wordpress木马检测搜索引擎优化seo多少钱
上一篇:LeakCanary源码详解(2) 如果你是直接刷到这篇的,建议还是从1开始看,然后2,然后是这篇3,如果你只关注这篇的重点hprof 文件定位泄漏位置的感兴趣,可以试试直接读这篇,如果中间没发觉有难理解的就算了,要是发觉无法理解了就建议从1 2篇读起,经典的库的代码没那么简单,不要害怕花时间。
这篇要说一下hprof解析的,下图中是dumpHeap反复中,有两次sendEvent
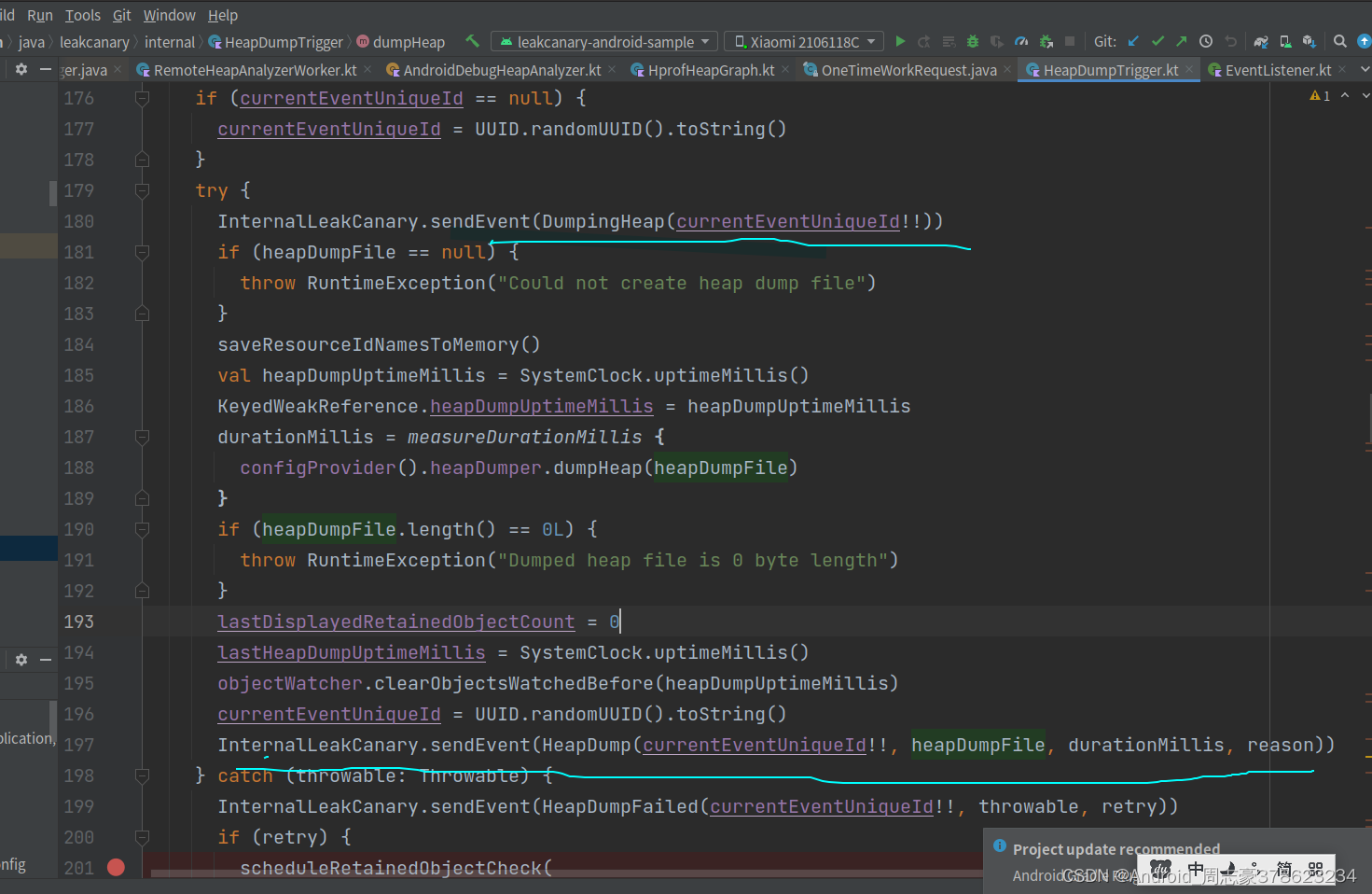 我们看一下里面
我们看一下里面
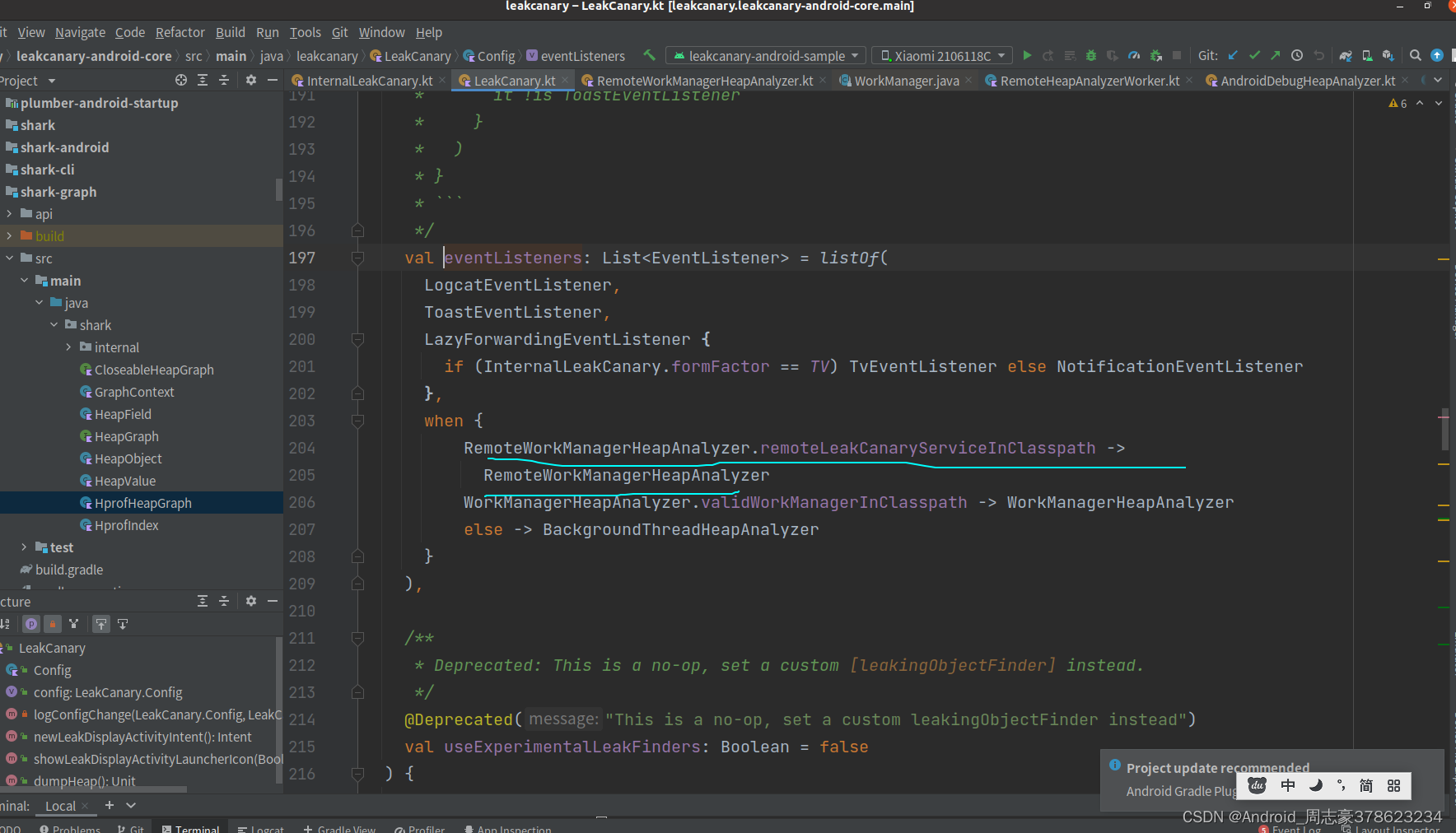
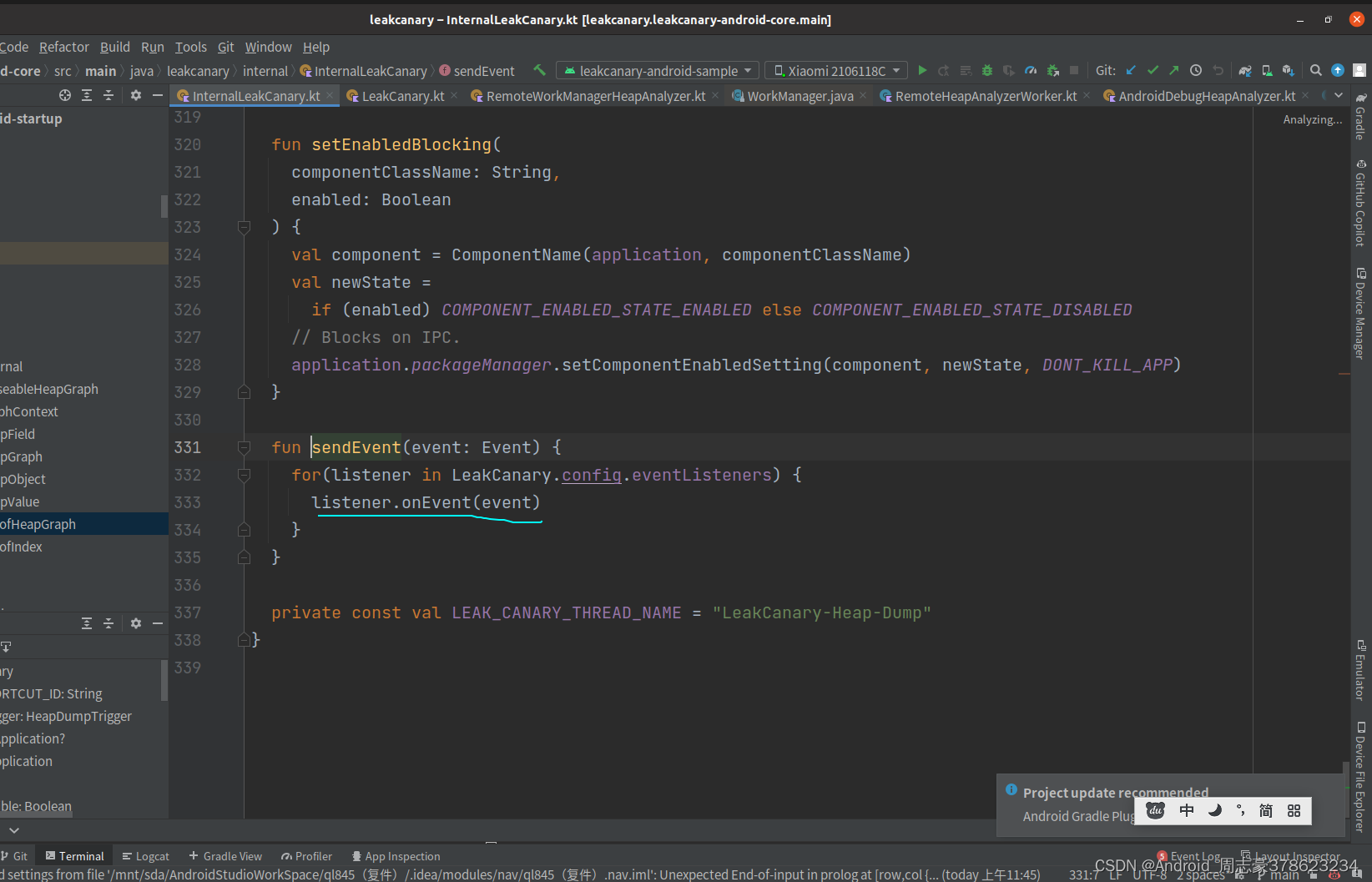 eventListeners里面的RemoteWorkManagerHeapAnalyzer就是分析hprof的类
eventListeners里面的RemoteWorkManagerHeapAnalyzer就是分析hprof的类
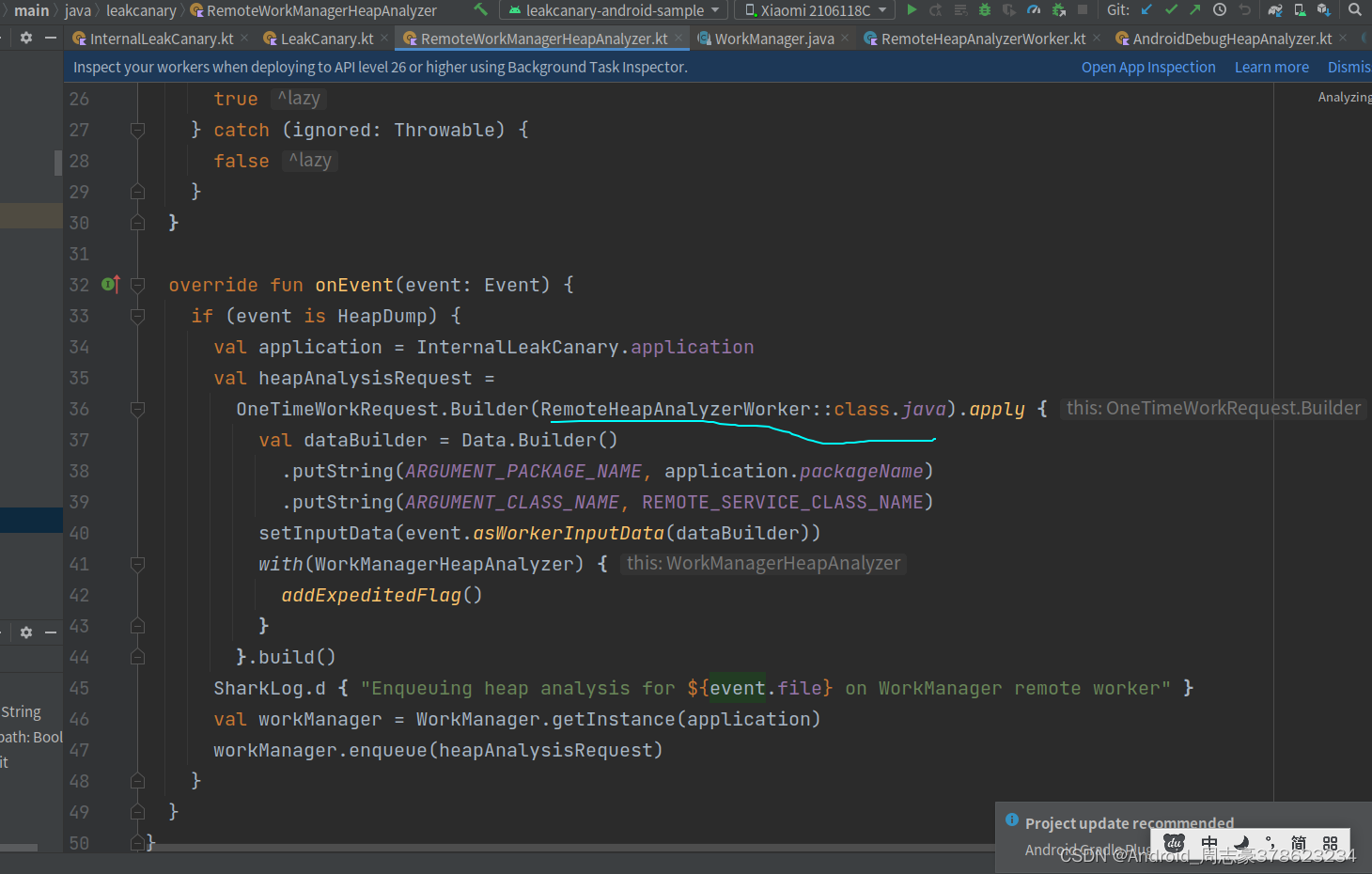
 然后就是RemoteHeapAnalyzerWorker
然后就是RemoteHeapAnalyzerWorker
 核心就是AndroidDebugHeapAnalyzer.runAnalysisBlocking了
核心就是AndroidDebugHeapAnalyzer.runAnalysisBlocking了
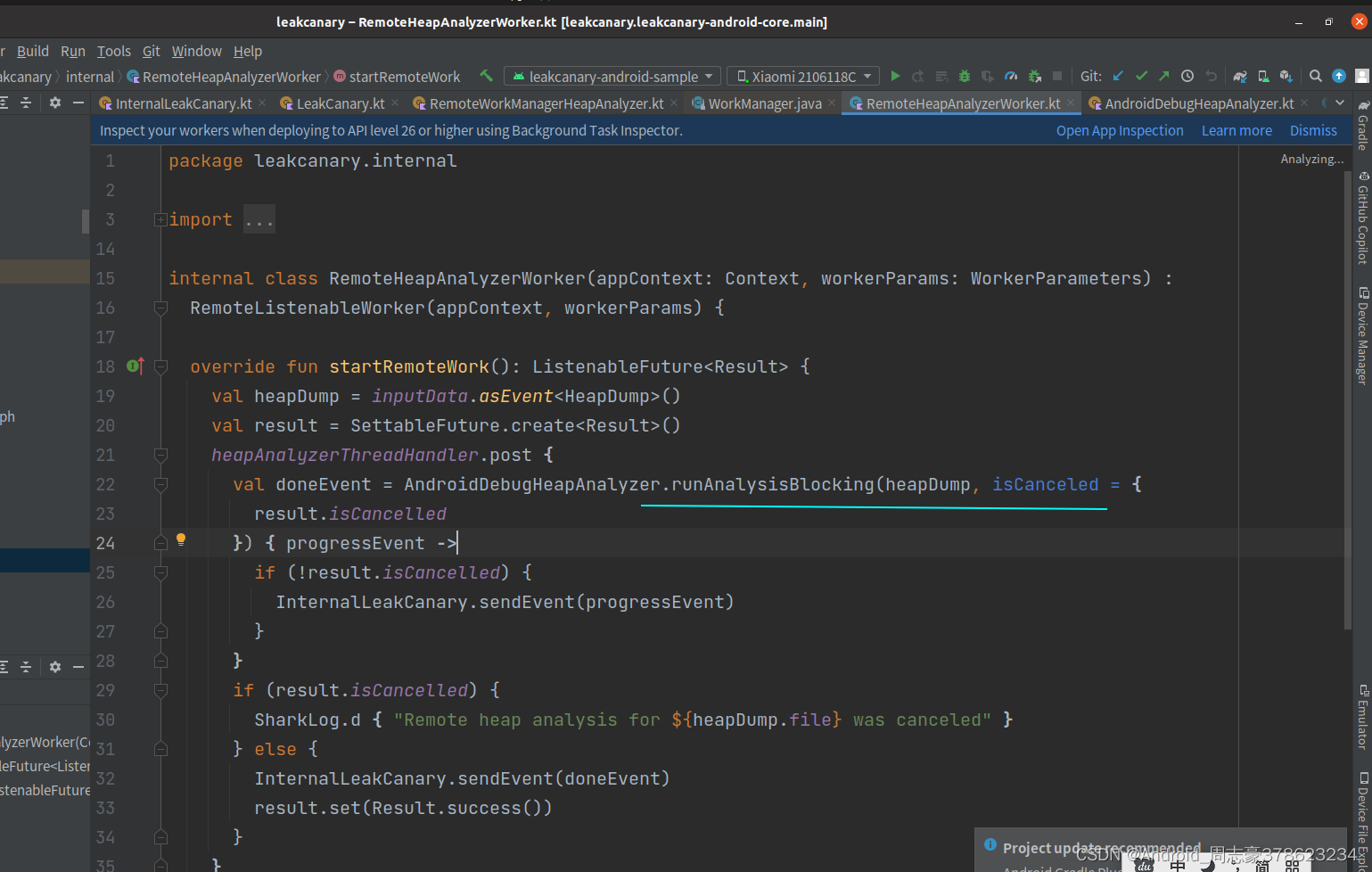 然后是analyzeheap()方法
然后是analyzeheap()方法
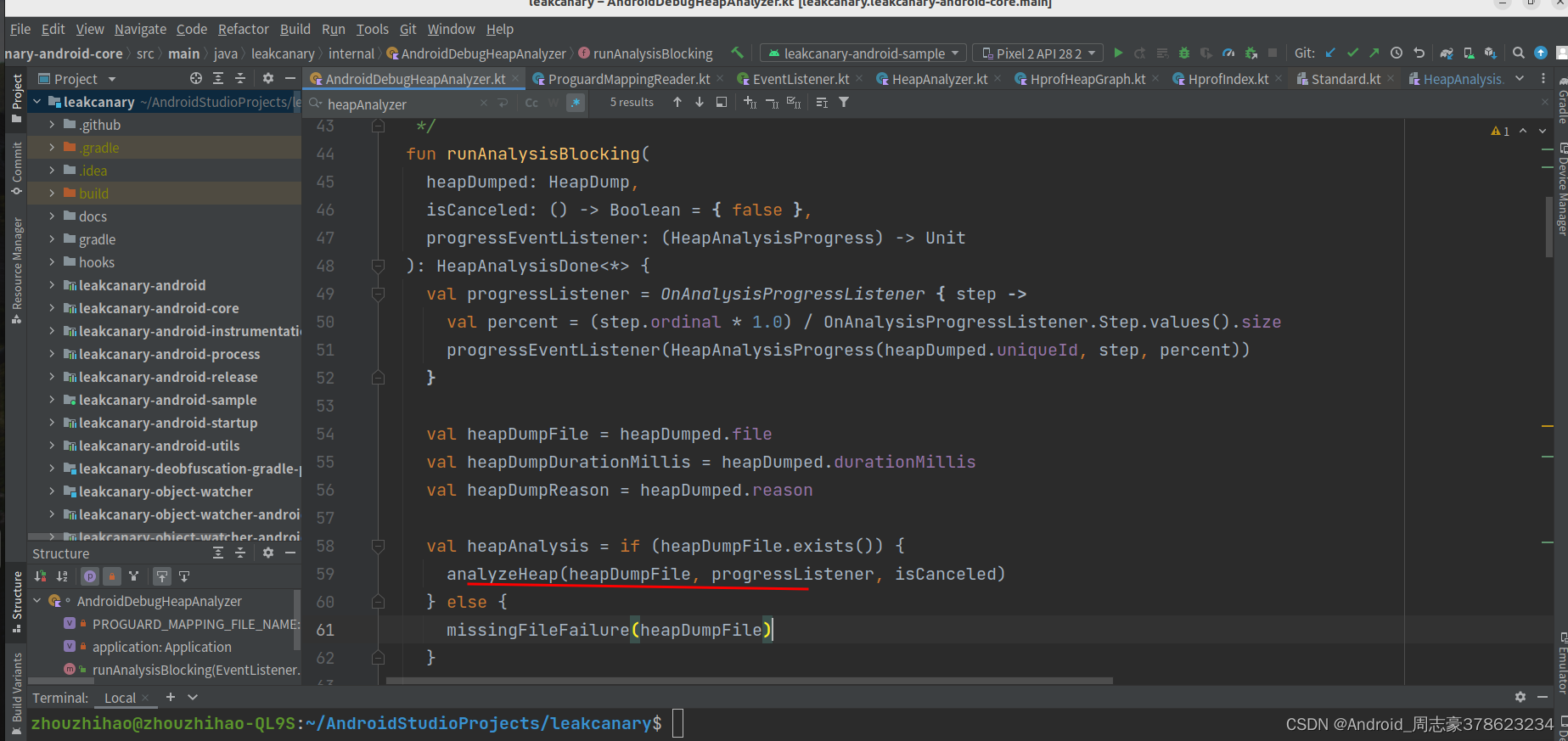 里面是调用heapAnalyzer.analyze方法
里面是调用heapAnalyzer.analyze方法
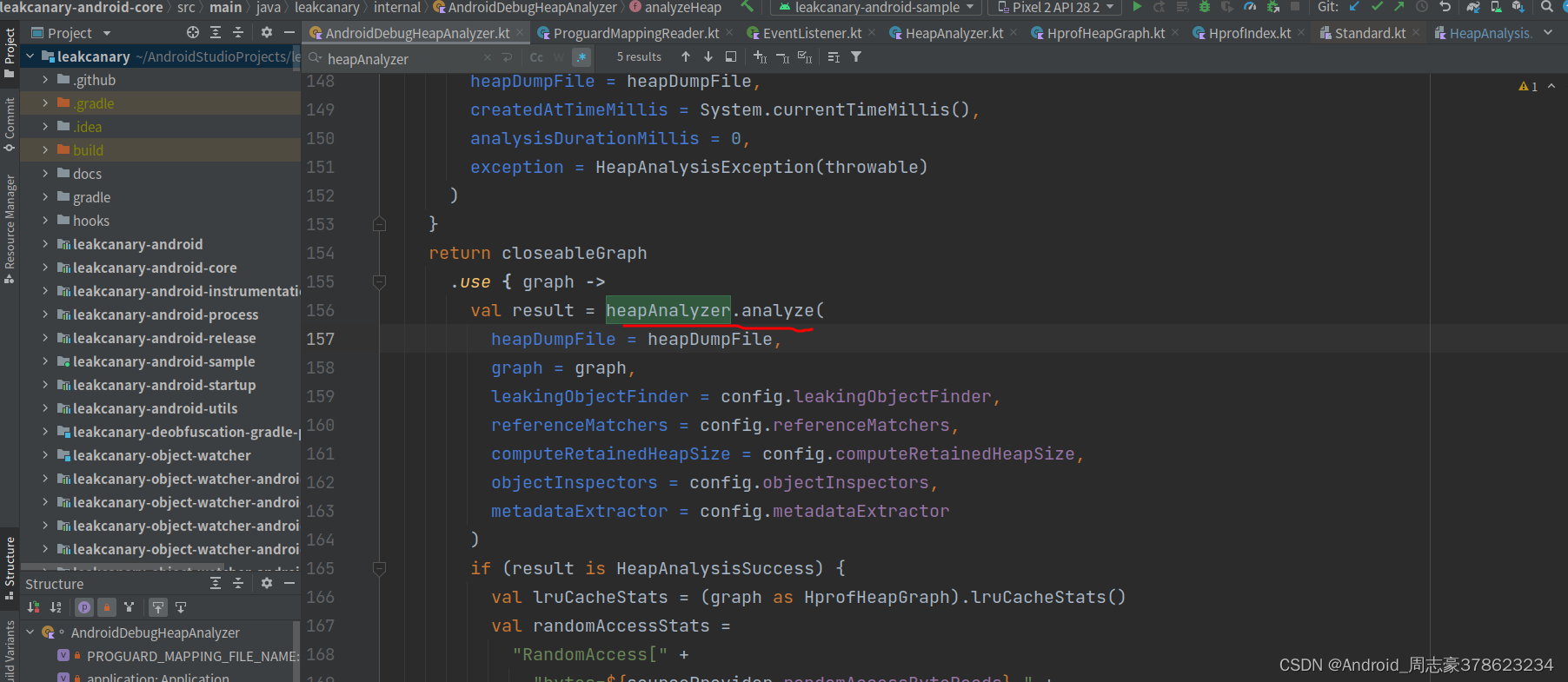 又调用了类本身内部的analyze方法。
又调用了类本身内部的analyze方法。
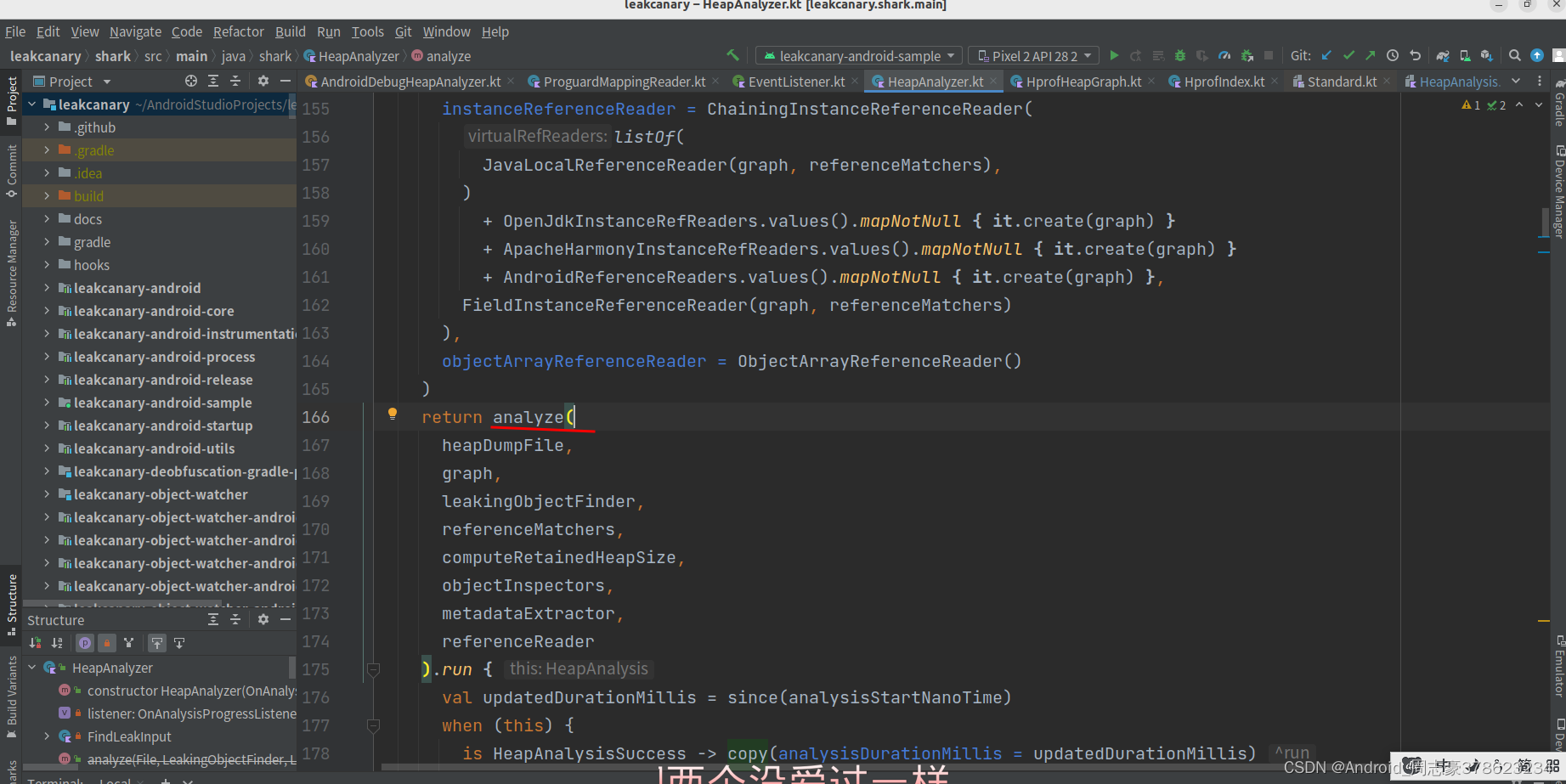
调用了helpers.analyzeGraph()
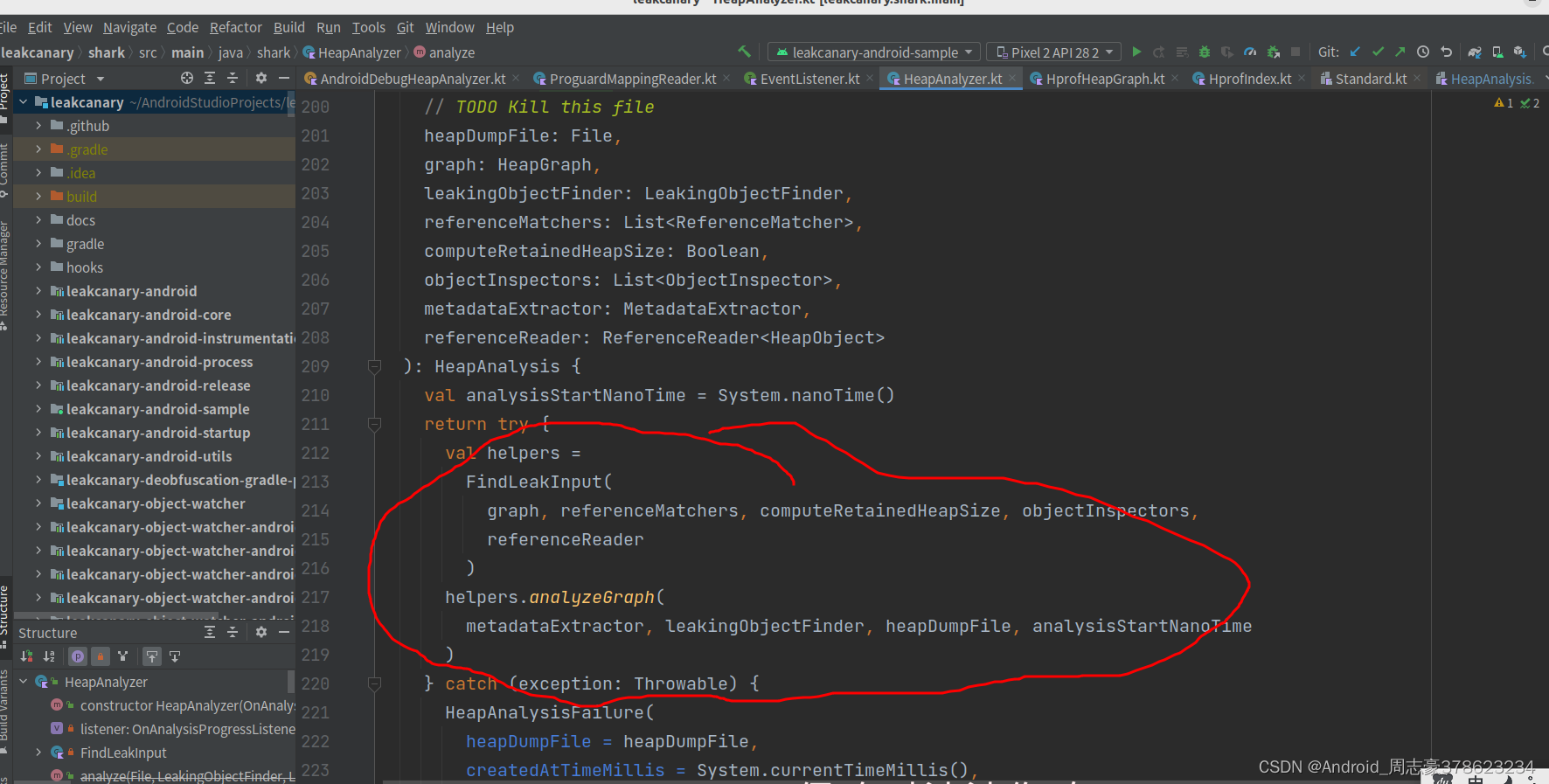
而在202309/24 新版本上是这图这样的,结构变了,逻辑一样,分析 graph
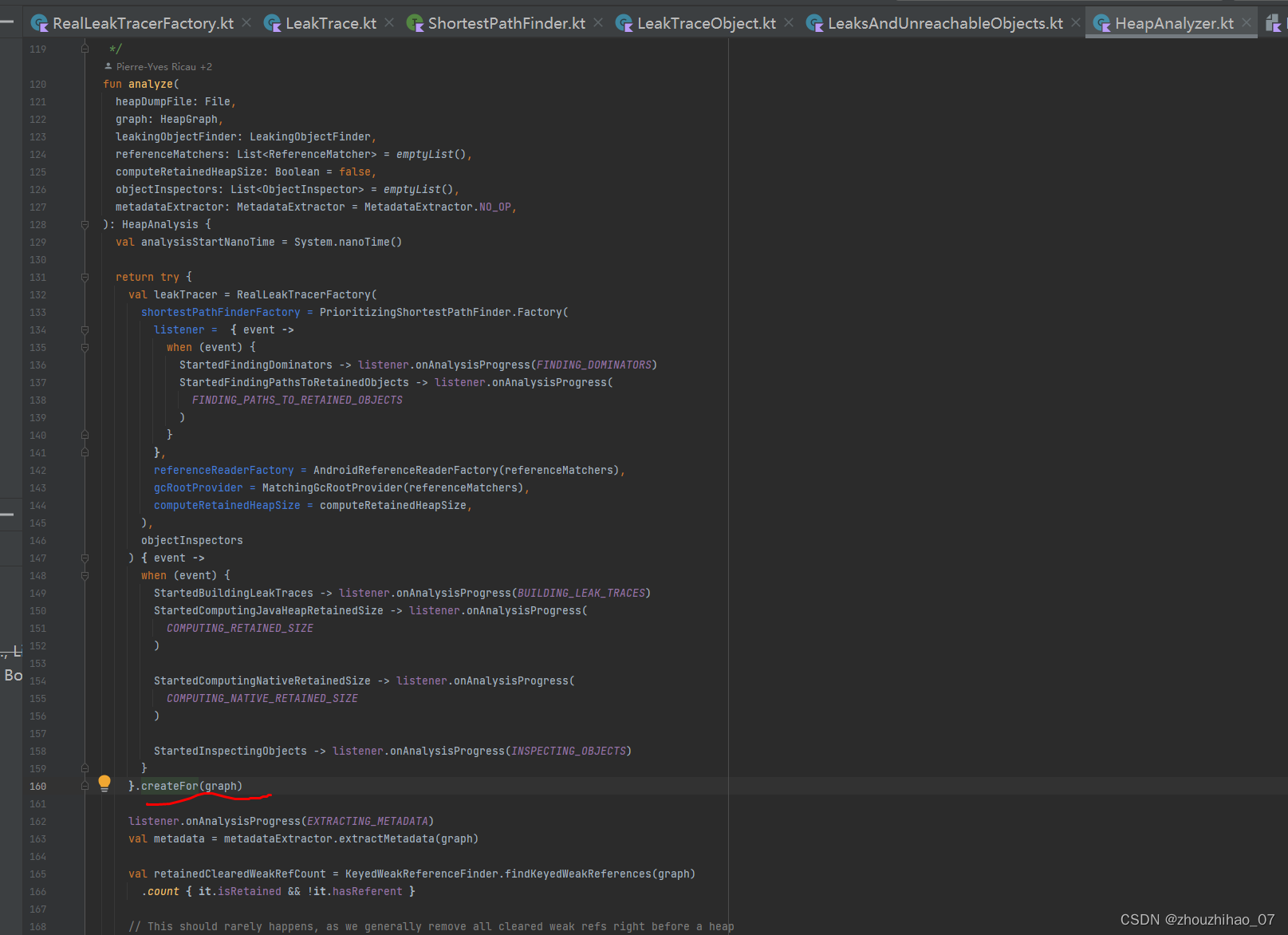
2.2 Hprof 文件解析
解析入口:
//HeapAnalyzerService
private fun analyzeHeap(
heapDumpFile: File,
config: Config
): HeapAnalysis {
val heapAnalyzer = HeapAnalyzer(this)
val proguardMappingReader = try {//解析混淆文件ProguardMappingReader(assets.open(PROGUARD_MAPPING_FILE_NAME))
} catch (e: IOException) {null
}
//分析hprof文件
return heapAnalyzer.analyze(heapDumpFile = heapDumpFile,leakingObjectFinder = config.leakingObjectFinder,referenceMatchers = config.referenceMatchers,computeRetainedHeapSize = config.computeRetainedHeapSize,objectInspectors = config.objectInspectors,metadataExtractor = config.metadataExtractor,proguardMapping = proguardMappingReader?.readProguardMapping()
)
}
关于Hprof文件的解析细节,就需要牵扯到Hprof二进制文件协议:
http://hg.openjdk.java.net/jdk6/jdk6/jdk/raw-file/tip/src/share/demo/jvmti/hprof/manual.html#mozTocId848088
通过阅读协议文档,hprof的二进制文件结构大概如下:
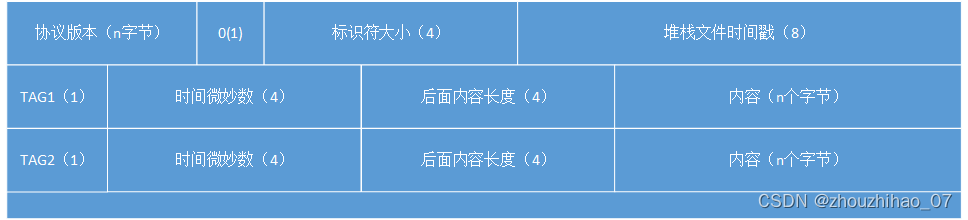
解析流程:
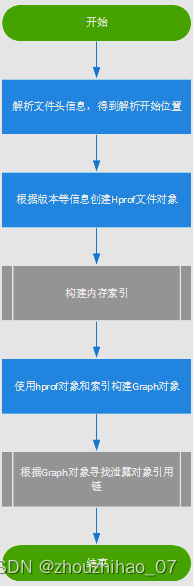
fun analyze(
heapDumpFile: File,
leakingObjectFinder: LeakingObjectFinder,
referenceMatchers: List = emptyList(),
computeRetainedHeapSize: Boolean = false,
objectInspectors: List = emptyList(),
metadataExtractor: MetadataExtractor = MetadataExtractor.NO_OP,
proguardMapping: ProguardMapping? = null
): HeapAnalysis {
val analysisStartNanoTime = System.nanoTime()
if (!heapDumpFile.exists()) {
val exception = IllegalArgumentException(“File does not exist: $heapDumpFile”)
return HeapAnalysisFailure(
heapDumpFile, System.currentTimeMillis(), since(analysisStartNanoTime),
HeapAnalysisException(exception)
)
}
return try {
listener.onAnalysisProgress(PARSING_HEAP_DUMP)
Hprof.open(heapDumpFile)
.use { hprof ->
val graph = HprofHeapGraph.indexHprof(hprof, proguardMapping)//建立gragh
val helpers =
FindLeakInput(graph, referenceMatchers, computeRetainedHeapSize, objectInspectors)
helpers.analyzeGraph(//分析graph
metadataExtractor, leakingObjectFinder, heapDumpFile, analysisStartNanoTime
)
}
} catch (exception: Throwable) {
HeapAnalysisFailure(
heapDumpFile, System.currentTimeMillis(), since(analysisStartNanoTime),
HeapAnalysisException(exception)
)
}
}
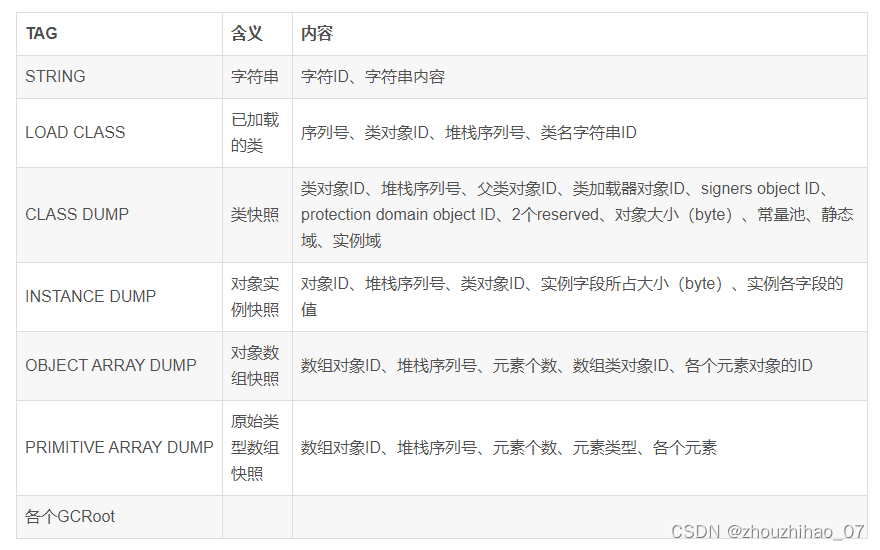
LeakCanary在建立对象实例Graph时,主要解析以下几种tag:
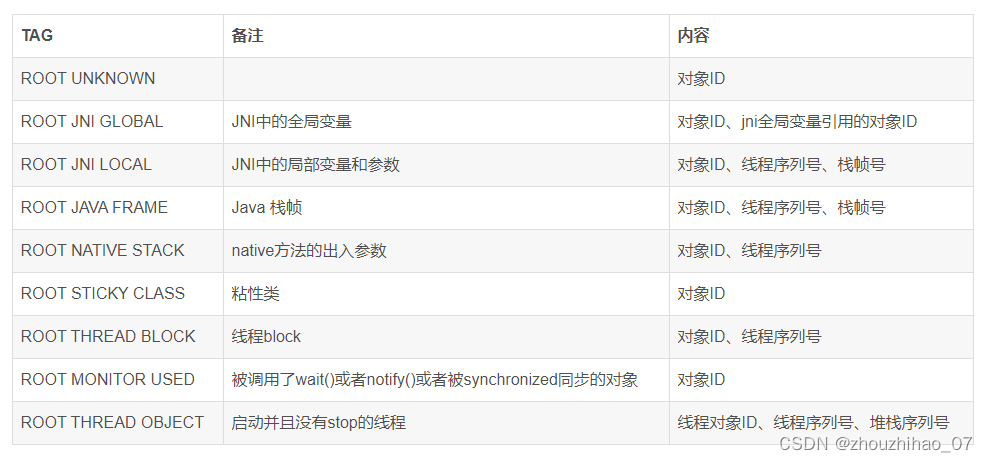
涉及到的GCRoot对象有以下几种:
2.2.1 构建内存索引(Graph内容索引)
LeakCanary会根据Hprof文件构建一个HprofHeapGraph 对象,该对象记录了以下成员变量:
interface HeapGraph {
val identifierByteSize: Int
/**
- In memory store that can be used to store objects this [HeapGraph] instance.
/
val context: GraphContext
/* - All GC roots which type matches types known to this heap graph and which point to non null
- references. You can retrieve the object that a GC Root points to by calling [findObjectById]
- with [GcRoot.id], however you need to first check that [objectExists] returns true because
- GC roots can point to objects that don’t exist in the heap dump.
/
val gcRoots: List
/* - Sequence of all objects in the heap dump.
- This sequence does not trigger any IO reads.
*/
val objects: Sequence //所有对象的序列,包括类对象、实例对象、对象数组、原始类型数组
val classes: Sequence //类对象序列
val instances: Sequence //实例对象数组
val objectArrays: Sequence //对象数组序列
val primitiveArrays: Sequence //原始类型数组序列
}
为了方便快速定位到对应对象在hprof文件中的位置,LeakCanary提供了内存索引HprofInMemoryIndex :
建立字符串索引hprofStringCache(Key-value):key是字符ID,value是字符串;
作用: 可以根据类名,查询到字符ID,也可以根据字符ID查询到类名。
建立类名索引classNames(Key-value):key是类对象ID,value是类字符串ID;
作用: 根据类对象ID查询类字符串ID。
建立实例索引**instanceIndex(**Key-value):key是实例对象ID,value是该对象在hprof文件中的位置以及类对象ID;
作用: 快速定位实例的所处位置,方便解析实例字段的值。
建立类对象索引classIndex(Key-value):key是类对象ID,value是其他字段的二进制组合(父类ID、实例大小等等);
作用: 快速定位类对象的所处位置,方便解析类字段类型。
建立对象数组索引objectArrayIndex(Key-value):key是类对象ID,value是其他字段的二进制组合(hprof文件位置等等);
作用: 快速定位对象数组的所处位置,方便解析对象数组引用的对象。
建立原始数组索引primitiveArrayIndex(Key-value):key是类对象ID,value是其他字段的二进制组合(hprof文件位置、元素类型等等);
2.2.2 找到泄漏的对象
1)由于需要检测的对象被
com.squareup.leakcanary.KeyedWeakReference 持有,所以可以根据
com.squareup.leakcanary.KeyedWeakReference 类名查询到类对象ID;
- 解析对应类的实例域,找到字段名以及引用的对象ID,即泄漏的对象ID;
2.2.3找到最短的GCRoot引用链
根据解析到的GCRoot对象和泄露的对象,在graph中搜索最短引用链,这里采用的是广度优先遍历的算法进行搜索的:
//PathFinder
private fun State.findPathsFromGcRoots(): PathFindingResults {
enqueueGcRoots()//1
val shortestPathsToLeakingObjects = mutableListOf<ReferencePathNode>()
visitingQueue@ while (queuesNotEmpty) {val node = poll()//2if (checkSeen(node)) {//2throw IllegalStateException("Node $node objectId=${node.objectId} should not be enqueued when already visited or enqueued")}if (node.objectId in leakingObjectIds) {//3shortestPathsToLeakingObjects.add(node)// Found all refs, stop searching (unless computing retained size)if (shortestPathsToLeakingObjects.size == leakingObjectIds.size) {//4if (computeRetainedHeapSize) {listener.onAnalysisProgress(FINDING_DOMINATORS)} else {break@visitingQueue}}}when (val heapObject = graph.findObjectById(node.objectId)) {//5is HeapClass -> visitClassRecord(heapObject, node)is HeapInstance -> visitInstance(heapObject, node)is HeapObjectArray -> visitObjectArray(heapObject, node)}
}
return PathFindingResults(shortestPathsToLeakingObjects, dominatedObjectIds)
}
1)GCRoot对象都入队;
2)队列中的对象依次出队,判断对象是否访问过,若访问过,则抛异常,若没访问过则继续;
3)判断出队的对象id是否是需要检测的对象,若是则记录下来,若不是则继续;
4)判断已记录的对象ID数量是否等于泄漏对象的个数,若相等则搜索结束,相反则继续;
5)根据对象类型(类对象、实例对象、对象数组对象),按不同方式访问该对象,解析对象中引用的对象并入队,并重复2)。
入队的元素有相应的数据结构ReferencePathNode ,原理是链表,可以用来反推出引用链。
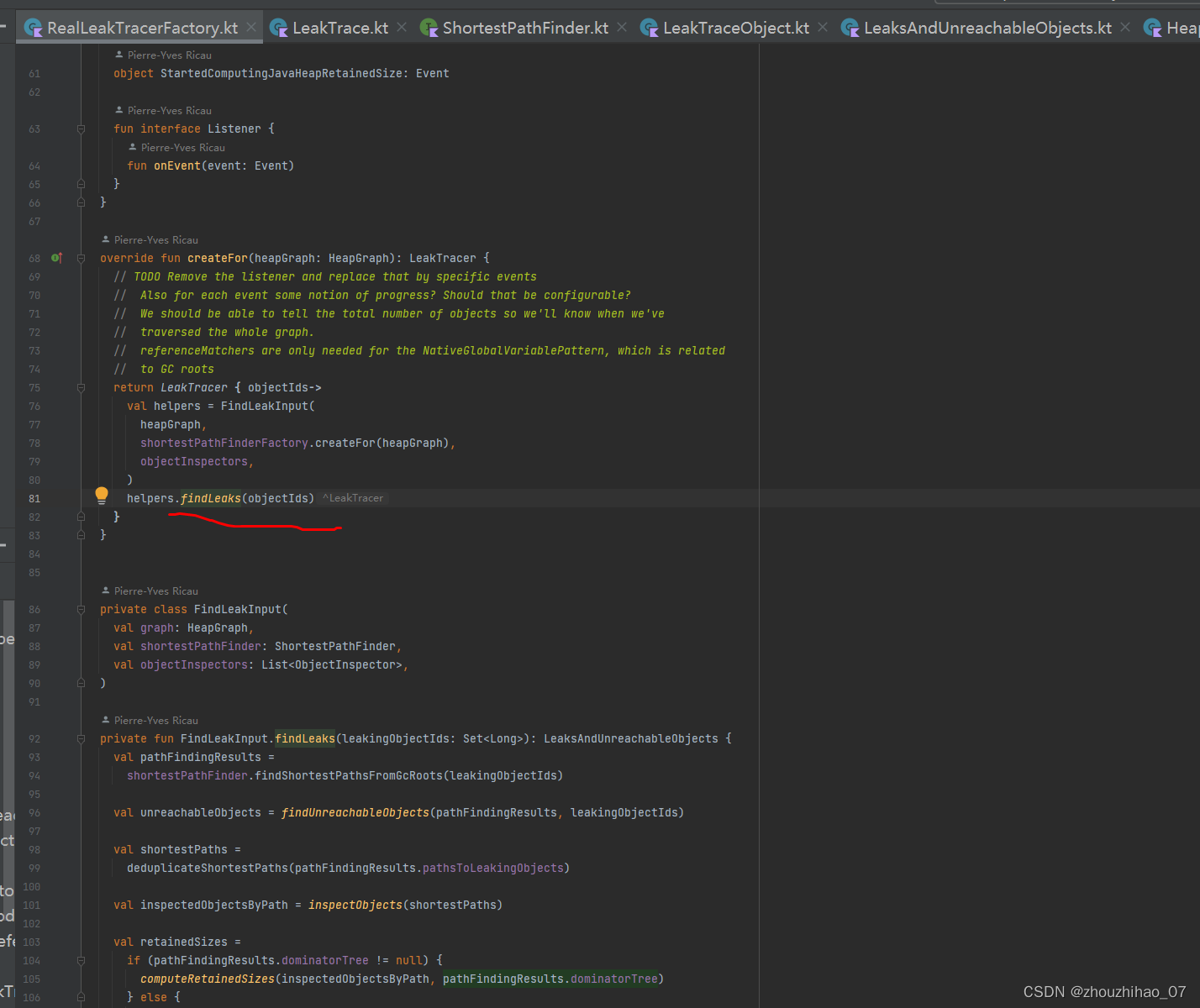
findShortestPathsFromGcRoots 是查找泄漏对象到Gcroot最短路径,这个我和其他同类文章认为的不同,他们觉得是只有最短路径才能被直接访问到,而其他更长的路径引用中可能包含其他非直接引用的对象,这些对象不可能是泄漏点。我没法理解这样的解释,我个人理解是这个算法用的是广度优先算法(因为与深度优先算法比,广度优先的长处是速度快,缺点是占用空间),从下面一层一层的查,找到最近最短的路径,这个肯定是泄漏的,是要我们处理的。而其他引用路径就算有也是下一次去解决(这种情况从概率上说是很小的),也就是就算有也会在下一次找到,在下一次还是最短路径。这种算法是保证最快的找到泄漏的引用链(反正你所有的泄漏都是要处理的,按这个顺序能保证最快)。
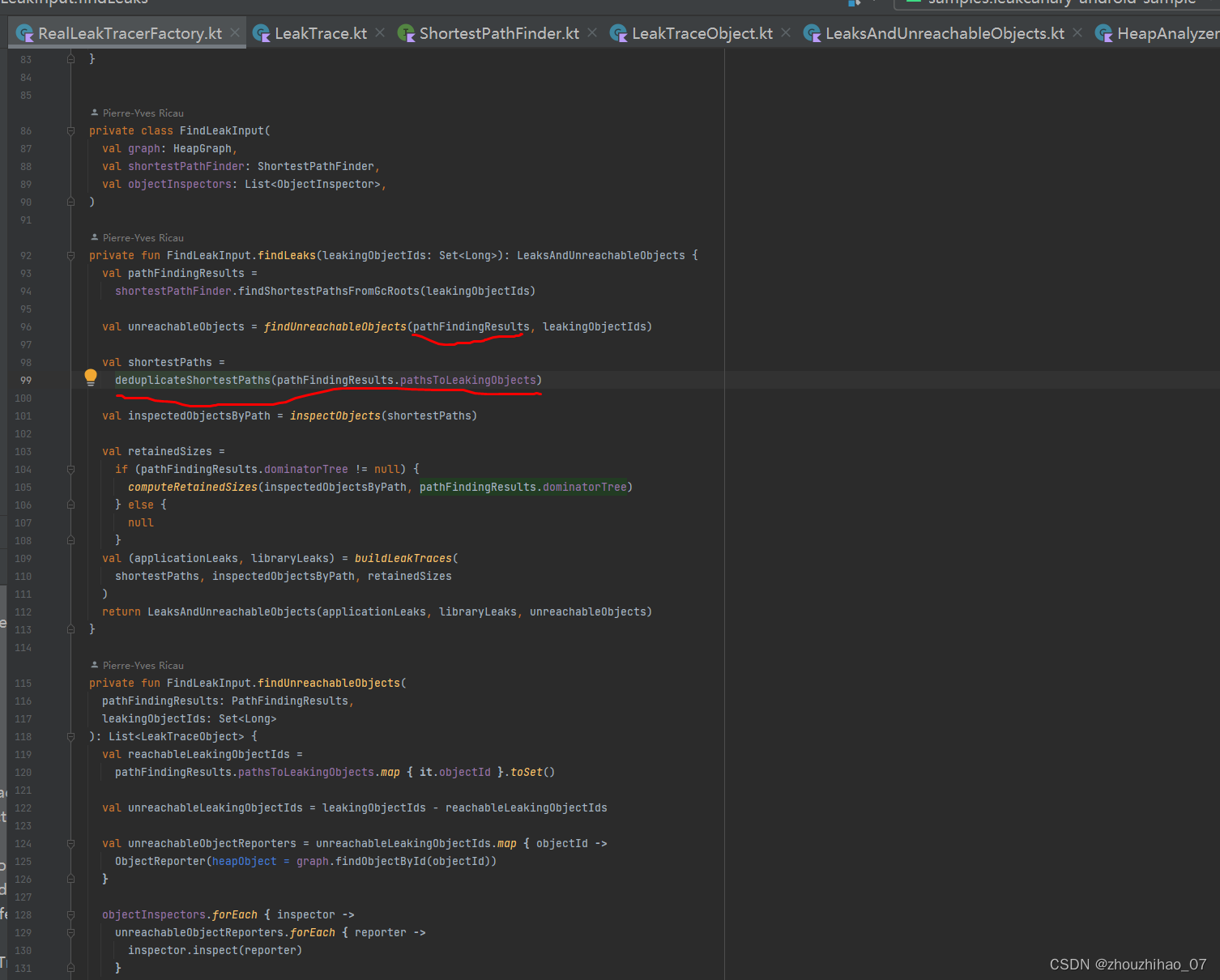
下图就是我们使用的时候收到的通知消息,可见一斑。
就先到这里吧,有时间再把里面的细节梳理一下吧。