云南省建设厅网站飓风seo刷排名软件
安装
前往官网下载即可:https://nodejs.org/zh-cn
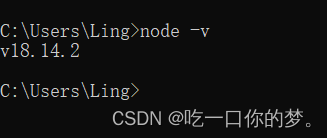
安装之后检查是否成功并查看版本,win+r --> 输入cmd --> 确认 --> 进入命令提示符窗口 --> 输入 node -v --> 出现以下就代表成功了,这也是node的版本号
什么是Node.js
- Node.js 是一个独立的JavaScript 运行环境,能独立执行 JS 代码,因为这个特点,它可以用来编写服务器后端的应用程序
- Node.js 作用除了编写后端应用程序,也可以对前端代码进行压缩,转译,整合等等,提高前端开发和运行效率
- Node.js 基于 Chrome V8 引擎封装,独立执行 JS 代码,但是语法和浏览器环境的 V8 有所不同,没有 document 和 window ,但是都支持 ECMAScript 标准的代码语法
- Node.js 没有图形化界面,需要使用 cmd 终端命令行(利用一些命令来操控电脑执行某些程序软件)输入,
node -v检查是否安装成功
fs模块 - 读写文件
-
模块:类似插件,封装了方法和属性供我们使用
-
fs 模块:封装了与本机文件系统进行交互的,方法和属性
-
fs 模块使用语法如下:
- 加载 fs 模块,得到 fs 对象
const fs = require('fs')- 写入文件内容语法:
fs.writeFile('文件路径', '写入内容', err => {// 写入后的回调函数})- 读取文件内容语法:
fs.readFile('文件路径', (err, data) => {// 读取后的回调函数// data 是文件内容的 Buffer 数据流}) -
需求:向 test.txt 文件写入内容并读取打印
/*** 目标:使用 fs 模块,读写文件内容* 语法:* 1. 引入 fs 模块* 2. 调用 writeFile 写入内容* 3. 调用 readFile 读取内容*/// 1. 引入 fs 模块const fs = require('fs')// 2. 调用 writeFile 写入内容// 注意:建议写入字符串内容,会覆盖目标文件所有内容fs.writeFile('./text.txt', '欢迎使用 fs 模块读写文件内容', err => {if (err) console.log(err)else console.log('写入成功')})// 3. 调用 readFile 读取内容fs.readFile('./text.txt', (err, data) => {if (err) console.log(err)else console.log(data.toString()) // 把 Buffer 数据流转成字符串类型})
path模块 - 路径处理
- 为什么在 Node.js 待执行的 JS 代码中要用绝对路径:
Node.js 执行 JS 代码时,代码中的路径都是以终端所在文件夹出发查找相对路径,而不是以我们认为的从代码本身触发,会遇到问题,所以在 Node.js 要执行的代码中,访问其他文件,建议使用绝对路径
- 新建 03 文件夹编写待执行的 JS 代码,访问外层相对路径下的文件,然后再最外层终端路径来执行目标文件,造成问题
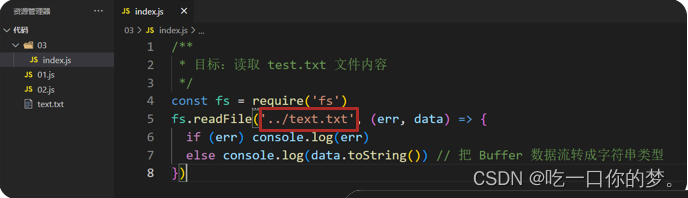
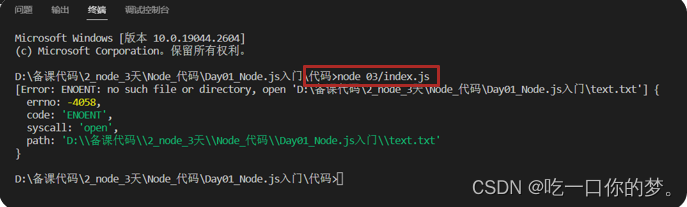
- 问题原因:就是从代码文件夹触发,使用
../text.txt解析路径,找不到目标文件,报错了! - 解决方案:使用模块内置变量
__dirname配合 path.join() 来得到绝对路径使用
const fs = require('fs')
console.log(__dirname) // D:\备课代码\2_node_3天\Node_代码\Day01_Node.js入门\代码\03// 1. 加载 path 模块
const path = require('path')
// 2. 使用 path.join() 来拼接路径
const pathStr = path.join(__dirname, '..', 'text.txt')
console.log(pathStr)fs.readFile(pathStr, (err, data) => {if (err) console.log(err)else console.log(data.toString())
})
补充:__dirname 内置变量(获取当前模块目录 - 绝对路径)
window:中间以 \,类似:D:\备课代码\3-B站课程\03_Node.js与Webpack\03-code\03
mac: 中间以 /,类似:/Users/xxx/Desktop/备课代码/3-B站课程/03_Node.js与Webpack/03-code/03
注意:path.join() 会使用特定于平台的分隔符,作为定界符,将所有给定的路径片段连接在一起
语法:
- 加载 path 模块
const path = require('path') - 使用 path.join 方法,拼接路径
path.join('路径1', '路径2', ...)
认识URL中的端口号
- URL 是统一资源定位符,简称网址,用于访问网络上的资源
- 端口好的作用:标记服务器里面对应的服务程序,值为(0 - 65535 之间的任意整数)
- 注意:http 协议,默认访问的是 80 端口
- Web 服务:一个程序,用于提供网上信息浏览功能
- 注意:0 - 1023 和一些特定的端口号被占用,我们自己编写服务程序请避开使用
http模块 - 创建Web服务
- 需求:引入 http 模块,使用相关语法,创建 Web 服务程序,响应返回给请求方一句提示
hello world - 步骤:
- 引入 http 模块,创建 Web 服务对象
- 监听 request 请求事件,对本次请求,做一些响应处理
- 启动 Web 服务监听对应端口号
- 运行本服务在终端进程中,用浏览器发起请求
- 注意:本机的域名叫做
localhost - 代码如下:
/*** 目标:基于 http 模块创建 Web 服务程序* 1.1 加载 http 模块,创建 Web 服务对象* 1.2 监听 request 请求事件,设置响应头和响应体* 1.3 配置端口号并启动 Web 服务* 1.4 浏览器请求(http://localhost:3000)测试*/// 1.1 加载 http 模块,创建 Web 服务对象const http = require('http')const server = http.createServer()// 1.2 监听 request 请求事件,设置响应头和响应体server.on('request', (req, res) => {// 设置响应头-内容类型-普通文本以及中文编码格式res.setHeader('Content-Type', 'text/plain;charset=utf-8')// 设置响应体内容,结束本次请求与响应res.end('欢迎使用 Node.js 和 http 模块创建的 Web 服务')})// 1.3 配置端口号并启动 Web 服务server.listen(3000, () => {console.log('Web 服务启动成功了')})
学完了,来做一个案例 - 通过Web服务,将html页面提供给浏览器浏览
- 需求:基于 Web服务,开发提供网页资源的功能,了解下后端的代码工作过程

- 步骤:
- 基于 http 模块,创建 Web 服务
- 使用 req.url 获取请求资源路径为 /index.html 的时候,读取 index.html 文件内容文字非常返回给请求方
- 其他路径,暂时返回不存在的提示
- 运行 Web 服务,用浏览器发起请求
- 代码如下:
/*** 目标:编写 web 服务,监听请求的是 /index.html 路径的时候,返回 dist/index.html 时钟案例页面内容* 步骤:* 1. 基于 http 模块,创建 Web 服务* 2. 使用 req.url 获取请求资源路径,并读取 index.html 里字符串内容返回给请求方* 3. 其他路径,暂时返回不存在提示* 4. 运行 Web 服务,用浏览器发起请求*/const fs = require('fs')const path = require('path')// 1. 基于 http 模块,创建 Web 服务const http = require('http')const server = http.createServer()server.on('request', (req, res) => {// 2. 使用 req.url 获取请求资源路径,并读取 index.html 里字符串内容返回给请求方if (req.url === '/index.html') {fs.readFile(path.join(__dirname, 'dist/index.html'), (err, data) => {res.setHeader('Content-Type', 'text/html;charset=utf-8')res.end(data.toString())})} else {// 3. 其他路径,暂时返回不存在提示res.setHeader('Content-Type', 'text/html;charset=utf-8')res.end('你要访问的资源路径不存在')}})server.listen(8080, () => {console.log('Web 服务启动了')})