做网站的公司需要什么资质网站建设公司哪家好
最近看到几个项目都用mask2former做图像分割,虽然是1年前的论文,但是其attention的设计还是很有借鉴意义,同时,mask2former参考了detr的query设计,实现了语义和实例分割任务的统一。
1.背景
1.1 detr简介
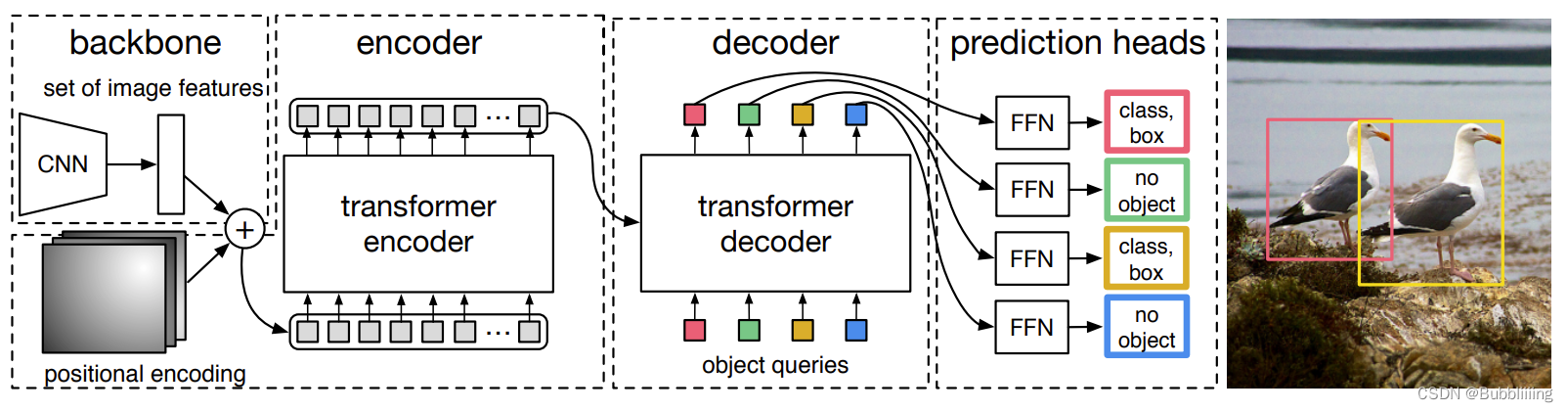
detr算是第一个尝试用transformer实现目标检测的框架,其设计思路也很简单,就是定义object queries,用来查询是否存在目标以及目标位置的,类似cnn检测中的rpn,产生候选框。在detr中,object queries为(100,b,256)的可学习的参数,其中每个256维的向量代表了检测的box信息,这个信息是由类别和空间信息(box坐标)组成,其中类别信息用于区别类别,而空间信息则描述了目标在图像中的位置。
通过设置query,则不需要像传统cnn检测时预设anchor,最后通过匈牙利匹配算法将query到的目标和gt进行匹配,计算loss。
decoder过程中,query object先初始化为0,然后经过self attention,再和encoder的输出进行cross attention。
1.2 Deformable-DETR简介
Deformable-Detr是在detr的基础上了主要做了2个改进,Deformable attention(可变形注意力)和多尺度特征,通过可变性注意力降低了显存,多尺度特征对小目标检测效果比较好。
(1)Deformable attention(可变形注意力)
这个设计参考了可变性卷积(DCN),后续很多设计都参考了这个。先看下DCN,就是在标准卷积(a)的3 * 3的卷积核上,每个点上增加一个偏移量(dx,dy),让卷积核不规则,可以适应目标的形状和尺度。
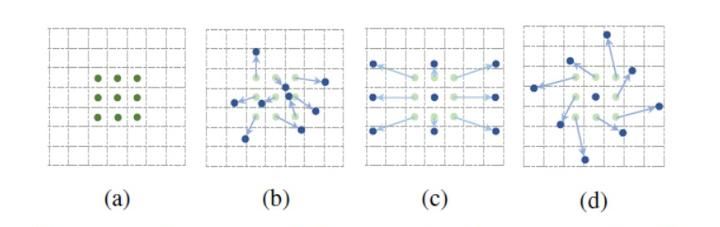
对于一般的attention,query与key的每个值都要计算注意力,这样的问题就是耗显存;另外,对图像来说,假设其中有一个目标,一般只有离图像比较近的像素才有用,离比较远的像素,对目标的贡献很少,甚至还有负向的干扰。
Defromable attention的设计思路就是query不与全局的key进行计算,而是至于其周围的key进行计算。至于这个周围要选哪几个位置,就类似DCN,让模型自己去学。
- 单尺度的可变性注意力机制
DeformAttn的公式如下: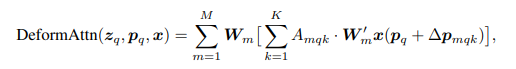

- 多尺度的可变性注意力机制
多尺度即类似fpn,提取不同尺度的特征,但由于特征的尺寸不一样,需要将不同尺度的特征连接起来。
可变性注意力机制公式如下:

相比单尺度的,多尺度多了一个l,代表第几个尺度,一般取4个层级。
对于一个query,在其参考点(reference point)对应的所有层都采用K个点,然后将每层的K个点特征融合(相加)。
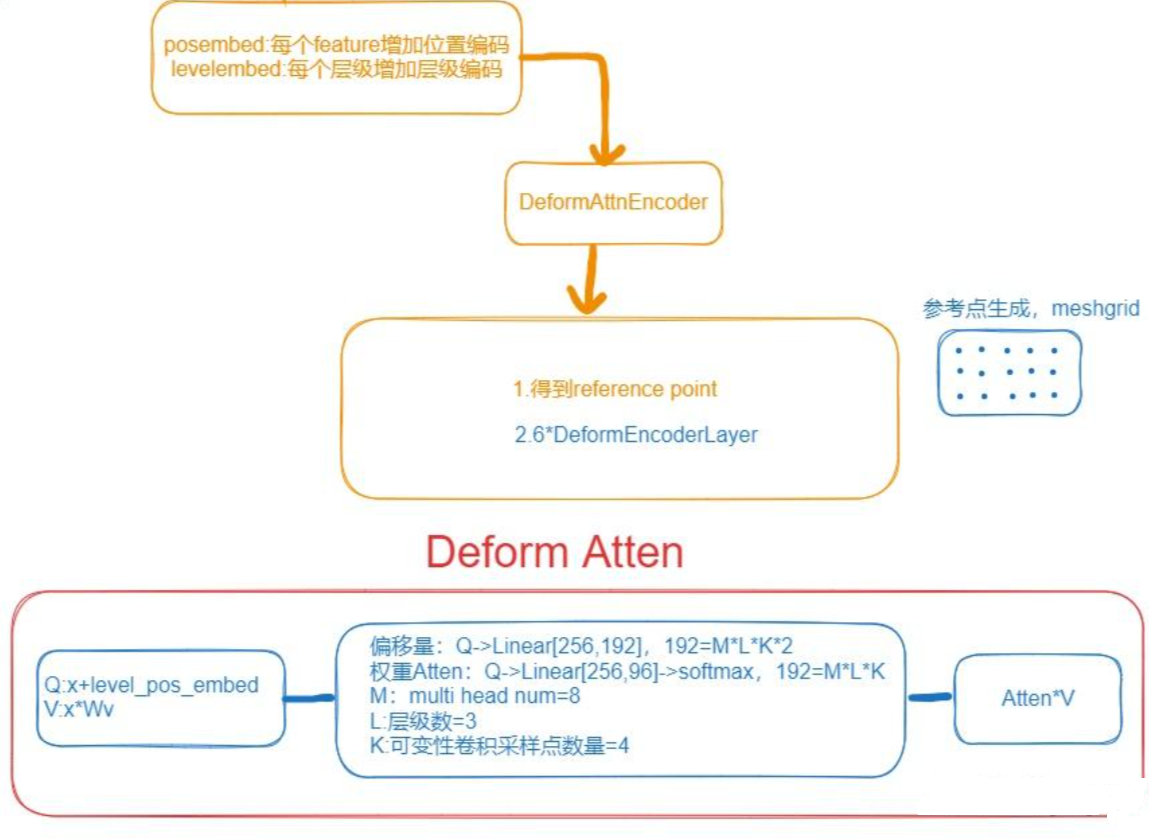
整个deformable atten的流程如下:
2.mask2former
mask2former的设计上使用了deformable detr的可变形注意力。
主要计算过程用下图表示:

2.1 模型改进
(1)masked attention
一般计算过程中,计算atten时只用前景部分计算,减少显存占用。
(2) 多分辨率特征
如上图,图像经过backbone得到4层特征,然后经过Pixel Decoder得到O1,O2,O3,O4,注意O1,O2,O3经过Linear+Deform atten Layer,O4只通过Linear+卷积得到,具体可以区别看上图。
(3) decoder优化
在transformer decoder(这个过程用的是标准attention)计算过程中,query刚开始都是随机初始化的,没有图像特征,如果按常规直接self attention可能学不到充分的信息,所以将ca和sa两个模块反过来,先和pixdecoder得到的图像O1,O2,O3计算ca,再继续计算sa。
2.2 类别和mask分开预测
class和mask预测独立开来,mask只预测是背景还是前景,class负责预测类别,这部分保留了maskformer的设计。
如上图,class通过query加上Linear直接将维度转到(n,k+1),其中k为类别数目。
mask通过decoder和最后一层的mask做外积运算,得到(k,h,w)的tensor,每个k代表一个前景。
采用这种query的方式,既可以做instance也可以做语义分割,query的数量N和类别K数量无关。
2.3 loss优化
mask decoder过程中,主要用最后一层的输出计算loss;同时为了辅助训练,默认开启了auxiliary loss(辅助loss),其他层的输出也去计算loss。
还有一个trick,mask计算loss时,不是mask上的所有点都去计算,而是随机采样一定数目的点去计算loss。默认设置K = 12544, i.e., 112 × 112 points,这样可以节省显存。
3.扩展
3.1 DAT:另一个Deform atten设计
另一篇deform atten的论文DAT,和deform attention思路类似,也是学习offset。只不过在偏移量设计上有区别,如下图所示,DAT在当前特征图F上学习offset时,进行了上采样2倍,在得到offset后需要插值回F的尺寸,增加了相对位置的bias。
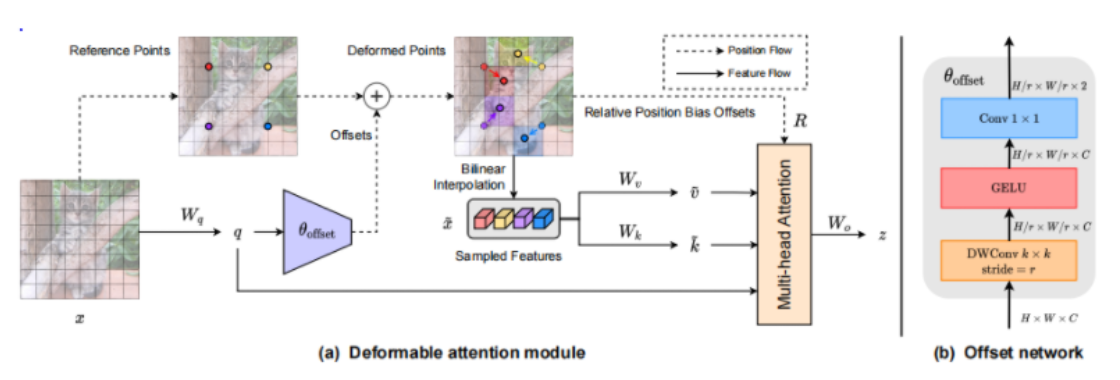
对比几种查询的注意力结果,vit是全查,swin固定窗口大小,有可能限制查到的key,DCN为可变性卷积,DAT学到的key更好。
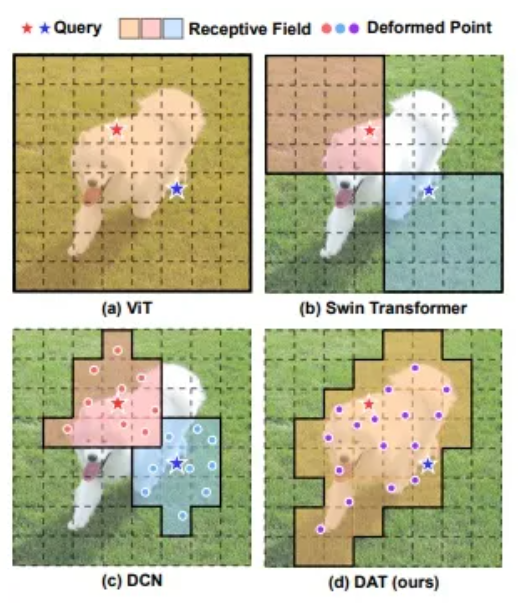
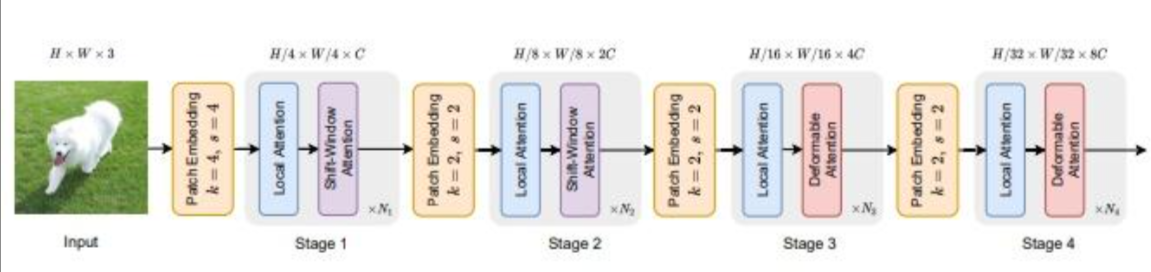
模型设计上,参考swin-transformer,只将最后2层替换Deformable attention,效果最好。
3.2 视频实例分割跟踪
mask2former用于视频分割,结构如下
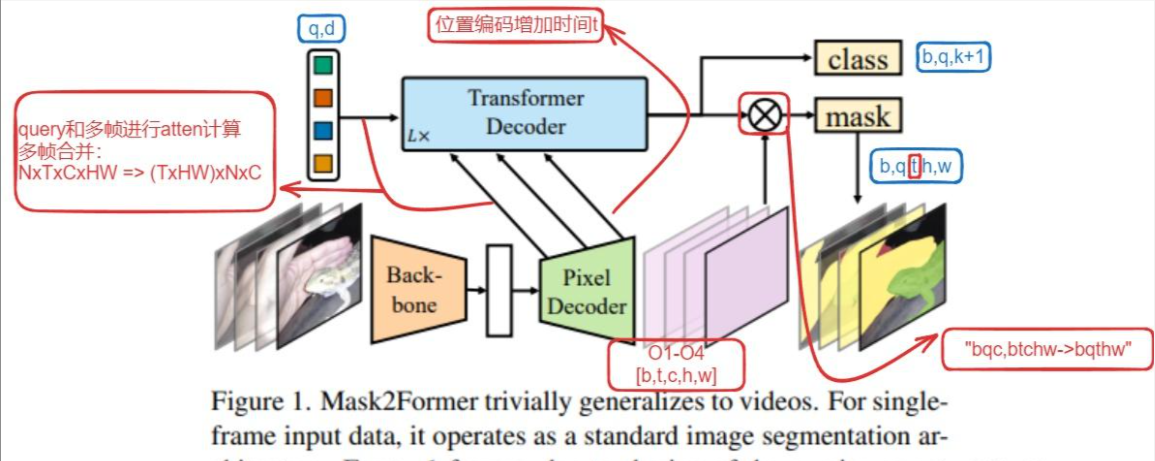
模型结构上和图像的分割基本一致。
修改主要在transformer decoder,包含以下3个地方:
(1)增加时间编码t
主要在Transformer decoder过程,图像的位置编码为(x,y),对于视频,由于考虑了多帧数据,增加时间t进行编码,位置编码为(x,y,t)。
# b, t, c, h, wassert x.dim() == 5, f"{x.shape} should be a 5-dimensional Tensor, got {x.dim()}-dimensional Tensor instead"if mask is None:mask = torch.zeros((x.size(0), x.size(1), x.size(3), x.size(4)), device=x.device, dtype=torch.bool)not_mask = ~maskz_embed = not_mask.cumsum(1, dtype=torch.float32) # not_mask【bath,t,h,w】1代表时间列的索引,cumsum累加计算,得到位置idy_embed = not_mask.cumsum(2, dtype=torch.float32) # hx_embed = not_mask.cumsum(3, dtype=torch.float32) # wif self.normalize:eps = 1e-6z_embed = z_embed / (z_embed[:, -1:, :, :] + eps) * self.scaley_embed = y_embed / (y_embed[:, :, -1:, :] + eps) * self.scalex_embed = x_embed / (x_embed[:, :, :, -1:] + eps) * self.scaledim_t = torch.arange(self.num_pos_feats, dtype=torch.float32, device=x.device)dim_t = self.temperature ** (2 * (dim_t // 2) / self.num_pos_feats)dim_t_z = torch.arange((self.num_pos_feats * 2), dtype=torch.float32, device=x.device)dim_t_z = self.temperature ** (2 * (dim_t_z // 2) / (self.num_pos_feats * 2))pos_x = x_embed[:, :, :, :, None] / dim_t # [b,t,h,w]->[b,t,h,w,d] xy编码的d长度是位置编码向量长度的一半pos_y = y_embed[:, :, :, :, None] / dim_tpos_z = z_embed[:, :, :, :, None] / dim_t_z # z用编码向量长度,然后和xy编码相加pos_x = torch.stack((pos_x[:, :, :, :, 0::2].sin(), pos_x[:, :, :, :, 1::2].cos()), dim=5).flatten(4)pos_y = torch.stack((pos_y[:, :, :, :, 0::2].sin(), pos_y[:, :, :, :, 1::2].cos()), dim=5).flatten(4)pos_z = torch.stack((pos_z[:, :, :, :, 0::2].sin(), pos_z[:, :, :, :, 1::2].cos()), dim=5).flatten(4)pos = (torch.cat((pos_y, pos_x), dim=4) + pos_z).permute(0, 1, 4, 2, 3) # b, t, c, h, w(2) query和多帧数据进行atten计算
for i in range(self.num_feature_levels):size_list.append(x[i].shape[-2:])pos.append(self.pe_layer(x[i].view(bs, t, -1, size_list[-1][0], size_list[-1][1]), None).flatten(3))src.append(self.input_proj[i](x[i]).flatten(2) + self.level_embed.weight[i][None, :, None]) #level_embed size [level_num,d],level embed和输入相加# NTxCxHW => NxTxCxHW => (TxHW)xNxC # 多帧数据融合_, c, hw = src[-1].shapepos[-1] = pos[-1].view(bs, t, c, hw).permute(1, 3, 0, 2).flatten(0, 1)# 其中src是Pixel decoder的输出src[-1] = src[-1].view(bs, t, c, hw).permute(1, 3, 0, 2).flatten(0, 1)(3)query和mask计算优化
如代码所示,query和mask 外积计算,从q外积mask得到mask的shape为[b,q,t,h,w],也就是得到(b,q,t)个instance mask,然后query的instance mask和每帧的gt计算loss。
def forward_prediction_heads(self, output, mask_features, attn_mask_target_size):decoder_output = self.decoder_norm(output)decoder_output = decoder_output.transpose(0, 1)outputs_class = self.class_embed(decoder_output)mask_embed = self.mask_embed(decoder_output)# query和mask 外积计算,从q外积mask得到[b,q,t,h,w]个maskoutputs_mask = torch.einsum("bqc,btchw->bqthw", mask_embed, mask_features)b, q, t, _, _ = outputs_mask.shape# NOTE: prediction is of higher-resolution# [B, Q, T, H, W] -> [B, Q, T*H*W] -> [B, h, Q, T*H*W] -> [B*h, Q, T*HW]attn_mask = F.interpolate(outputs_mask.flatten(0, 1), size=attn_mask_target_size, mode="bilinear", align_corners=False).view(b, q, t, attn_mask_target_size[0], attn_mask_target_size[1])# must use bool type# If a BoolTensor is provided, positions with ``True`` are not allowed to attend while ``False`` values will be unchanged.attn_mask = (attn_mask.sigmoid().flatten(2).unsqueeze(1).repeat(1, self.num_heads, 1, 1).flatten(0, 1) < 0.5).bool()attn_mask = attn_mask.detach()return outputs_class, outputs_mask, attn_mask训练时是以instance作为一个基础单元,假设有t帧图像,有n个instance(实例),instance和frame的关系如下图表示:
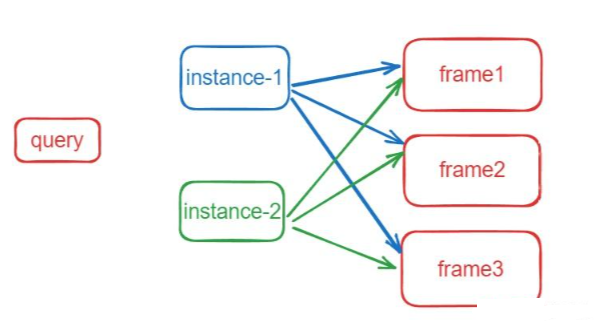
instance在每帧上都可能存在或者不存在。对于每个instance,初始化t个mask,初始化为0,所以instace的shape是[b,n,t,h,w],如果这个instance在某帧上存在,即赋真值mask,用于匹配计算loss;不存在,即为0。
instance在每帧上都是同一个物体(形态可能变化,但是instance id是相同的),所以预测instance的类别时,每个instance只需要预测一个类别即可,所以类别的shape为[b,n]。
3.3 思考
sam(segment anything model)可以通过prompt进行分割,但是缺乏类别信息,可以参考mask2former的思想,mask和类别是独立的,可以添加分类的query,接一个分类的分支,然后在coco等数据集上单独训练这个分支,让sam分割后增加类别信息。
4.参考资料
- mask2former论文
- mask2former代码
附赠
【一】上千篇CVPR、ICCV顶会论文
【二】动手学习深度学习、花书、西瓜书等AI必读书籍
【三】机器学习算法+深度学习神经网络基础教程
【四】OpenCV、Pytorch、YOLO等主流框架算法实战教程
➤ 在助理处自取:

➤ 还可咨询论文辅导❤【毕业论文、SCI、CCF、中文核心、El会议】评职称、研博升学、本升海外学府!