日本手做网站sem竞价是什么意思
反向传播算法与随机搜索算法的比较
在这篇文章中,我们将通过一个简单的线性回归问题来比较反向传播算法和随机搜索算法的性能。我们将使用Python代码来实现这两种算法,并可视化它们的梯度下降过程。
反向传播算法
反向传播算法是深度学习和神经网络训练中的一个核心算法。它通过自动计算损失函数相对于网络中每个参数的梯度,并据此更新参数,从而快速且有效地找到最优解。
反向传播算法的实现
以下是使用反向传播算法的Python代码实现:
import numpy as np
import matplotlib.pyplot as plt# 生成数据集
np.random.seed(0)
X = np.random.rand(100, 1)
y = 2 * X + 1 + np.random.randn(100, 1) * 0.1# 初始化参数
w = np.random.randn()
b = np.random.randn()# 记录每次迭代的损失
losses = []# 使用反向传播算法
learning_rate = 0.01
for i in range(1000):predictions = w * X + bloss = np.mean((predictions - y) ** 2)losses.append(loss)# 计算梯度dw = np.mean((predictions - y) * X)db = np.mean(predictions - y)# 更新参数w -= learning_rate * dwb -= learning_rate * db# 绘制损失曲线
plt.plot(losses, label='Backpropagation Loss')
plt.xlabel('Iteration')
plt.ylabel('Loss')
plt.title('Loss vs. Iteration (Backpropagation)')
plt.legend()
plt.show()

随机搜索算法
随机搜索算法是一种简单的优化方法,它通过随机调整参数来寻找最优解。这种方法通常效率较低,且难以保证找到最优解。
随机搜索算法的实现
以下是使用随机搜索算法的Python代码实现:
import numpy as np
import matplotlib.pyplot as plt# 生成数据集
np.random.seed(0)
X = np.random.rand(100, 1)
y = 2 * X + 1 + np.random.randn(100, 1) * 0.1# 初始化参数
w = np.random.randn()
b = np.random.randn()# 记录每次迭代的损失
losses = []# 随机搜索参数
for i in range(1000):predictions = w * X + bloss = np.mean((predictions - y) ** 2)losses.append(loss)# 随机调整权重和偏置w += (np.random.rand() - 0.5) * 0.01b += (np.random.rand() - 0.5) * 0.01# 绘制损失曲线
plt.plot(losses, label='Random Search Loss')
plt.xlabel('Iteration')
plt.ylabel('Loss')
plt.title('Loss vs. Iteration (Random Search)')
plt.legend()
plt.show()
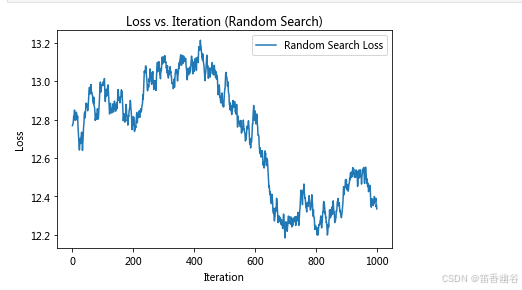
性能对比
通过运行上述两段代码,我们可以观察到两种算法在梯度下降过程中损失函数的变化。通常,使用反向传播算法的图表会显示出更平滑且更快的下降趋势,表明算法能够更有效地最小化损失函数。相比之下,随机搜索算法的损失下降速度较慢,且波动较大,说明其优化效果不如反向传播算法。
结论
反向传播算法在训练神经网络时具有显著的优势,它能够快速且自动地找到最优解,而随机搜索算法则效率较低,难以保证找到最优解。通过可视化梯度下降过程,我们可以直观地比较这两种算法的性能差异。