软件开发用的软件seo和sem的联系
一:简介
数据量大了以后,单机解析或者生成文件的效率就很低,需要通过集群处理:
- 机构过来的文件:我们先对文件进行分片,在利用集群集群处理分片文件。
- 给机构文件:分库分表数据,每个分表生成一个分片文件,最终合成一个完整文件。
分布式下文件处理需要分布式的文件存储:
- 目前组件内部实现了NAS/OSS分布式的文件存储操作实现。
二:分布式环境原理
文件大了单机处理就很慢, 数据库解决单机瓶颈方式是分库分表, 文件也一样需要将文件拆分,利用集群机器并发处理。
- 导入类文件一般会先对文件按大小切分,生成分片任务。
- 导出类文件一般会根据分库分表位,生成分片任务。
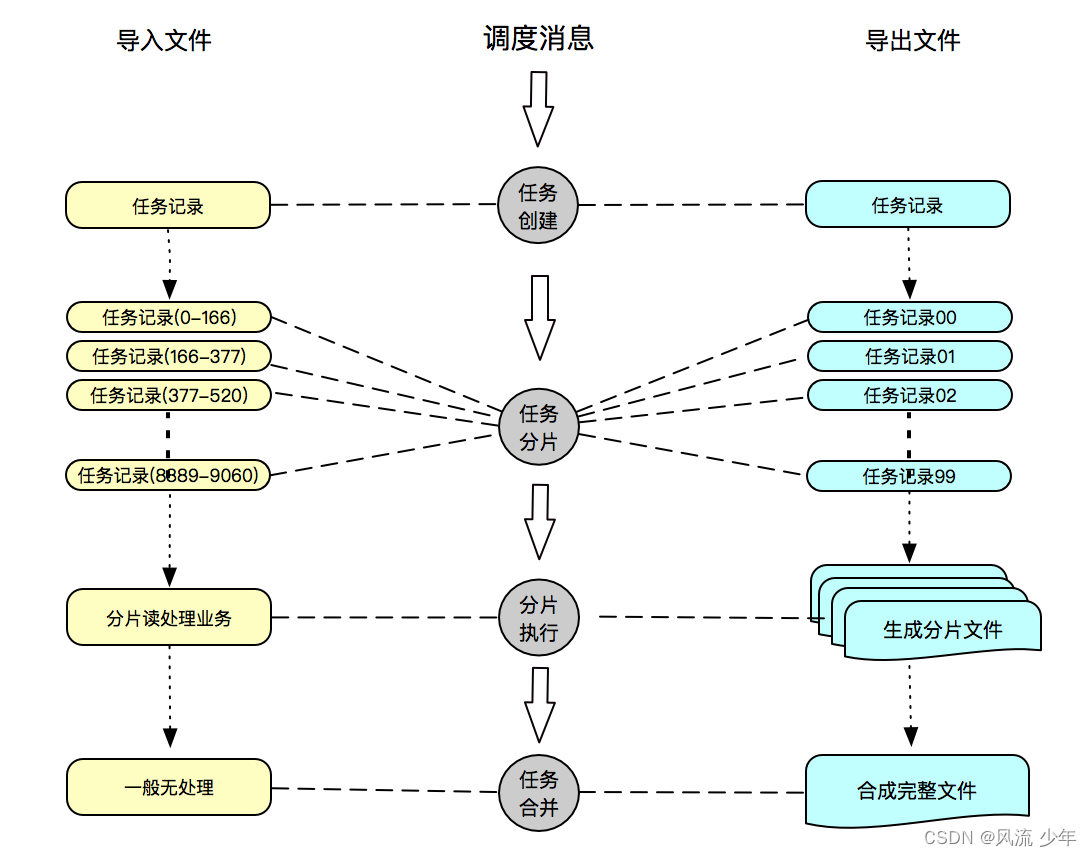
三:通信交互
使用文件异步交互和使用接口同步交互完全不同,文件交互会将请求的数据和响应的数据先写到文件中,然后将文件上传到对方的SFTP上,然后对方再去解析(相当于接口的请求参数、接口的响应结果先给对方),然后再通过实时接口通知或者定时任务触发去获取。
请求Request:先将请求参数(请求文件)上传到对方的SFTP服务器上,然后通过接口实时通知告诉对方数据已经准备好了你们可以处理了,也可以让对方在指定时间通过定时任务触发。发送文件send。响应Response:先将处理结果(响应文件)传到对方的SFTP服务器上,然后通过接口实时通知对方结果已经上传给你们了你们可以去获取了,也可以让对方在指定时间通过定时任务触发。接收文件。
四:分布式环境一般处理流程
文件切分是指按大小将数据内容分片, 这里分片到行不会在行中间断开。
-
创建文件分片工具。
FileSplitter splitter = FileFactory.createSplitter(config.getStorageConfig()); -
创建文件分片: 这里并没有真正对文件进行物理拆分。
FileSlice headSlice = splitter.getHeadSlice(config); List slices = splitter.getBodySlices(config, 256); FileSlice tailSlice = splitter.getTailSlice(config); -
将所有分片落成分片任务, 然后向集群分发分片任务。
-
集群中机器拿到分片任务,根据分片数据范围处理数据。
其它
<dependency><groupId>org.apache.commons</groupId><artifactId>commons-collections4</artifactId><version>4.4</version>
</dependency>
public class ListUtils {// list分片public static <T> List<List<T>> partition(List<T> list, int size);
}