沈阳奇搜建站百度竞价优缺点
引言
上市公司的财报数据一般都会进行公开,我们可以在某交易所的官方网站上查看这些数据,由于数据很多,如果只是手动收集的话可能会比较耗时耗力,我们可以采用爬虫的方法进行数据的获取。
本文就介绍采用selenium框架进行公司财报数据获取的方法,网页的地址是
上市公司经营业绩概览 | 上海证券交易所
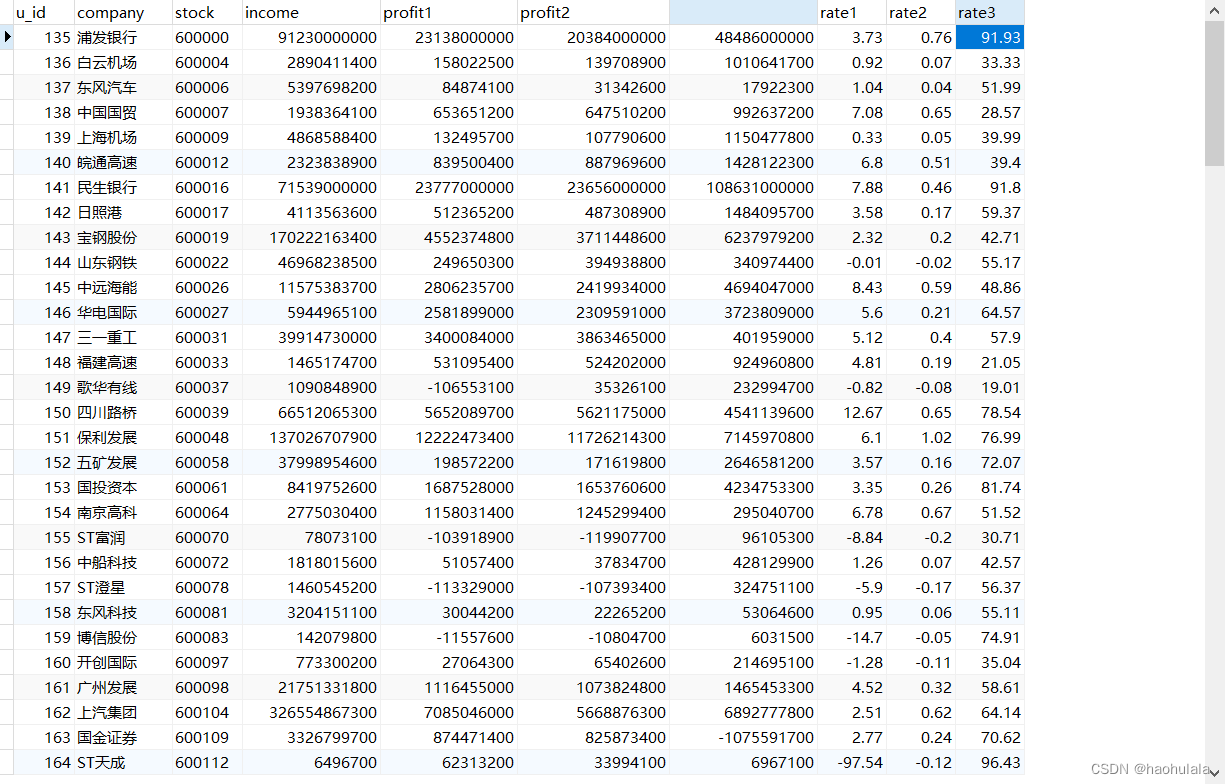
首先来看一下运行的效果
编程环境搭建
本文采用springboot进行开发,首先来看一下pom.xml的内容
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.7.12</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>com.example</groupId><artifactId>FinanceSpider</artifactId><version>0.0.1-SNAPSHOT</version><name>FinanceSpider</name><description>Demo project for Spring Boot</description><properties><java.version>1.8</java.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-thymeleaf</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>2.1.0</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.26</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency><!-- 爬虫相关的包 --><dependency><groupId>com.squareup.okhttp3</groupId><artifactId>okhttp</artifactId><version>3.10.0</version></dependency><dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.11.3</version></dependency><dependency><!-- fastjson --><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.47</version></dependency><dependency><groupId>cn.hutool</groupId><artifactId>hutool-core</artifactId><version>5.6.5</version></dependency><dependency><groupId>net.lightbody.bmp</groupId><artifactId>browsermob-core</artifactId><version>2.1.5</version></dependency><dependency><groupId>net.lightbody.bmp</groupId><artifactId>browsermob-legacy</artifactId><version>2.1.5</version></dependency><dependency><groupId>org.seleniumhq.selenium</groupId><artifactId>selenium-java</artifactId><version>4.1.1</version><!-- <version>3.141.59</version>--></dependency><dependency><groupId>io.github.bonigarcia</groupId><artifactId>webdrivermanager</artifactId><version>5.0.3</version></dependency><dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>31.0.1-jre</version></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-resources-plugin</artifactId><version>2.4.3</version></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-surefire-plugin</artifactId><version>2.22.2</version><configuration><skipTests>true</skipTests></configuration></plugin></plugins></build></project>
数据库方面采用的是mysql,下面是建表语句
use finance_db;/* 半年报信息表 */
drop table if exists t_report;
create table t_report (u_id BIGINT (20) unsigned NOT NULL AUTO_INCREMENT PRIMARY KEY COMMENT '优惠券id',company VARCHAR (50) NOT NULL COMMENT '公司名称',stock VARCHAR (20) NOT NULL COMMENT '股票代码',income BIGINT (20) NOT NULL COMMENT '营业收入',profit1 BIGINT (20) NOT NULL COMMENT '净利润',profit2 BIGINT (20) NOT NULL COMMENT '扣非净利润',cashflow BIGINT (20) NOT NULL COMMENT '经营现金流',rate1 DOUBLE NOT NULL COMMENT '净资产收益率',rate2 DOUBLE NOT NULL COMMENT '基本每股收益',rate3 DOUBLE NOT NULL COMMENT '资产负债率'
) ENGINE=InnoDB COMMENT '半年报信息表';对应的mapper类和配置文件如下所示
@Mapper
public interface ReportMapper {// 清空表public void clearAll();// 插入一条数据public void insertOneItem(@Param("item")ReportEntity entity);}<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.demo.mapper.ReportMapper"><delete id="clearAll">delete from t_report where 1=1</delete><insert id="insertOneItem" parameterType="ReportEntity">insert into t_report(company, stock, income, profit1, profit2, cashflow, rate1, rate2, rate3)values(#{item.company}, #{item.stock}, #{item.income}, #{item.profit1},#{item.profit2}, #{item.cashflow}, #{item.rate1}, #{item.rate2}, #{item.rate3})</insert></mapper>除此之外,我们还需要编写一个和数据库表对应的实体类
@Data
@AllArgsConstructor
@NoArgsConstructor
public class ReportEntity {// 公司名称private String Company;// 股票代码private String stock;// 营业收入private long income;// 净利润private long profit1;// 扣非净利润private long profit2;// 经营现金流private long cashflow;// 净资产收益率private double rate1;// 基本每股收益private double rate2;// 资产负债率private double rate3;}
爬虫程序编写
环境搭好后接下来就是最重要的爬虫程序编写的部分了,本文采用的是chrome浏览器,使用selenium框架的时候,需要采用和浏览器版本对应的驱动程序,下面是我的浏览器版本

我下载了对应版本的驱动程序,118版本的驱动可以在这个网址下载
https://googlechromelabs.github.io/chrome-for-testing/#stable
如果你的chrome版本较低,驱动程序应该很好找,直接百度就可以了。
下面来介绍具体的爬虫程序编写逻辑。
实际上某交易所的数据还是比较好获取的,就是有一点需要注意一下,网页都是先于数据渲染的,selenium在网页渲染好后就会开始获取元素信息,这时候可能就会获取不到数据,解决办法就是判断当前有没有获取到数据,如果没有获取到数据就等待一会然后继续获取,直到获取到数据位置,具体的代码如下
@Slf4j
@Service
public class ReportServiceImpl implements ReportService {private final String DRIVER_PATH = "E:/视频/电商爬虫/驱动/chromedriver-118.exe";private final String START_URL = "http://www.sse.com.cn/disclosure/listedinfo/listedcompanies/";@Autowiredprivate ReportMapper reportMapper;@Overridepublic void getReportInfo() {reportMapper.clearAll();System.setProperty("webdriver.chrome.driver", DRIVER_PATH);ChromeOptions options = new ChromeOptions();options.addArguments("--remote-allow-origins=*");WebDriver driver = new ChromeDriver(options);// 设置最长等待时间driver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS);driver.get(START_URL);while(true) {WebElement element = driver.findElement(By.className("list-group-flush"));WebElement ul = element.findElement(By.tagName("ul"));List<WebElement> liList = ul.findElements(By.tagName("li"));String firstname = null;String cmpname = null;for (int i = 0; i < liList.size(); i++) {if (i == 0) {firstname = driver.findElement(By.className("js_one_title")).getText();}// 点击进入新的页面liList.get(i).findElement(By.tagName("div")).click();List<String> handleList = new ArrayList<>(driver.getWindowHandles());driver.switchTo().window(handleList.get(1));// 获取新的数据WebElement title_lev1 = null;title_lev1 = driver.findElement(By.className("title_lev1")).findElement(By.tagName("span"));while(title_lev1.getText().split(" ").length == 1) {log.info("等待公司名称加载");sleep(1000);title_lev1 = driver.findElement(By.className("title_lev1")).findElement(By.tagName("span"));}String tmpstr = title_lev1.getText();// System.out.println(tmpstr);String title = tmpstr.split(" ")[0];String stock = tmpstr.split(" ")[1];List<WebElement> table_ele = driver.findElement(By.className("table-hover")).findElements(By.tagName("tr"));while(table_ele.get(0).findElements(By.tagName("td")).get(1).getText().equals("-")) {log.info("等待详细信息加载");sleep(2000);table_ele = driver.findElement(By.className("table-hover")).findElements(By.tagName("tr"));}// 营业收入long income = parseLongStr(table_ele.get(0).findElements(By.tagName("td")).get(1).getText());// 净利润long profit1 = parseLongStr(table_ele.get(0).findElements(By.tagName("td")).get(3).getText());// 扣非净利润long profit2 = parseLongStr(table_ele.get(2).findElements(By.tagName("td")).get(1).getText());// 经营现金流long cashflow = parseLongStr(table_ele.get(2).findElements(By.tagName("td")).get(3).getText());// 净资产收益率double rate1 = parseDoubleStr(table_ele.get(4).findElements(By.tagName("td")).get(1).getText());// 基本每股收益double rate2 = parseDoubleStr(table_ele.get(4).findElements(By.tagName("td")).get(3).getText());// 资产负债率double rate3 = parseDoubleStr(table_ele.get(6).findElements(By.tagName("td")).get(1).getText());ReportEntity entity = new ReportEntity(title, stock, income, profit1, profit2, cashflow, rate1, rate2, rate3);reportMapper.insertOneItem(entity);log.info("获取信息=>" + JSON.toJSONString(entity));sleep(1000);// 关闭新的页面closeWindow(driver);}// 如果有下一页就点击下一页if (check(driver, By.className("noNext"))) {log.info("已经么有下一页啦");break;}WebElement element1 = driver.findElement(By.className("pagination-box")).findElement(By.className("next"));element1.click();log.info("点击进入下一页");// 等待标签出现变化sleep(1000);cmpname = driver.findElement(By.className("js_one_title")).getText();while(cmpname.equals(firstname)) {log.info("继续等待页面加载");sleep(1000);cmpname = driver.findElement(By.className("js_one_title")).getText();}}}// 等待一定时间public void sleep(long millis) {try {Thread.sleep(millis);} catch (InterruptedException e) {e.printStackTrace();}}// 判断某个元素是否存在public boolean check(WebDriver driver, By selector) {try {driver.findElement(selector);return true;} catch (Exception e) {return false;}}public double parseDoubleStr(String doublestr) {if (doublestr.equals("-")) {return 0.0;} else {return Double.parseDouble(doublestr.replaceAll(",", ""));}}public long parseLongStr(String longstr) {// System.out.println("longstr=" + longstr);int flag = 1;if (longstr.contains("-1")) {flag = -1;}longstr = longstr.replaceAll("-", "");longstr = longstr.replaceAll(",", "");// 如果有小数点if (longstr.contains(".")) {longstr = longstr.replaceAll("\\.", "");return Long.parseLong(longstr) * 100 * flag;} else { // 没有小数点return Long.parseLong(longstr) * 10000 * flag;}}// 关闭当前窗口public void closeWindow(WebDriver driver) {// 获取所有句柄的集合List<String> winHandles = new ArrayList<>(driver.getWindowHandles());driver.switchTo().window((String) winHandles.get(1));driver.close();driver.switchTo().window((String) winHandles.get(0));}
}下面是controller层的代码,用于启动爬虫程序,需要开启一个线程进行执行,因为程序运行的时间会很久
@Controller
public class BootController {@Autowiredprivate ReportService reportService;@RequestMapping("start")@ResponseBodypublic String bootstart() {new Thread(()->{reportService.getReportInfo();}).start();return "success";}}
运行程序后就可以进行数据获取了,下面是获取到的一部分数据
总结
使用爬虫获取数据还是挺快的,也挺方便的。
不过还是要提醒一句,本文分享的内容仅作为学习交流使用,请勿用于任何商业用途!