网站建设:竞价排名的弊端
前言
这次的是一个系列内容给大家讲解一下何一步一步实现一个完整的实战项目案例系列之小说下载神器(二)(GUI界面化程序)单章小说下载保存数据——整本小说下载
你有看小说“中毒”的经历嘛?小编多多少少还是爱看小说的,如果喜欢看小说分等级的话,我
可能得排到前三啦~嘻嘻嘻.jpg
所有文章完整的素材+源码都在👇👇
粉丝白嫖源码福利,请移步至CSDN社区或文末公众hao即可免费。

今天的内容还是延续上一期的内容,接着来给大家写小说下载器的系列啦~
上一期学了🤔:
爬虫基本思路流程——单章小说下载,发送请求&获取数据——单章小说下载—解析数据。
这一期教大家👍:
单章小说下载保存数据——整本小说下载。
好啦,话不多说,我们开始今天的主题吧👌👌

正文
一、运行环境
1)环境运行
Python3、Pycharm社区版; requests、 parsel第三方库,部分自带的模块安装完Python可
以直接使用不需要安装。
一般安装:pip install +模块名镜像源安装:pip install -i https://pypi.douban.com/simple/+模块名二、单章小说下载&保存数据
1)代码实现
# 导入数据请求模块 --> 第三方模块, 需要安装
import requests
# 导入正则表达式模块 --> 内置模块, 不需要安装
import re
# 导入数据解析模块 --> 第三方模块, 需要安装
import parsel"""
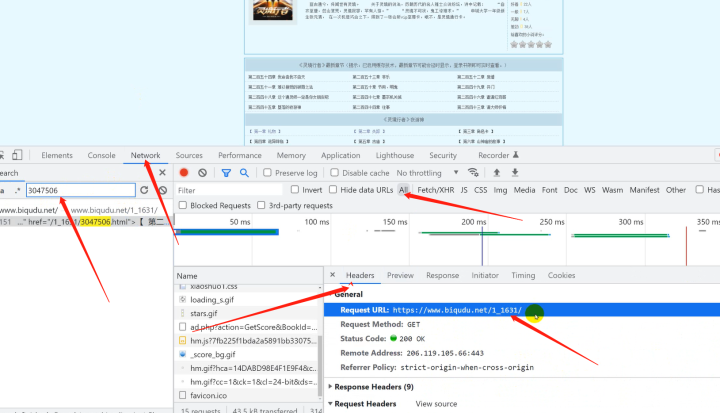
1. 发送请求, 模拟浏览器对于url地址发送请求请求链接: https://www.biqudu.net/1_1631/3047505.html安装模块方法:- win + R 输入cmd, 输入安装命令 pip install requests- 在pycharm终端, 输入安装命令模拟浏览器 headers 请求头:字典数据结构AttributeError: 'set' object has no attribute 'items' 因为headers不是字典数据类型, 而是set集合
"""
# 请求链接
url = 'https://www.biqudu.net/1_1631/3047505.html'
# 模拟浏览器 headers 请求头
headers = {# user-agent 用户代理 表示浏览器基本身份信息'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
# 发送请求
response = requests.get(url=url, headers=headers)
# <Response [200]> 响应对象, 表示请求成功
print(response)
"""
2. 获取数据, 获取服务器返回响应数据内容开发者工具: responseresponse.text --> 获取响应文本数据 <网页源代码/html字符串数据>
3. 解析数据, 提取我们想要的数据内容标题/内容re正则表达式: 是直接对于字符串数据进行解析re.findall('什么数据', '什么地方') --> 从什么地方, 去找什么数据.*? --> 可以匹配任意数据, 除了\n换行符# 提取标题title = re.findall('<h1>(.*?)</h1>', response.text)[0]# 提取内容content = re.finall('<div id="content">(.*?)<p>', response.text, re.S)[0].replace('<br/><br/>', '\n')css选择器: 根据标签属性提取数据.bookname h1::text类名为bookname下面h1标签里面文本get() --> 提取第一个标签数据内容 返回字符串getall() --> 提取多个数据, 返回列表# 提取标题title = selector.css('.bookname h1::text').get()# 提取内容content = '\n'.join(selector.css('#content::text').getall())xpath节点提取: 提取标签节点提取数据"""
# 获取下来response.text <html字符串数据>, 转成可解析对象
selector = parsel.Selector(response.text)
# 提取标题
title = selector.xpath('//*[@class="bookname"]/h1/text()').get()
# 提取内容
content = '\n'.join(selector.xpath('//*[@id="content"]/text()').getall())
print(title)
print(content)
# title <文件名> '.txt' 文件格式 a 追加保存 encoding 编码格式 as 重命名
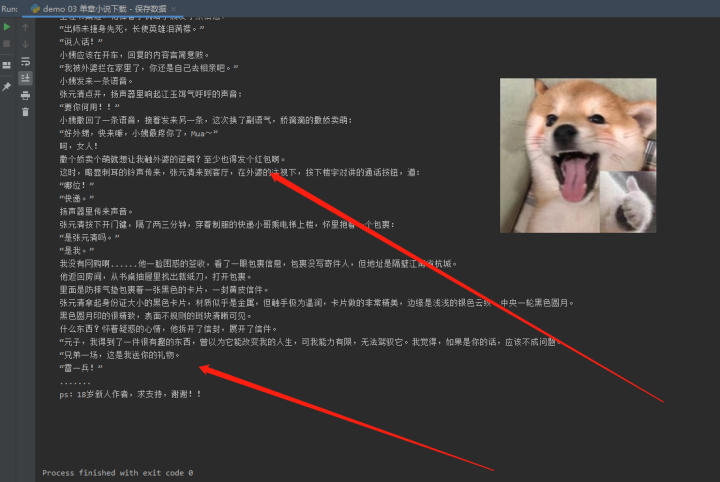
with open(title + '.txt', mode='a', encoding='utf-8') as f:"""第一章 标题小说内容第二章 标题小说内容"""# 写入内容f.write(title)f.write('\n')f.write(content)f.write('\n')2)效果展示
单章小说下载保存——
三、整本小说下载
请求链接:小说目录页
1)代码实现
"""
# 导入数据请求模块 --> 第三方模块, 需要安装
import requests
# 导入正则表达式模块 --> 内置模块, 不需要安装
import re
# 导入数据解析模块 --> 第三方模块, 需要安装
import parsel
# 导入文件操作模块 --> 内置模块, 不需要安装
import os# 请求链接: 小说目录页
list_url = 'https://www.biqudu.net/1_1631/'
# 模拟浏览器 headers 请求头
headers = {# user-agent 用户代理 表示浏览器基本身份信息'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
# 发送请求
html_data = requests.get(url=list_url, headers=headers).text
# 提取小说名字
name = re.findall('<h1>(.*?)</h1>', html_data)[0]
# 自动创建一个文件夹
file = f'{name}\\'
if not os.path.exists(file):os.mkdir(file)# 提取章节url
url_list = re.findall('<dd> <a style="" href="(.*?)">', html_data)
# for循环遍历
for url in url_list:index_url = 'https://www.biqudu.net' + urlprint(index_url)"""1. 发送请求, 模拟浏览器对于url地址发送请求请求链接: https://www.biqudu.net/1_1631/3047505.html安装模块方法:- win + R 输入cmd, 输入安装命令 pip install requests- 在pycharm终端, 输入安装命令模拟浏览器 headers 请求头:字典数据结构AttributeError: 'set' object has no attribute 'items'因为headers不是字典数据类型, 而是set集合"""# # 请求链接# url = 'https://www.biqudu.net/1_1631/3047506.html'# 模拟浏览器 headers 请求头headers = {# user-agent 用户代理 表示浏览器基本身份信息'user-agent': 'Mozlla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'}# 发送请求response = requests.get(url=index_url, headers=headers)# <Response [200]> 响应对象, 表示请求成功print(response)"""2. 获取数据, 获取服务器返回响应数据内容开发者工具: responseresponse.text --> 获取响应文本数据 <网页源代码/html字符串数据>3. 解析数据, 提取我们想要的数据内容标题/内容re正则表达式: 是直接对于字符串数据进行解析re.findall('什么数据', '什么地方') --> 从什么地方, 去找什么数据.*? --> 可以匹配任意数据, 除了\n换行符# 提取标题title = re.findall('<h1>(.*?)</h1>', response.text)[0]# 提取内容content = re.findall('<div id="content">(.*?)<p>', response.text, re.S)[0].replace('<br/><br/>', '\n')css选择器: 根据标签属性提取数据.bookname h1::text类名为bookname下面h1标签里面文本get() --> 提取第一个标签数据内容 返回字符串getall() --> 提取多个数据, 返回列表# 提取标题title = selector.css('.bookname h1::text').get()# 提取内容content = '\n'.join(selector.css('#content::text').getall())xpath节点提取: 提取标签节点提取数据"""# 获取下来response.text <html字符串数据>, 转成可解析对象selector = parsel.Selector(response.text)# 提取标题title = selector.xpath('//*[@class="bookname"]/h1/text()').get()# 提取内容content = '\n'.join(selector.xpath('//*[@id="content"]/text()').getall())print(title)# print(content)# title <文件名> '.txt' 文件格式 a 追加保存 encoding 编码格式 as 重命名with open(file + title + '.txt', mode='a', encoding='utf-8') as f:"""第一章 标题小说内容第二章 标题小说内容"""# 写入内容f.write(title)f.write('\n')f.write(content)f.write('\n') 2)效果展示
2)效果展示
下载中——
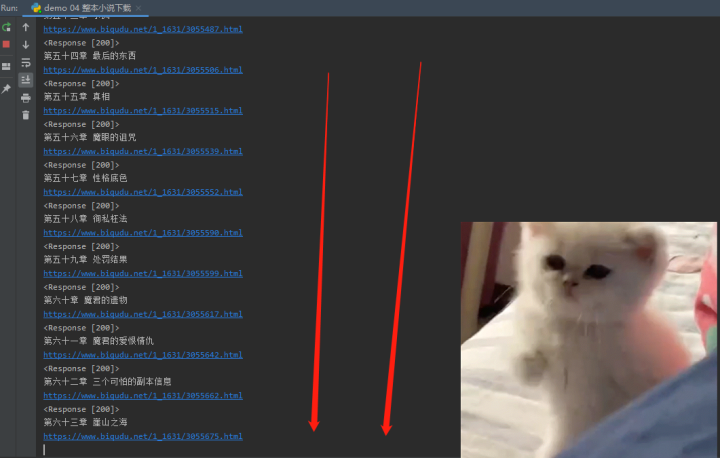
整本小说下载——
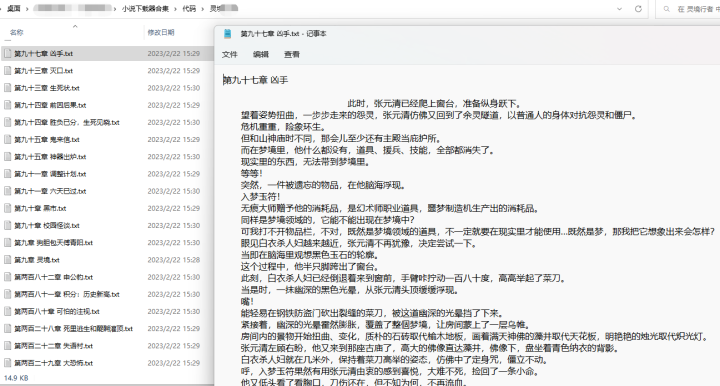
总结
好啦!今天的内容就先写到这里,一步一步来蛮,现在我们已经从零基础开始讲解,到现在能
独自一个人下载一整本小说啦,下一期我们讲一讲不同的方式采集小说以及尝试更难一点儿
的,采集整个页面出现的小说,下载多本小说呀~
✨完整的素材源码等:可以滴滴我吖!或者点击文末hao自取免费拿的哈~
🔨推荐往期文章——
项目1.0 小说下载神器(GUI界面)系列内容
Python实战之小说下载神器(一)看小说怎么能少了这款宝藏神器呢?全网小说书籍随便下,随便看,爆赞(你准备好了吗?)
项目1.6 【Python实战】听书就用它了:海量资源随便听,内含几w书源,绝对精品哦~
项目1.8 【Python实战】海量表情包炫酷来袭,快来pick斗图新姿势吧~(超好玩儿)
🎁文章汇总——
Python文章合集 | (入门到实战、游戏、Turtle、案例等)
(文章汇总还有更多你案例等你来学习啦~源码找我即可免费!)
