政府网站改造的意义举例说明什么是seo
文章目录
- 前言
- 一、Bert的vocab.txt内容查看
- 二、BERT模型转换方法(vocab.txt)
- 三、vocab内容与模型转换对比
- 四、中文编码
- 总结
前言
最近一直在学习多模态大模型相关内容,特别是图像CV与语言LLM模型融合方法,如llama-1.5、blip、meta-transformer、glm等大模型。其语言模型的中文和英文句子如何编码成计算机识别符号,使我困惑。我查阅资料,也发现很少有博客全面说明。为此,我以该博客记录其整过过程,并附有对应代码供读者参考。
处理语言模型需要将英文或中文等字符表示成模型能识别的符号,为此不同模型会按照某些方法表示,但不同模型转计算机能识别思路是一致的。
一、Bert的vocab.txt内容查看
来源tokenization.py文件内容。
PRETRAINED_VOCAB_ARCHIVE_MAP = {'bert-base-uncased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased-vocab.txt",'bert-large-uncased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-uncased-vocab.txt",'bert-base-cased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-cased-vocab.txt",'bert-large-cased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-cased-vocab.txt",'bert-base-multilingual-uncased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-multilingual-uncased-vocab.txt",'bert-base-multilingual-cased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-multilingual-cased-vocab.txt",'bert-base-chinese': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-chinese-vocab.txt",
}
vocab.txt内容:

上图是我截取vocab.txt的内容,基本很多有的符号/数字/运算符/中文/字母/单词等均在该txt文件夹中。
二、BERT模型转换方法(vocab.txt)
加入有2句话,分别为text01与text02(如下),他们会转换vocab.txt中已有的单词形式。其中需要留意:’##符号连接长单词在vocab.txt部件方式,如embeddings表示为['em','##bed','##ding','s']。同时,vocab.txt不存在单词部件会化成最小组件,单个字母(vocab.txt最小部件是字母)。
代码如下:
from pytorch_pretrained_bert import BertTokenizertokenizer = BertTokenizer.from_pretrained('../voccab.txt')text01 = "Here is the sentence I want embeddings for."
text02 = "wish for world peace."
marked_text = "[CLS] " + text01 + " [SEP] " + text02 + " [SEP]"
print('marked_text = ', marked_text)tokenized_text = tokenizer.tokenize(marked_text)
print('tokenized_text = ', tokenized_text)indexed_tokens = tokenizer.convert_tokens_to_ids(tokenized_text)for tup in zip(tokenized_text, indexed_tokens):print("tup = ", tup)
marked_text是将句子使用符号分开表示其句子含义;
tokenized_text表示将句子化成vocab.txt文件提供的部件,其中##bed有单独表示;
tup = (‘[CLS]’, 101)后的内容表示其符号对应的索引。
其结果如下:
marked_text = [CLS] Here is the sentence I want embeddings for. [SEP] wish for world peace. [SEP]
tokenized_text = ['[CLS]', 'here', 'is', 'the', 'sentence', 'i', 'want', 'em', '##bed', '##ding', '##s', 'for', '.', '[SEP]', 'wish', 'for', 'world', 'peace', '.', '[SEP]']tup = ('[CLS]', 101)
tup = ('here', 2182)
tup = ('is', 2003)
tup = ('the', 1996)
tup = ('sentence', 6251)
tup = ('i', 1045)
tup = ('want', 2215)
tup = ('em', 7861)
tup = ('##bed', 8270)
tup = ('##ding', 4667)
tup = ('##s', 2015)
tup = ('for', 2005)
tup = ('.', 1012)
tup = ('[SEP]', 102)
tup = ('wish', 4299)
tup = ('for', 2005)
tup = ('world', 2088)
tup = ('peace', 3521)
tup = ('.', 1012)
tup = ('[SEP]', 102)
总结:最终词汇等内容转为对应的索引数字表达。
三、vocab内容与模型转换对比
从图中可知,vocab的索引值总比模型给出索引值小1,这是因为模型从0开始索引,而vocab展示内容从1开始,因此相差1。
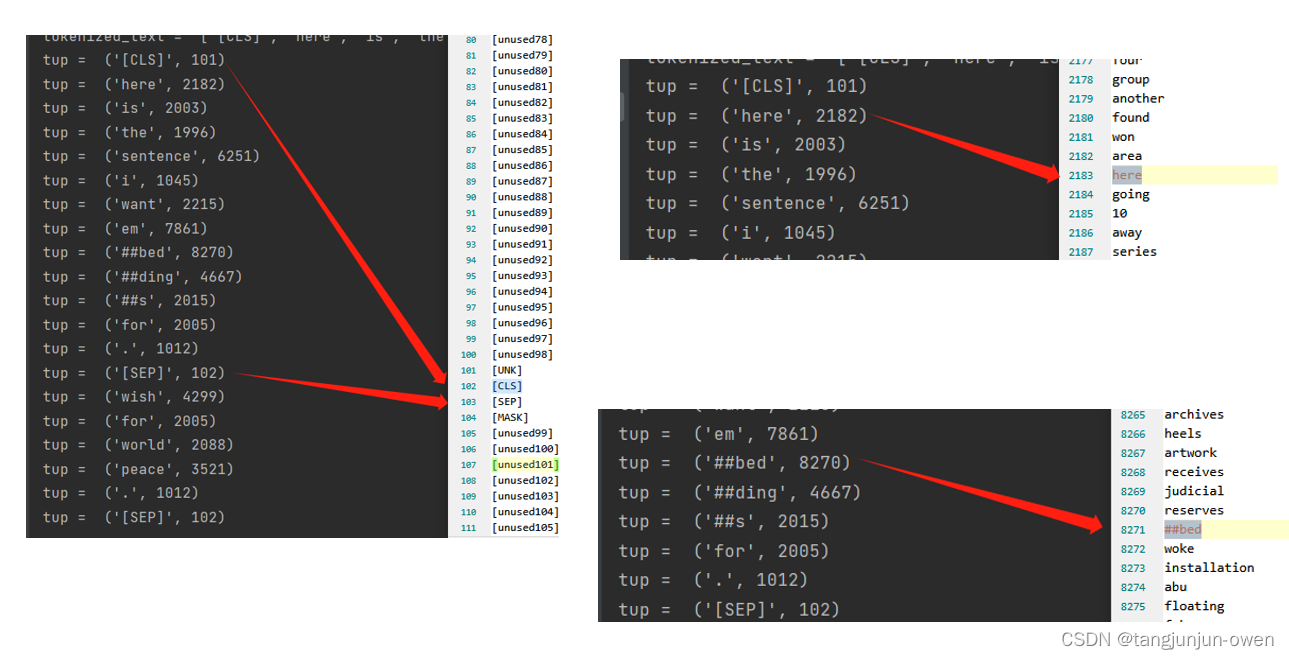
再次强调:模型对词汇编码实际为人为给出对应表(如:vocab.txt)所对应的索引,用索引值替换词语。
四、中文编码
以上内容已全部告知读者,模型如何编码句子。而该部分内容是拓展,使用中文编码,查看其结果。
代码如下:
from pytorch_pretrained_bert import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('../voccab.txt')
text01 = "the sentence I want embeddings for."
text02 = "愿世界和平。"
marked_text = "[CLS] " + text01 + " [SEP] " + text02 + " [SEP]"
print('marked_text = ', marked_text)
tokenized_text = tokenizer.tokenize(marked_text)
print('tokenized_text = ', tokenized_text)
indexed_tokens = tokenizer.convert_tokens_to_ids(tokenized_text)
for tup in zip(tokenized_text, indexed_tokens):print("tup = ", tup)
结果如下:
marked_text = [CLS] the sentence I want embeddings for. [SEP] 愿世界和平。 [SEP]
tokenized_text = ['[CLS]', 'the', 'sentence', 'i', 'want', 'em', '##bed', '##ding', '##s', 'for', '.', '[SEP]', '[UNK]', '世', '[UNK]', '和', '平', '。', '[SEP]']
tup = ('[CLS]', 101)
tup = ('the', 1996)
tup = ('sentence', 6251)
tup = ('i', 1045)
tup = ('want', 2215)
tup = ('em', 7861)
tup = ('##bed', 8270)
tup = ('##ding', 4667)
tup = ('##s', 2015)
tup = ('for', 2005)
tup = ('.', 1012)
tup = ('[SEP]', 102)
tup = ('[UNK]', 100)
tup = ('世', 1745)
tup = ('[UNK]', 100)
tup = ('和', 1796)
tup = ('平', 1839)
tup = ('。', 1636)
tup = ('[SEP]', 102)图显示:
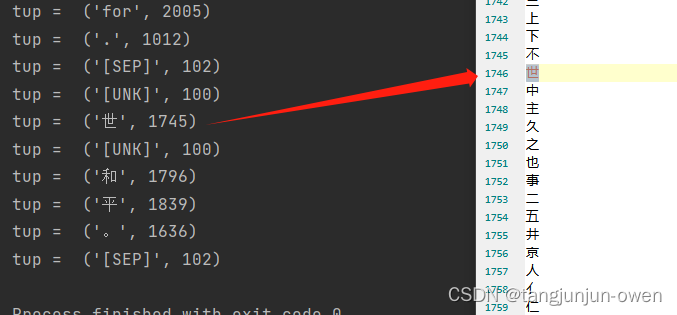
可发现,和上面英文句子编码是一样的。
总结
一句话,模型是根据提供对应表,将中/英文句子或符号编译成对应索引,被计算识别。