电话销售做网站认证网站设计软件
#AI夏令营
#Datawhale
#夏令营
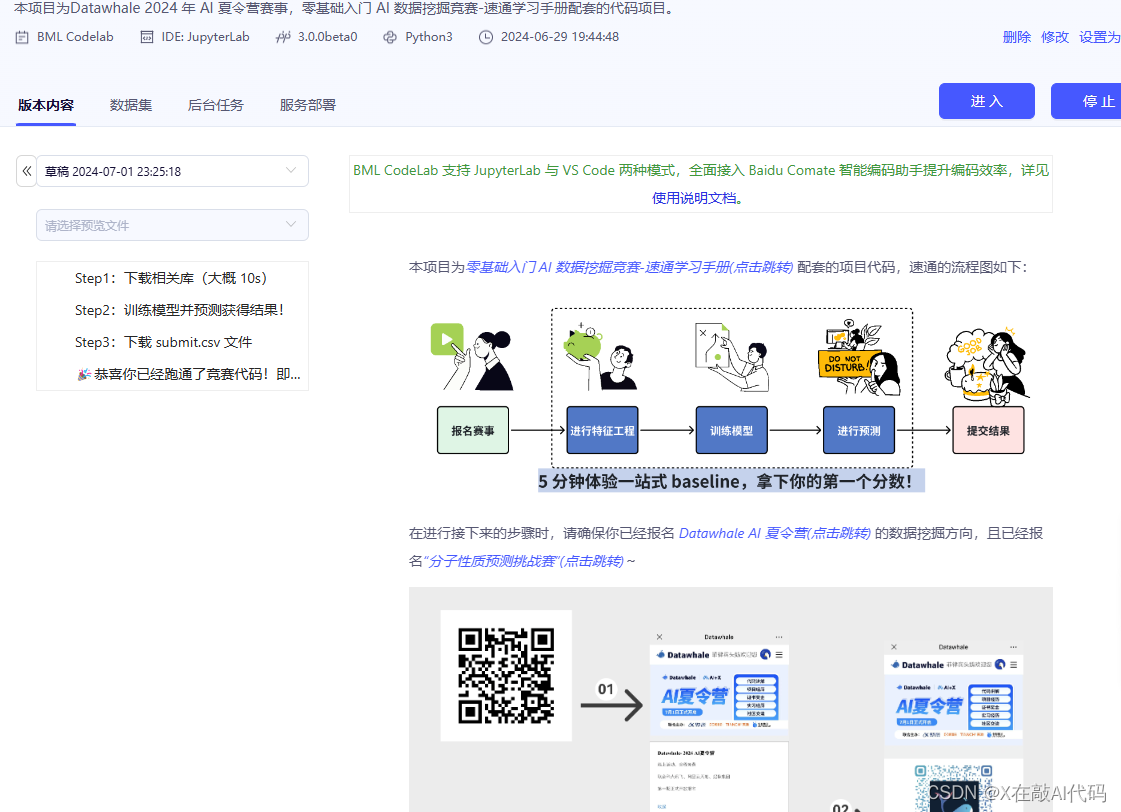
本项目为Datawhale 2024 年 AI 夏令营赛事,零基础入门 AI 数据挖掘竞赛-速通学习手册配套的代码项目。
项目链接:https://aistudio.baidu.com/bd-cpu-02/user/2961857/8113198/home#codelab
任务目标
根据给的test,train数据集,训练模型,从而 预测PROTACs的降解能力 (在demo中用label表示,0表示差,1表示好)
DC50>100nM&Dmax<80% -》Label=0
DC50<=100nM||Dmax>=80%-》Label=1)。
解题思路
1.选用机器学习方法,能达到和深度学习相同的结果,且更方便简捷
2.这里从逻辑回归和决策树中选择,哪一个模型更加合适?
逻辑回归的适用条件:
- 目标变量类型:
- 逻辑回归主要用于处理二分类问题,即目标变量是二元的,如是/非、成功/失败等。
- 输入变量类型:
- 逻辑回归可以处理连续变量、类别变量以及二进制变量。
- 数据分布假设:
- 逻辑回归通常假设数据服从伯努利分布,即目标变量服从二项分布。
- 线性关系:
- 逻辑回归假设自变量与对数几率的关系是线性的。
- 解释性:
- 逻辑回归模型相对简单,模型的输出可以解释为概率,因此在需要理解影响因素和解释模型结果时比较有优势。
决策树的适用条件:
- 目标变量类型:
- 决策树既可以处理分类问题,也可以处理回归问题。
- 输入变量类型:
- 决策树可以处理数值型数据 分类型数据 序数型数据和类别变量,不需要对数据做过多的预处理工作。
1.数值型数据:例如连续的浮点数或整数。
2.分类型数据:例如名义变量,通常是有限个数的离散取值,比如颜色、性别等。
3.序数型数据:具有顺序关系的分类型数据,比如教育程度(小学、中学、大学)。
- 决策树可以处理数值型数据 分类型数据 序数型数据和类别变量,不需要对数据做过多的预处理工作。
- 非线性关系:
- 决策树能够处理非线性关系,不需要对数据做线性假设。
- 解释性:
- 决策树的决策路径比较直观,易于理解和解释,能够呈现特征的重要性。
- 处理缺失值:
- 决策树能够自动处理缺失值,不需要额外的数据预处理步骤。
总结比较:
- 逻辑回归适合于简单的二分类问题,当数据满足线性关系假设时表现较好,适合作为基线模型进行比较和解释。
- 决策树则更适合处理复杂的非线性关系,能够处理多分类问题和回归问题,同时具备一定的解释性和容错性。
- 选择决策树
- 决策树能够处理非线性关系,并且可以自动捕获特征之间的交互作用。
- 它可以生成可解释的规则,有助于理解模型如何做出决策。
- 决策树能够处理不同类型的特征,包括分类和数值型。
决策树基本代码
# 导入必要的库
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score# 1. 准备数据
# 假设有一个名为 'data.csv' 的数据集,包含特征和标签# 读取数据集
data = pd.read_csv('data.csv')# 分离特征和标签
X = data.drop('target_column_name', axis=1) # 特征列
y = data['target_column_name'] # 标签列# 2. 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 3. 创建决策树模型
model = DecisionTreeClassifier()# 4. 训练模型
model.fit(X_train, y_train)# 5. 预测
y_pred = model.predict(X_test)# 6. 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')# 可选步骤:可视化决策树
# 如果需要可解释性,可以将训练好的模型可视化
# 可以使用 Graphviz 和 export_graphviz 方法
# 例如:from sklearn.tree import export_graphviz# 注意:上述代码中的 'target_column_name' 是你数据集中的目标列名,需要根据实际情况替换为正确的列名。LGB树模型
1.[LightGBM]是个快速的,分布式的,高性能的基于决策树算法的梯度提升框架。可用于排序,分类,回归以及很多其他的机器学习任务中。
2.LightGBM:跟之前常用的XGBoot在不降低准确率的前提下,速度提升了10倍左右,占用内存下降了3倍左右。
LightGBM通过引入高效的直方图算法来优化决策树的训练过程。传统的梯度提升算法(如GBoost)是按层生长(level-wise growth)的,而LightGBM则采用了按叶子生长(leaf-wise growth)的策略,这样能够更快地生成深度较少但分裂质量较高的决策树。
-LightGBM在构建每棵决策树时,还利用了特征的直方图信息,有效地减少了内存使用并提高了训练速度。这种优化对于处理大规模数据和高维特征特别有用。
原理
机器学习—LightGBM的原理、优化以及优缺点-CSDN博客
示例代码
# 导入必要的库
import lightgbm as lgb
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 1. 准备数据
# 假设有一个名为 'data.csv' 的数据集,包含特征和标签# 读取数据集
data = pd.read_csv('data.csv')# 分离特征和标签
X = data.drop('target_column_name', axis=1) # 特征列
y = data['target_column_name'] # 标签列# 2. 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 3. 创建LightGBM模型
params = {'boosting_type': 'gbdt', # 使用gbdt提升器'objective': 'binary', # 二分类任务'metric': 'binary_logloss', # 使用logloss作为评估指标'num_leaves': 31, # 每棵树的叶子节点数'learning_rate': 0.05, # 学习率'feature_fraction': 0.9, # 训练每棵树时使用的特征比例'bagging_fraction': 0.8, # 每轮迭代时用来训练模型的数据比例'bagging_freq': 5, # bagging的频率'verbose': 0 # 不显示训练过程中的输出信息
}lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)# 4. 训练模型
gbm = lgb.train(params,lgb_train,num_boost_round=100, # 迭代次数valid_sets=lgb_eval,early_stopping_rounds=10) # 当验证集的性能不再提升时停止训练# 5. 预测
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration)# 将预测概率转换为类别
y_pred_binary = [1 if pred > 0.5 else 0 for pred in y_pred]# 6. 评估模型
accuracy = accuracy_score(y_test, y_pred_binary)
print(f'Accuracy: {accuracy}')# 可选步骤:特征重要性分析
# gbm.feature_importance() 可以获取特征重要性完整代码
# 1. 导入需要用到的相关库
# 导入 pandas 库,用于数据处理和分析
import pandas as pd
# 导入 numpy 库,用于科学计算和多维数组操作
import numpy as np
# 从 lightgbm 模块中导入 LGBMClassifier 类
from lightgbm import LGBMClassifier# 2. 读取训练集和测试集
# 使用 read_excel() 函数从文件中读取训练集数据,文件名为 'traindata-new.xlsx'
train = pd.read_excel('./data/data280993/traindata-new.xlsx')
# 使用 read_excel() 函数从文件中读取测试集数据,文件名为 'testdata-new.xlsx'
test = pd.read_excel('./data/data280993/testdata-new.xlsx')# 3 特征工程
# 3.1 test数据不包含 DC50 (nM) 和 Dmax (%),将train数据中的DC50 (nM) 和 Dmax (%)删除
train = train.drop(['DC50 (nM)', 'Dmax (%)'], axis=1)# 3.2 将object类型的数据进行目标编码处理
for col in train.columns[2:]:if train[col].dtype == object or test[col].dtype == object:train[col] = train[col].isnull()test[col] = test[col].isnull()# 4. 加载决策树模型进行训练
model = LGBMClassifier(verbosity=-1)
model.fit(train.iloc[:, 2:].values, train['Label'])
pred = model.predict(test.iloc[:, 1:].values, )# 5. 保存结果文件到本地
pd.DataFrame({'uuid': test['uuid'],'Label': pred}
).to_csv('submit.csv', index=None)
model = LGBMClassifier(verbosity=-1)
model.fit(train.iloc[:, 2:].values, train['Label'])
pred = model.predict(test.iloc[:, 1:].values, )#1. `LGBMClassifier(verbosity=-1)` 创建了一个 LightGBM 分类模型,并设置了 `verbosity=-1`,表示禁止输出训练过程中的信息。#2. `model.fit(train.iloc[:, 2:].values, train['Label'])` 使用训练集 `train` 的特征列(从第三列开始,即 `train.iloc[:, 2:]`)和标签列(`train['Label']`)来训练模型。#3. `pred = model.predict(test.iloc[:, 1:].values)` 对测试集 `test` 的特征列(从第二列开始,即 `test.iloc[:, 1:]`)进行预测,并将预测结果存储在 `pred` 变量中。所以,这段代码的作用是利用 LightGBM 模型对测试集进行预测,并且假设测试集中的特征列是从第二列开始(因为使用了 `test.iloc[:, 1:]`)。