服务公司起名搜索引擎优化seo信息
作者:Chris Hegarty

在 Lucene 9.7.0 中,我们添加了利用 SIMD 指令执行向量相似性计算的数据并行化的支持。 现在,我们通过使用融合乘加 (Fused Mulitply-Add - FMA) 进一步推动这一点。
什么是 FMA
乘法和加法是一种常见的运算,它计算两个数字的乘积并将该乘积与第三个数字相加。 这些类型的操作在向量相似度计算期间反复执行。
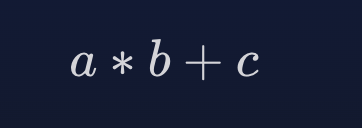
融合乘加 (FMA) 是一种单一运算,可同时执行乘法和加法运算 - 乘法和加法被称为“融合”在一起。 FMA 通常比单独的乘法和加法更快,因为大多数 CPU 将其建模为单个指令。
FMA 还可以产生更准确的结果。 浮点数的单独乘法和加法运算有两轮; 一个用于乘法,一个用于加法,因为它们是单独的指令,需要产生单独的结果。 也就是说有效地表述为:
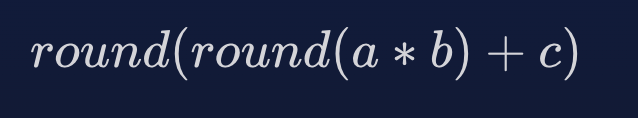
而 FMA 具有单舍入,仅适用于乘法和加法的组合结果。 也就是说有效地表述为:
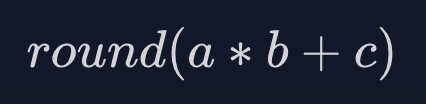
在 FMA 指令中,a * b 生成无限精度的中间结果,在最终结果舍入之前将其与 c 相加。 与单独的乘法和加法运算相比,这消除了单轮运算,从而提高了准确性。
底层是如何实现的?
那么到底发生了什么变化呢? 在 Lucene 中,我们用单个 FMA 运算替换了单独的乘法和加法运算。 标量变体现在使用 Math::fma,而巴拿马向量化变体使用 FloatVector::fma。
如果我们查看反汇编,我们可以看到此更改所产生的效果。 之前我们看到过点积的巴拿马向量化实现的这种代码模式。
vmovdqu32 zmm0,ZMMWORD PTR [rcx+r10*4+0x10]
vmulps zmm0,zmm0,ZMMWORD PTR [rdx+r10*4+0x10]
vaddps zmm4,zmm4,zmm0vmovdqu32 指令将 512 位打包双字值从内存位置加载到 zmm0 寄存器中。 然后,vmulps 指令将 zmm0 中的值与内存位置中相应的打包值相乘,并将结果存储在 zmm0 中。 最后,vaddps 指令将 zmm0 中的 16 个打包单精度浮点值与 zmm4 中的相应值相加,并将结果存储到 zmm4 中。
通过更改使用 FloatVector::fma,我们看到以下模式:
vmovdqu32 zmm0,ZMMWORD PTR [rdx+r11*4+0xd0]
vfmadd231ps zmm4,zmm0,ZMMWORD PTR [rcx+r11*4+0xd0]同样,第一条指令与前面的示例类似,它将 512 位打包双字值从内存位置加载到 zmm0 寄存器中。 vfmadd231ps(这是 FMA 指令)将 zmm0 中的值与内存位置中相应的打包值相乘,将中间结果添加到 zmm4 中的值,执行舍入并将生成的 16 个打包单精度浮点值存储在 zmm4.
vfmadd231ps 指令做了很多事情! 这是向 CPU 发出的关于代码正在运行的计算性质的明确信号。 鉴于此,CPU 可以就如何完成此操作做出更明智的决策,这通常会提高性能(以及前面所述的准确性)。
这样的修改会快吗?
一般来说,使用 FMA 通常会提高性能。 但一如既往,你需要进行基准测试! 值得庆幸的是,Lucene 在确定是否使用 FMA 时会处理相当复杂的问题,因此你不必这样做。 例如,CPU 是否支持 FMA、Java 虚拟机中是否启用了 FMA,以及仅在已证明比单独的乘法和加法运算更快的架构上启用 FMA。 正如你可能知道的那样,这种启发式方法并不完美,但对于提供良好的开箱即用体验大有帮助。 虽然 FMA 提高了准确性,但我们发现在未启用 FMA 时对预先存在的相似性计算没有负面影响。
随着 FMA 的使用,向量相似性函数套件得到了一些(更多)的喜爱。 所有点积、平方和余弦距离、标量和巴拿马向量化变体均已更新。 基于反汇编检查和实证实验进行了优化,带来了有助于填充管道并保持 CPU 繁忙的改进; 主要是通过更加一致和有针对性的循环展开,以及消除循环内的数据依赖性。
在此更改上给出具体的性能改进数字并不简单,因为效果涵盖了多个相似函数和变体,但我们看到了积极的吞吐量改进,从浮点点积中的个位数百分比到余弦中更高的两位数百分比改进。 基于字节的相似性函数也显示出类似的吞吐量改进。
总结起来
在 Lucene 9.7.0 中,我们添加了通过 SIMD 指令更快地实现向量搜索所使用的低级原语操作的功能。 在即将推出的 Lucene 9.9.0 中,我们在此基础上利用更快的 FMA 指令,并在所有相似性函数中更一致地应用优化技术。 以前版本的 Elasticsearch 已经受益于 SIMD,即将推出的 Elasticsearch 8.12.0 将具有 FMA 改进。
最后,我想感谢 Lucene PMC 成员 Robert Muir 在这一领域的持续改进,以及愉快而富有成效的合作。
原文:Vector Similarity Computations FMA-style — Elastic Search Labs