做网站中心百度电脑版下载官方
Kafka它本身其实不是一个金融级别数据可靠的分布式消息系统。
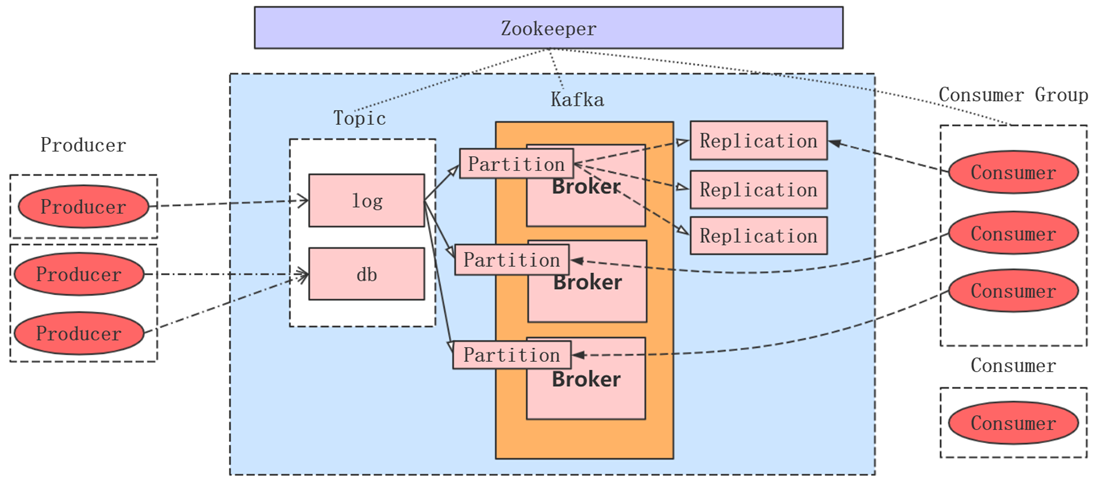 虽然说它存储到某个topic里的数据会先拆分多个partition,这体现了分治的一个思想。每一个partition在最终存储的时候会保存多个副本,不同的副本存储在不同的节点。这样的话任意一个节点挂掉,其实数据是不丢失的。
虽然说它存储到某个topic里的数据会先拆分多个partition,这体现了分治的一个思想。每一个partition在最终存储的时候会保存多个副本,不同的副本存储在不同的节点。这样的话任意一个节点挂掉,其实数据是不丢失的。
但实际上它是存在风险的,因为Kafka它利用了缓存。就是数据在真正落盘之前都要存在Block Case里进行缓存。以便增加磁盘的读写性能,缓存满了或者是失效了,缓存里的数据才会往磁盘里面进行溢写。
这种情况下就一定会带来风险,一旦你的集群断电了,缓存里的数据还没有来得及往磁盘溢写,那这个时候数据就丢失了。
当然在生产中可以有其他的选型,比如说RabbitMQ,它的性能大概是Kafka的一半甚至一半不到。它是数据直写磁盘的,这样的话它不存在数据安全性的问题。换来的代价是它的性能会下降,延迟会增加。
我们现在要做的是,在保证高性能的同时,还希望数据尽量不丢失。这能不能做到?当然能做到。
Kafka生产者产生数据进行消息发送,它会采用这种ack机制,去保证数据可靠性。Ack就是当生产者将数据写入到Kafka之后,Kafka会返回一个标志,这个标志叫ack。
min.insync.replicas
它这种ack的机制其实有三种级别,一种是默认级别,即将min.insync.replicas参数设置为1的时候。生产者只要将数据发送到leader副本,kafka就会返回ack,leader中的数据先在缓存中,数据写磁盘需要一段时间。这个过程中如果两个从副本没有同步数据,直接断电后就会丢数。
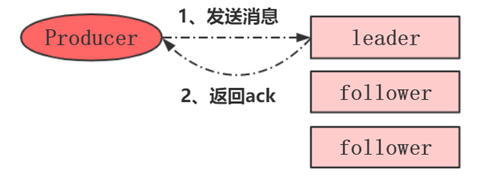
如果ack的级别配置成0,效率更高。不需要kafka返回任何ack的确认。这种的话性能更好,但是丢数的风险就更高。
当这种ack可以设为-1的时候,数据安全性是最高的。0安全级别最低,1安全级别中等。
-1这种情况是,当produce将数据发送到主副本以后,在ISR列表里面,也就是候选人列表中的从副本会立即从leader进行数据同步。完成数据同步以后,Kafka才会向生产者返回ack。生产者接收到ack后再继续发送其他的消息。
虽然说性能会有下降,但是数据可靠性提高了。
因为返回ack的时候,其实数据已经在多个节点里了。任意一个节点挂掉,其实对系统是没有影响的。
这里有一个细节,如果目前ISR里面的一个从副本,当它长时间与leader数据不同步,也就是落后了很多消息。超过一定时间之后它就会被移出ISR,ISR现在只剩一个从副本了。这个时候可靠性就会降级。
还有一种极端情况就是,两个follower都被移出ISR,ISR现在为空。这个时候ack这种-1级别,也被称为all级别,就降级成了1这个级别。
这种时候我们该怎么去限制?我们可以调整ISR最小副本数min.insync.replicas。
min.insync.replicas
这个参数它一定是配合ack等于all (-1)来使用。比如说min.insync.replicas限制为1,就是说ISR里面必须有1个副本,这样的话它才能保证数据的一个可靠性。如果小于1的话就是ISR为空,在生产者往Kafka里面写数据的时候就会报错。报NotEnoughReplicaseException异常。没有足够的副本,保证不了数据安全。
所以一般来说它俩是配合来使用的,避免ack=all降级为ack=1,能够提升我们数据安全级别。
ISR假设为空,或者小于最小副本数,生产者往Kafka写数据的时候一直会报错,不能说它一报错Kafka生产者就直接终止,我们肯定要设置一个重试次数,来提升程序的健壮性。
retries
即使我们ack开到all(-1),它数据还是先会写缓存,从副本同步的数据也在缓存里。当Kafka向生产者返回ack后,假设集群挂掉了。leader挂了,数据丢不丢失?不丢失,因为另外两个从副本也有数据。那现在整个集群同时宕机了,缓存中的数据肯定就都给清理掉了。就一定会出现数据丢失的情况。
所以我们也印证了前面说的,为什么Kafka它不是一个金融级别可用的,或者金融级别数据安全的消息系统。原因就在这里。
当然每个产品有它自己的使用场景,Kafka本身就是用来抗压的,它的性能越高越好,数据可靠性的要求要低一些。
这个时候有的同学就很矛盾了,我既想用Kafka的这种高性能高吞吐,但是我又不希望它丢数,我们换一种思路该怎么办?
先依赖Kafka,让它完成抗压的作用,数据可靠性既然不能依赖Kafka来完成,可以依赖谁来完成?依赖生产者。
生产者在将数据,向Kafka里写入的时候,能不能顺手将这个数据写到数据库里呢?比如Mysql。写入完成后再把数据推到Kafka中。
当然不写数据库也可以,可以先本地做备份,备份完以后再往Kafka里推送。一旦Kafka发生丢数,没关系,生产者可以拿到备份的数据进行补数操作。
如果补数的时候数据重复了,这个时候灵活一点,消费者这里是不是可以去重?就可以解决数据重复问题。
依赖kafka的高性能同时,尽量减少对kafka数据可靠性的依赖,并协调生产者与消费者去保障数据问题,这种解决方案能够满足生产上多数需求。
那Kafka的数据可靠性,就聊到这里,谢谢大家。