorch.org/models/deeplabv3_resnet101_coco-586e9e4e.pth'backbone = resnet101(replace_stride_with_dilation=[False, True, True])if pretrain_backbone:# 载入resnet101 backbone预训练权重backbone.load_state_dict(torch.load("resnet101.pth", map_location='cpu'))out_inplanes = 2048aux_inplanes = 1024return_layers = {'layer4': 'out'}if aux:return_layers['layer3'] = 'aux'backbone = IntermediateLayerGetter(backbone, return_layers=return_layers)aux_classifier = None# why using aux: https://github.com/pytorch/vision/issues/4292if aux:aux_classifier = FCNHead(aux_inplanes, num_classes)classifier = DeepLabHead(out_inplanes, num_classes)model = DeepLabV3(backbone, classifier, aux_classifier)return modeldef deeplabv3_mobilenetv3_large(aux, num_classes=21, pretrain_backbone=False):# 'mobilenetv3_large_imagenet': 'https://download.pytorch.org/models/mobilenet_v3_large-8738ca79.pth'# 'depv3_mobilenetv3_large_coco': "https://download.pytorch.org/models/deeplabv3_mobilenet_v3_large-fc3c493d.pth"backbone = mobilenet_v3_large(dilated=True)if pretrain_backbone:# 载入mobilenetv3 large backbone预训练权重backbone.load_state_dict(torch.load("mobilenet_v3_large.pth", map_location='cpu'))backbone = backbone.features# Gather the indices of blocks which are strided. These are the locations of C1, ..., Cn-1 blocks.# The first and last blocks are always included because they are the C0 (conv1) and Cn.stage_indices = [0] + [i for i, b in enumerate(backbone) if getattr(b, "is_strided", False)] + [len(backbone) - 1]out_pos = stage_indices[-1] # use C5 which has output_stride = 16out_inplanes = backbone[out_pos].out_channelsaux_pos = stage_indices[-4] # use C2 here which has output_stride = 8aux_inplanes = backbone[aux_pos].out_channelsreturn_layers = {str(out_pos): "out"}if aux:return_layers[str(aux_pos)] = "aux"backbone = IntermediateLayerGetter(backbone, return_layers=return_layers)aux_classifier = None# why using aux: https://github.com/pytorch/vision/issues/4292if aux:aux_classifier = FCNHead(aux_inplanes, num_classes)classifier = DeepLabHead(out_inplanes, num_classes)model = DeepLabV3(backbone, classifier, aux_classifier)return model----------------------------------------------------------------------------------分割线-------------------------------------------from typing import Callable, List, Optionalimport torch
from torch import nn, Tensor
from torch.nn import functional as F
from functools import partialdef _make_divisible(ch, divisor=8, min_ch=None): # 为了使每一层的通道数都可以被8整除"""This function is taken from the original tf repo.It ensures that all layers have a channel number that is divisible by 8It can be seen here:https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py"""if min_ch is None:min_ch = divisornew_ch = max(min_ch, int(ch + divisor / 2) // divisor * divisor)# Make sure that round down does not go down by more than 10%.if new_ch < 0.9 * ch:new_ch += divisorreturn new_chclass ConvBNActivation(nn.Sequential):def __init__(self,in_planes: int,out_planes: int,kernel_size: int = 3,stride: int = 1,groups: int = 1,norm_layer: Optional[Callable[..., nn.Module]] = None,activation_layer: Optional[Callable[..., nn.Module]] = None,dilation: int = 1):padding = (kernel_size - 1) // 2 * dilationif norm_layer is None:norm_layer = nn.BatchNorm2dif activation_layer is None:activation_layer = nn.ReLU6super(ConvBNActivation, self).__init__(nn.Conv2d(in_channels=in_planes,out_channels=out_planes,kernel_size=kernel_size,stride=stride,dilation=dilation,padding=padding,groups=groups,bias=False),norm_layer(out_planes),activation_layer(inplace=True))self.out_channels = out_planesclass SqueezeExcitation(nn.Module):def __init__(self, input_c: int, squeeze_factor: int = 4):super(SqueezeExcitation, self).__init__()squeeze_c = _make_divisible(input_c // squeeze_factor, 8)self.fc1 = nn.Conv2d(input_c, squeeze_c, 1)self.fc2 = nn.Conv2d(squeeze_c, input_c, 1)def forward(self, x: Tensor) -> Tensor:scale = F.adaptive_avg_pool2d(x, output_size=(1, 1))scale = self.fc1(scale)scale = F.relu(scale, inplace=True)scale = self.fc2(scale)scale = F.hardsigmoid(scale, inplace=True)return scale * xclass InvertedResidualConfig:def __init__(self,input_c: int,kernel: int,expanded_c: int,out_c: int,use_se: bool,activation: str,stride: int,dilation: int,width_multi: float):self.input_c = self.adjust_channels(input_c, width_multi)self.kernel = kernelself.expanded_c = self.adjust_channels(expanded_c, width_multi)self.out_c = self.adjust_channels(out_c, width_multi)self.use_se = use_seself.use_hs = activation == "HS" # whether using h-swish activationself.stride = strideself.dilation = dilation@staticmethoddef adjust_channels(channels: int, width_multi: float):return _make_divisible(channels * width_multi, 8)class InvertedResidual(nn.Module):def __init__(self,cnf: InvertedResidualConfig,norm_layer: Callable[..., nn.Module]):super(InvertedResidual, self).__init__()if cnf.stride not in [1, 2]:raise ValueError("illegal stride value.")self.use_res_connect = (cnf.stride == 1 and cnf.input_c == cnf.out_c)layers: List[nn.Module] = []activation_layer = nn.Hardswish if cnf.use_hs else nn.ReLU# expandif cnf.expanded_c != cnf.input_c:layers.append(ConvBNActivation(cnf.input_c,cnf.expanded_c,kernel_size=1,norm_layer=norm_layer,activation_layer=activation_layer))# depthwisestride = 1 if cnf.dilation > 1 else cnf.stridelayers.append(ConvBNActivation(cnf.expanded_c,cnf.expanded_c,kernel_size=cnf.kernel,stride=stride,dilation=cnf.dilation,groups=cnf.expanded_c,norm_layer=norm_layer,activation_layer=activation_layer))if cnf.use_se:layers.append(SqueezeExcitation(cnf.expanded_c))# projectlayers.append(ConvBNActivation(cnf.expanded_c,cnf.out_c,kernel_size=1,norm_layer=norm_layer,activation_layer=nn.Identity))self.block = nn.Sequential(*layers)self.out_channels = cnf.out_cself.is_strided = cnf.stride > 1def forward(self, x: Tensor) -> Tensor:result = self.block(x)if self.use_res_connect:result += xreturn resultclass MobileNetV3(nn.Module):def __init__(self,inverted_residual_setting: List[InvertedResidualConfig],last_channel: int,num_classes: int = 1000,block: Optional[Callable[..., nn.Module]] = None,norm_layer: Optional[Callable[..., nn.Module]] = None):super(MobileNetV3, self).__init__()if not inverted_residual_setting:raise ValueError("The inverted_residual_setting should not be empty.")elif not (isinstance(inverted_residual_setting, List) andall([isinstance(s, InvertedResidualConfig) for s in inverted_residual_setting])):raise TypeError("The inverted_residual_setting should be List[InvertedResidualConfig]")if block is None:block = InvertedResidualif norm_layer is None:norm_layer = partial(nn.BatchNorm2d, eps=0.001, momentum=0.01)layers: List[nn.Module] = []# building first layerfirstconv_output_c = inverted_residual_setting[0].input_clayers.append(ConvBNActivation(3,firstconv_output_c,kernel_size=3,stride=2,norm_layer=norm_layer,activation_layer=nn.Hardswish))# building inverted residual blocksfor cnf in inverted_residual_setting:layers.append(block(cnf, norm_layer))# building last several layerslastconv_input_c = inverted_residual_setting[-1].out_clastconv_output_c = 6 * lastconv_input_clayers.append(ConvBNActivation(lastconv_input_c,lastconv_output_c,kernel_size=1,norm_layer=norm_layer,activation_layer=nn.Hardswish))self.features = nn.Sequential(*layers)self.avgpool = nn.AdaptiveAvgPool2d(1)self.classifier = nn.Sequential(nn.Linear(lastconv_output_c, last_channel),nn.Hardswish(inplace=True),nn.Dropout(p=0.2, inplace=True),nn.Linear(last_channel, num_classes))# initial weightsfor m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode="fan_out")if m.bias is not None:nn.init.zeros_(m.bias)elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):nn.init.ones_(m.weight)nn.init.zeros_(m.bias)elif isinstance(m, nn.Linear):nn.init.normal_(m.weight, 0, 0.01)nn.init.zeros_(m.bias)def _forward_impl(self, x: Tensor) -> Tensor:x = self.features(x)x = self.avgpool(x)x = torch.flatten(x, 1)x = self.classifier(x)return xdef forward(self, x: Tensor) -> Tensor:return self._forward_impl(x)def mobilenet_v3_large(num_classes: int = 1000,reduced_tail: bool = False,dilated: bool = False) -> MobileNetV3:"""Constructs a large MobileNetV3 architecture from"Searching for MobileNetV3" <https://arxiv.org/abs/1905.02244>.weights_link:https://download.pytorch.org/models/mobilenet_v3_large-8738ca79.pthArgs:num_classes (int): number of classesreduced_tail (bool): If True, reduces the channel counts of all feature layersbetween C4 and C5 by 2. It is used to reduce the channel redundancy in thebackbone for Detection and Segmentation.dilated: whether using dilated conv"""width_multi = 1.0bneck_conf = partial(InvertedResidualConfig, width_multi=width_multi)adjust_channels = partial(InvertedResidualConfig.adjust_channels, width_multi=width_multi)reduce_divider = 2 if reduced_tail else 1dilation = 2 if dilated else 1inverted_residual_setting = [# input_c, kernel, expanded_c, out_c, use_se, activation, stride, dilationbneck_conf(16, 3, 16, 16, False, "RE", 1, 1),bneck_conf(16, 3, 64, 24, False, "RE", 2, 1), # C1bneck_conf(24, 3, 72, 24, False, "RE", 1, 1),bneck_conf(24, 5, 72, 40, True, "RE", 2, 1), # C2bneck_conf(40, 5, 120, 40, True, "RE", 1, 1),bneck_conf(40, 5, 120, 40, True, "RE", 1, 1),bneck_conf(40, 3, 240, 80, False, "HS", 2, 1), # C3bneck_conf(80, 3, 200, 80, False, "HS", 1, 1),bneck_conf(80, 3, 184, 80, False, "HS", 1, 1),bneck_conf(80, 3, 184, 80, False, "HS", 1, 1),bneck_conf(80, 3, 480, 112, True, "HS", 1, 1),bneck_conf(112, 3, 672, 112, True, "HS", 1, 1),bneck_conf(112, 5, 672, 160 // reduce_divider, True, "HS", 2, dilation), # C4bneck_conf(160 // reduce_divider, 5, 960 // reduce_divider, 160 // reduce_divider, True, "HS", 1, dilation),bneck_conf(160 // reduce_divider, 5, 960 // reduce_divider, 160 // reduce_divider, True, "HS", 1, dilation),]last_channel = adjust_channels(1280 // reduce_divider) # C5return MobileNetV3(inverted_residual_setting=inverted_residual_setting,last_channel=last_channel,num_classes=num_classes)def mobilenet_v3_small(num_classes: int = 1000,reduced_tail: bool = False,dilated: bool = False) -> MobileNetV3:"""Constructs a large MobileNetV3 architecture from"Searching for MobileNetV3" <https://arxiv.org/abs/1905.02244>.weights_link:https://download.pytorch.org/models/mobilenet_v3_small-047dcff4.pthArgs:num_classes (int): number of classesreduced_tail (bool): If True, reduces the channel counts of all feature layersbetween C4 and C5 by 2. It is used to reduce the channel redundancy in thebackbone for Detection and Segmentation.dilated: whether using dilated conv"""width_multi = 1.0bneck_conf = partial(InvertedResidualConfig, width_multi=width_multi)adjust_channels = partial(InvertedResidualConfig.adjust_channels, width_multi=width_multi)reduce_divider = 2 if reduced_tail else 1dilation = 2 if dilated else 1inverted_residual_setting = [# input_c, kernel, expanded_c, out_c, use_se, activation, stride, dilationbneck_conf(16, 3, 16, 16, True, "RE", 2, 1), # C1bneck_conf(16, 3, 72, 24, False, "RE", 2, 1), # C2bneck_conf(24, 3, 88, 24, False, "RE", 1, 1),bneck_conf(24, 5, 96, 40, True, "HS", 2, 1), # C3bneck_conf(40, 5, 240, 40, True, "HS", 1, 1),bneck_conf(40, 5, 240, 40, True, "HS", 1, 1),bneck_conf(40, 5, 120, 48, True, "HS", 1, 1),bneck_conf(48, 5, 144, 48, True, "HS", 1, 1),bneck_conf(48, 5, 288, 96 // reduce_divider, True, "HS", 2, dilation), # C4bneck_conf(96 // reduce_divider, 5, 576 // reduce_divider, 96 // reduce_divider, True, "HS", 1, dilation),bneck_conf(96 // reduce_divider, 5, 576 // reduce_divider, 96 // reduce_divider, True, "HS", 1, dilation)]last_channel = adjust_channels(1024 // reduce_divider) # C5return MobileNetV3(inverted_residual_setting=inverted_residual_setting,last_channel=last_channel,num_classes=num_classes)在上述代码中,也将之前FCNmodel中没有的mobilenet作为backbone的模型代码也加了上来。
参考链接:
288, 96 // reduce_divider, True, “HS”, 2, dilation), # C4
bneck_conf(96 // reduce_divider, 5, 576 // reduce_divider, 96 // reduce_divider, True, “HS”, 1, dilation),
bneck_conf(96 // reduce_divider, 5, 576 // reduce_divider, 96 // reduce_divider, True, “HS”, 1, dilation)
]
last_channel = adjust_channels(1024 // reduce_divider) # C5
return MobileNetV3(inverted_residual_setting=inverted_residual_setting,last_channel=last_channel,num_classes=num_classes)
在上述代码中,也将之前FCNmodel中没有的mobilenet作为backbone的模型代码也加了上来。参考链接:[deep-learning-for-image-processing/pytorch_segmentation/fcn/src/fcn_model.py at bf4384bfc14e295fdbdc967d6b5093cce0bead17 · WZMIAOMIAO/deep-learning-for-image-processing (github.com)](https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/blob/bf4384bfc14e295fdbdc967d6b5093cce0bead17/pytorch_segmentation/fcn/src/fcn_model.py)