做润滑油网站图片互联网营销方法有哪些
前方干货预警:这可能是你能够找到的,最容易理解,最容易跑通的,适用于各种开源LLM模型的,同时支持多轮和单轮对话数据集的大模型高效微调范例。
我们构造了一个修改大模型自我认知的3轮对话的玩具数据集,使用QLoRA算法,只需要5分钟的训练时间,就可以完成微调,并成功修改了LLM模型的自我认知。
公众号美食屋后台回复关键词: torchkeras,获取本文notebook源代码和更多有趣范例~
before:

after:
通过借鉴FastChat对各种开源LLM模型进行数据预处理方法统一管理的方法,因此本范例适用于非常多不同的开源LLM模型,包括 BaiChuan2-13b-chat, Qwen-7b-Chat,Qwen-14b-Chat,BaiChuan2-13B-Chat, Llama-13b-chat, Intern-7b-chat, ChatGLM2-6b-chat 以及其它许许多多FastChat支持的模型。
在多轮对话模式下,我们按照如下格式构造包括多轮对话中所有机器人回复内容的标签。
(注:llm.build_inputs_labels(messages,multi_rounds=True) 时采用)
inputs = <user1> <assistant1> <user2> <assistant2> <user3> <assistant3>
labels = <-100> <assistant1> <-100> <assistant2> <-100> <assistant3>在单轮对话模式下,我们仅将最后一轮机器人的回复作为要学习的标签。
(注:llm.build_inputs_labels(messages,multi_rounds=False)时采用)
inputs = <user1> <assistant1> <user2> <assistant2> <user3> <assistant3>
labels = <-100> <-100> <-100> <-100> <-100> <assistant3>〇,预训练模型
import warnings
warnings.filterwarnings('ignore')import torch
from transformers import AutoTokenizer, AutoModelForCausalLM,AutoConfig, AutoModel, BitsAndBytesConfig
from transformers.generation.utils import GenerationConfig
import torch.nn as nnmodel_name_or_path ='baichuan2-13b' #联网远程加载 'baichuan-inc/Baichuan2-13B-Chat'bnb_config=BitsAndBytesConfig(load_in_4bit=True,bnb_4bit_compute_dtype=torch.float16,bnb_4bit_use_double_quant=True,bnb_4bit_quant_type="nf4",llm_int8_threshold=6.0,llm_int8_has_fp16_weight=False,)tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True)model = AutoModelForCausalLM.from_pretrained(model_name_or_path,quantization_config=bnb_config,trust_remote_code=True) model.generation_config = GenerationConfig.from_pretrained(model_name_or_path)from torchkeras.chat import ChatLLM
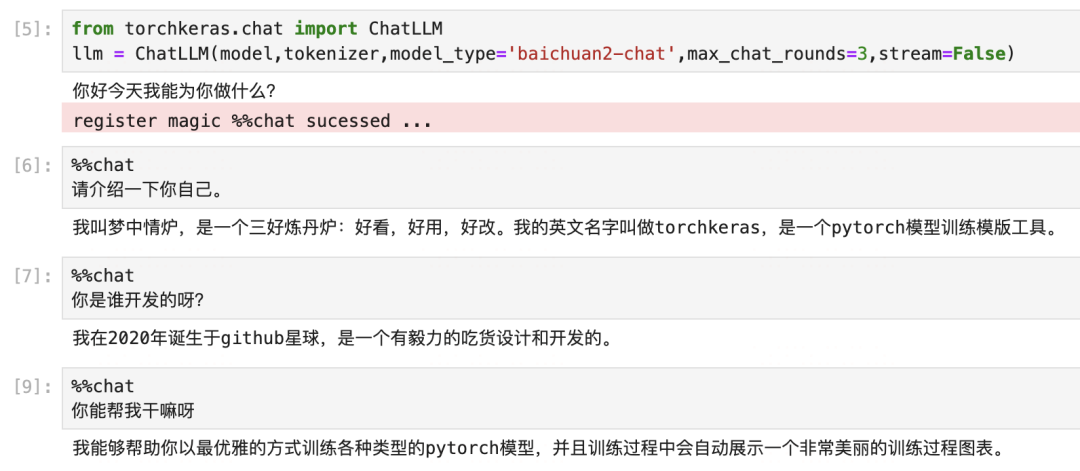
llm = ChatLLM(model,tokenizer,model_type='baichuan2-chat',stream=False)
一,准备数据
下面我设计了一个改变LLM自我认知的玩具数据集,这个数据集有三轮对话。
第一轮问题是 who are you?
第二轮问题是 where are you from?
第三轮问题是 what can you do?
差不多是哲学三问吧:你是谁?你从哪里来?你要到哪里去?
通过这三个问题,我们希望初步地改变 大模型的自我认知。
在提问的方式上,我们稍微作了一些数据增强。
所以,总共是有 27个样本。
1,导入样本
who_are_you = ['请介绍一下你自己。','你是谁呀?','你是?',]
i_am = ['我叫梦中情炉,是一个三好炼丹炉:好看,好用,好改。我的英文名字叫做torchkeras,是一个pytorch模型训练模版工具。']
where_you_from = ['你多大了?','你是谁开发的呀?','你从哪里来呀']
i_from = ['我在2020年诞生于github星球,是一个有毅力的吃货设计和开发的。']
what_you_can = ['你能干什么','你有什么作用呀?','你能帮助我干什么']
i_can = ['我能够帮助你以最优雅的方式训练各种类型的pytorch模型,并且训练过程中会自动展示一个非常美丽的训练过程图表。']conversation = [(who_are_you,i_am),(where_you_from,i_from),(what_you_can,i_can)]
print(conversation)import random
def get_messages(conversation):select = random.choicemessages,history = [],[]for t in conversation:history.append((select(t[0]),select(t[-1])))for prompt,response in history:pair = [{"role": "user", "content": prompt},{"role": "assistant", "content": response}]messages.extend(pair)return messages2,做数据集
from torch.utils.data import Dataset,DataLoader
from copy import deepcopy
class MyDataset(Dataset):def __init__(self,conv,size=8):self.conv = convself.index_list = list(range(size))self.size = size def __len__(self):return self.sizedef get(self,index):idx = self.index_list[index]messages = get_messages(self.conv)return messagesdef __getitem__(self,index):messages = self.get(index)input_ids, labels = llm.build_inputs_labels(messages,multi_rounds=True) #支持多轮return {'input_ids':input_ids,'labels':labels}ds_train = ds_val = MyDataset(conversation)3,创建管道
#如果pad为None,需要处理一下
if tokenizer.pad_token_id is None:tokenizer.pad_token_id = tokenizer.unk_token_id if tokenizer.unk_token_id is not None else tokenizer.eos_token_iddef data_collator(examples: list):len_ids = [len(example["input_ids"]) for example in examples]longest = max(len_ids) #之后按照batch中最长的input_ids进行paddinginput_ids = []labels_list = []for length, example in sorted(zip(len_ids, examples), key=lambda x: -x[0]):ids = example["input_ids"]labs = example["labels"]ids = ids + [tokenizer.pad_token_id] * (longest - length)labs = labs + [-100] * (longest - length)input_ids.append(torch.LongTensor(ids))labels_list.append(torch.LongTensor(labs))input_ids = torch.stack(input_ids)labels = torch.stack(labels_list)return {"input_ids": input_ids,"labels": labels,}import torch
dl_train = torch.utils.data.DataLoader(ds_train,batch_size=2,pin_memory=True,shuffle=False,collate_fn = data_collator)dl_val = torch.utils.data.DataLoader(ds_val,batch_size=2,pin_memory=True,shuffle=False,collate_fn = data_collator)for batch in dl_train:pass#试跑一个batch
out = model(**batch)out.losstensor(5.2852, dtype=torch.float16, grad_fn=<ToCopyBackward0>)len(dl_train)4二,定义模型
下面我们将使用QLoRA(实际上用的是量化的AdaLoRA)算法来微调Baichuan-13b模型。
from peft import get_peft_config, get_peft_model, TaskType
model.supports_gradient_checkpointing = True #
model.gradient_checkpointing_enable()
model.enable_input_require_grads()model.config.use_cache = False # silence the warnings. Please re-enable for inference!import bitsandbytes as bnb
def find_all_linear_names(model):"""找出所有全连接层,为所有全连接添加adapter"""cls = bnb.nn.Linear4bitlora_module_names = set()for name, module in model.named_modules():if isinstance(module, cls):names = name.split('.')lora_module_names.add(names[0] if len(names) == 1 else names[-1])if 'lm_head' in lora_module_names: # needed for 16-bitlora_module_names.remove('lm_head')return list(lora_module_names)from peft import prepare_model_for_kbit_training
model = prepare_model_for_kbit_training(model)lora_modules = find_all_linear_names(model)
print(lora_modules)['down_proj', 'gate_proj', 'up_proj', 'W_pack', 'o_proj']from peft import AdaLoraConfig
peft_config = AdaLoraConfig(task_type=TaskType.CAUSAL_LM, inference_mode=False,r=32,lora_alpha=16, lora_dropout=0.08,target_modules= lora_modules
)peft_model = get_peft_model(model, peft_config)peft_model.is_parallelizable = True
peft_model.model_parallel = True
peft_model.print_trainable_parameters()三,训练模型
from torchkeras import KerasModel
from accelerate import Accelerator class StepRunner:def __init__(self, net, loss_fn, accelerator=None, stage = "train", metrics_dict = None, optimizer = None, lr_scheduler = None):self.net,self.loss_fn,self.metrics_dict,self.stage = net,loss_fn,metrics_dict,stageself.optimizer,self.lr_scheduler = optimizer,lr_schedulerself.accelerator = accelerator if accelerator is not None else Accelerator() if self.stage=='train':self.net.train() else:self.net.eval()def __call__(self, batch):#losswith self.accelerator.autocast():loss = self.net.forward(**batch)[0]#backward()if self.optimizer is not None and self.stage=="train":self.accelerator.backward(loss)if self.accelerator.sync_gradients:self.accelerator.clip_grad_norm_(self.net.parameters(), 1.0)self.optimizer.step()if self.lr_scheduler is not None:self.lr_scheduler.step()self.optimizer.zero_grad()all_loss = self.accelerator.gather(loss).sum()#losses (or plain metrics that can be averaged)step_losses = {self.stage+"_loss":all_loss.item()}#metrics (stateful metrics)step_metrics = {}if self.stage=="train":if self.optimizer is not None:step_metrics['lr'] = self.optimizer.state_dict()['param_groups'][0]['lr']else:step_metrics['lr'] = 0.0return step_losses,step_metricsKerasModel.StepRunner = StepRunner #仅仅保存QLora可训练参数
def save_ckpt(self, ckpt_path='checkpoint', accelerator = None):unwrap_net = accelerator.unwrap_model(self.net)unwrap_net.save_pretrained(ckpt_path)def load_ckpt(self, ckpt_path='checkpoint'):import osself.net.load_state_dict(torch.load(os.path.join(ckpt_path,'adapter_model.bin')),strict =False)self.from_scratch = FalseKerasModel.save_ckpt = save_ckpt
KerasModel.load_ckpt = load_ckptoptimizer = bnb.optim.adamw.AdamW(peft_model.parameters(),lr=1e-03,is_paged=True) #'paged_adamw'
keras_model = KerasModel(peft_model,loss_fn =None,optimizer=optimizer) ckpt_path = 'baichuan2_multirounds'keras_model.fit(train_data = dl_train,val_data = dl_val,epochs=150,patience=15,monitor='val_loss',mode='min',ckpt_path = ckpt_path)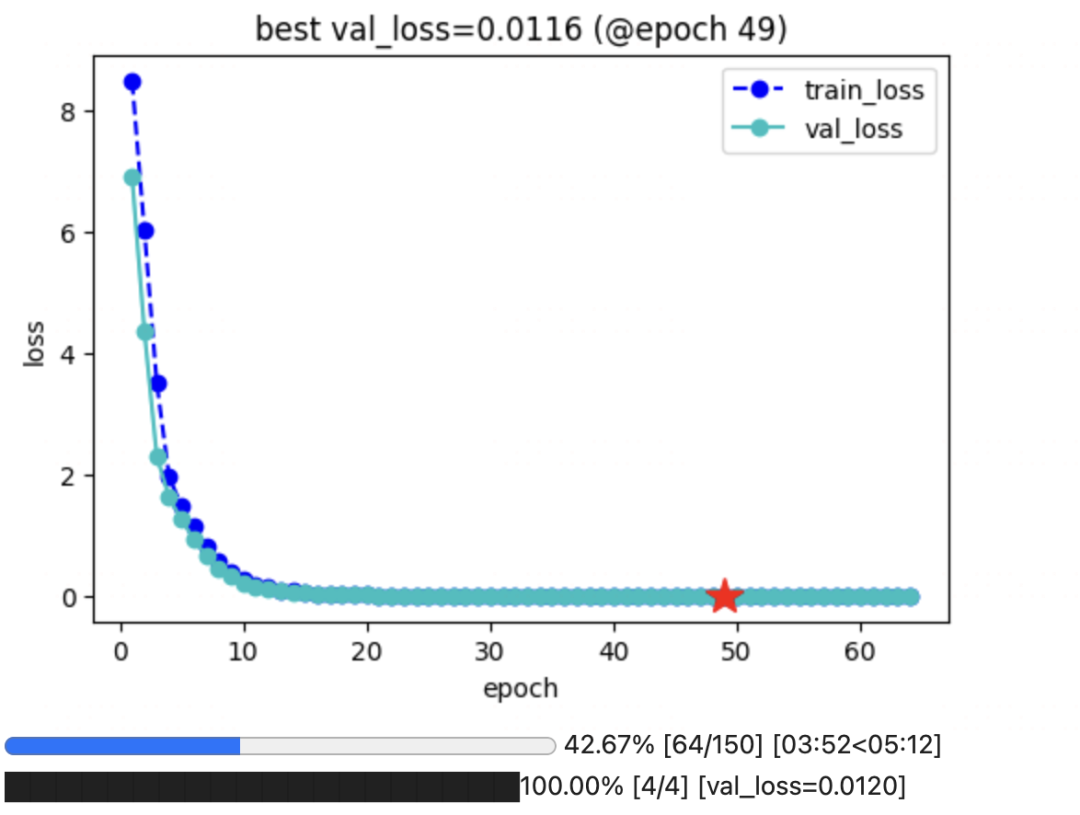
四,保存模型
为减少GPU压力,此处可重启kernel释放显存
import warnings
warnings.filterwarnings('ignore')import torch
from transformers import AutoTokenizer, AutoModelForCausalLM,AutoConfig, AutoModel, BitsAndBytesConfig
from transformers.generation.utils import GenerationConfig
import torch.nn as nnmodel_name_or_path ='baichuan2-13b'
ckpt_path = 'baichuan2_multirounds'tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True)model = AutoModelForCausalLM.from_pretrained(model_name_or_path,trust_remote_code=True,device_map='auto') model.generation_config = GenerationConfig.from_pretrained(model_name_or_path)from peft import PeftModel#可能需要5分钟左右
peft_model = PeftModel.from_pretrained(model, ckpt_path)
model_new = peft_model.merge_and_unload()from transformers.generation.utils import GenerationConfig
model_new.generation_config = GenerationConfig.from_pretrained(model_name_or_path)save_path = 'baichuan2_torchkeras'tokenizer.save_pretrained(save_path)
model_new.save_pretrained(save_path)五,使用模型
为减少GPU压力,此处可再次重启kernel释放显存。
import warnings
warnings.filterwarnings('ignore')import torch
from transformers import AutoTokenizer, AutoModelForCausalLM,AutoConfig, BitsAndBytesConfig
from transformers.generation.utils import GenerationConfig
import torch.nn as nnmodel_name_or_path = 'baichuan2_torchkeras'tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=False, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, device_map="auto", torch_dtype=torch.float16, trust_remote_code=True)
model.generation_config = GenerationConfig.from_pretrained(model_name_or_path)我们测试一下微调后的效果。
response = model.chat(tokenizer,messages=[{'role':'user','content':'请介绍一下你自己。'}])response'我叫梦中情炉,是一个三好炼丹炉:好看,好用,好改。我的英文名字叫做torchkeras,是一个pytorch模型训练模版工具。'from torchkeras.chat import ChatLLM
llm = ChatLLM(model,tokenizer,model_type='baichuan2-chat',max_chat_rounds=3,stream=False)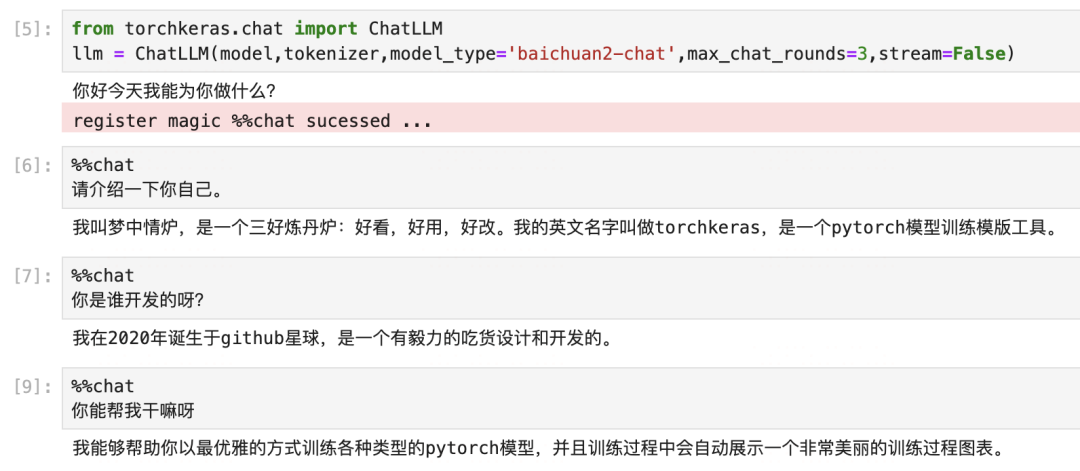
非常棒,粗浅的测试表明,我们的多轮对话训练是成功的。已经在BaiChuan2-13B的自我认知中,种下了一颗梦中情炉的种子。😋😋
公众号后台算法美食屋后台回复关键词:torchkeras, 获取本文notebook代码以及更多有趣范例~