网站建设做哪个科目如何做好市场推广
笔记
9.5. 机器翻译与数据集 — 动手学深度学习 2.0.0 documentation
1.下载文件 读文件
2.处理数据 在所有标点符号前面加空格 后面用于分割 因为法语英语可能有半角全角的字符区分用utf编码的方式统一成半角字符的空格
3.因为分隔用的是空格split 所有vocab是没有空格的
4.分割之后 分别是词源和翻译两个list
![]()
分别都是一个大list装着不同的小list,小list对应的是原本的词语加字符,用空格split之后分开装了
5.后续用vocab处理, 提前加入reserved_tokens=['<pad>', '<bos>', '<eos>'] 这三个 pad是后续padding用的就是填充的缩写,填充标识符,bos是开始标识符,eos是结束标识符 因为固定'unknown'排第一,下标0,所有这三个正好是下标1,2,3的位置
min_freq=2出现次数少于2次的生僻词过滤,处理后得到词源和翻译字典 每一个下标对应一个word而不是字符
#此处用字典是为了之后将word和字符转成字典中按频率排的数字list,减少内存和方便操作
6.之后将词源内容src每一句转成数字list,但同时还要加上eos标识符标志结束,因为没有其他办法标志句子的结束,
标识符在vocab下标是3
![]()
7.之后将所有lines中的文本每一行line填充为num_steps长度,当num_steps为8的时候
以str的角度来看go.这个文本转换成vocab的数字序列之后只有2的长度,加上eos标志符也只有3.所以需要填充为go.<eos><pad><pad><pad><pad><pad> 这样的话就是长度为8了
以数字序列来看就是[9, 4, 3, 1, 1, 1, 1, 1] 9是go,.是4, eos是3 注意是在eos后面加
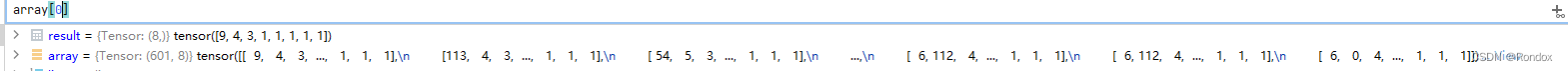
因为要方便后面算valid有效长度
8.算有效长度:
valid_len = (array != vocab['<pad>']).type(torch.int32).sum(1)
用下标0组实例分解
(array != vocab['<pad>']).type(torch.int32) 布尔转int

最后以全组再用sum在1维处减少维数

得到有效长度list
9.最后就是构成传数据的函数load_data_nmt返回数据 返回四个成员组成的tuple
import os
import torch
from d2l import torch as d2l#@save
d2l.DATA_HUB['fra-eng'] = (d2l.DATA_URL + 'fra-eng.zip','94646ad1522d915e7b0f9296181140edcf86a4f5')#@save
def read_data_nmt():"""载入“英语-法语”数据集"""data_dir = d2l.download_extract('fra-eng')with open(os.path.join(data_dir, 'fra.txt'), 'r',encoding='utf-8') as f:return f.read()raw_text = read_data_nmt()
print(raw_text[:75])#@save
def preprocess_nmt(text):"""预处理“英语-法语”数据集"""def no_space(char, prev_char):return char in set(',.!?') and prev_char != ' '# 使用空格替换不间断空格# 使用小写字母替换大写字母text = text.replace('\u202f', ' ').replace('\xa0', ' ').lower()# 在单词和标点符号之间插入空格out = [' ' + char if i > 0 and no_space(char, text[i - 1]) else charfor i, char in enumerate(text)]return ''.join(out)text = preprocess_nmt(raw_text)
print(text[:80])#@save
def tokenize_nmt(text, num_examples=None):"""词元化“英语-法语”数据数据集"""source, target = [], []for i, line in enumerate(text.split('\n')):if num_examples and i > num_examples:breakparts = line.split('\t')if len(parts) == 2:source.append(parts[0].split(' '))target.append(parts[1].split(' '))return source, targetsource, target = tokenize_nmt(text)
source[:6], target[:6]#@save
def show_list_len_pair_hist(legend, xlabel, ylabel, xlist, ylist):"""绘制列表长度对的直方图"""d2l.set_figsize()_, _, patches = d2l.plt.hist([[len(l) for l in xlist], [len(l) for l in ylist]])d2l.plt.xlabel(xlabel)d2l.plt.ylabel(ylabel)for patch in patches[1].patches:patch.set_hatch('/')d2l.plt.legend(legend)show_list_len_pair_hist(['source', 'target'], '# tokens per sequence','count', source, target);src_vocab = d2l.Vocab(source, min_freq=2,reserved_tokens=['<pad>', '<bos>', '<eos>'])#空格只做分割 vocab是没有空格的 src_vocab[' ']
len(src_vocab)#@save
def truncate_pad(line, num_steps, padding_token):#padding_token指用哪个token用于填充padding 传进去的是vocab的下标"""截断或填充文本序列 truncate翻译是截断"""if len(line) > num_steps:return line[:num_steps] # 截断return line + [padding_token] * (num_steps - len(line)) # 填充#line是[47, 4] 这里意思是往里面一直加元素这样一个[1]truncate_pad(src_vocab[source[0]], 10, src_vocab['<pad>'])#@save
def build_array_nmt(lines, vocab, num_steps):"""将机器翻译的文本序列转换成小批量"""lines = [vocab[l] for l in lines]lines = [l + [vocab['<eos>']] for l in lines]#数字list加上一个eos标识符的下标 所以加了一个结束的标志下标 比如[9,4]->[9,4,3]array = torch.tensor([truncate_pad(l, num_steps, vocab['<pad>']) for l in lines])valid_len = (array != vocab['<pad>']).type(torch.int32).sum(1)return array, valid_len#@save
def load_data_nmt(batch_size, num_steps, num_examples=600):"""返回翻译数据集的迭代器和词表"""text = preprocess_nmt(read_data_nmt())source, target = tokenize_nmt(text, num_examples)src_vocab = d2l.Vocab(source, min_freq=2,reserved_tokens=['<pad>', '<bos>', '<eos>'])tgt_vocab = d2l.Vocab(target, min_freq=2,reserved_tokens=['<pad>', '<bos>', '<eos>'])src_array, src_valid_len = build_array_nmt(source, src_vocab, num_steps)tgt_array, tgt_valid_len = build_array_nmt(target, tgt_vocab, num_steps)data_arrays = (src_array, src_valid_len, tgt_array, tgt_valid_len)data_iter = d2l.load_array(data_arrays, batch_size)return data_iter, src_vocab, tgt_vocabtrain_iter, src_vocab, tgt_vocab = load_data_nmt(batch_size=2, num_steps=8)
for X, X_valid_len, Y, Y_valid_len in train_iter:print('X:', X.type(torch.int32))print('X的有效长度:', X_valid_len)print('Y:', Y.type(torch.int32))print('Y的有效长度:', Y_valid_len)break