c .net 做网站无锡网站建设seo
一、介绍
BERT模型的出现导致了NLP的重大进展。BERT的架构源自Transformer,在各种下游任务上实现了最先进的结果:语言建模,下一句预测,问答,NER标记等。
大型语言模型:BERT — 来自变压器的双向编码器表示
了解BERT如何构建最先进的嵌入
towardsdatascience.com
尽管BERT具有出色的性能,但研究人员仍在继续试验其配置,以期获得更好的指标。幸运的是,他们成功地提出了一种名为RoBERTa的新模型 - 稳健优化的BERT方法。
在本文中,我们将参考官方的RoBERTa论文,其中包含有关该模型的深入信息。简而言之,RoBERTa由对原始BERT模型的几个独立改进组成 - 包括架构在内的所有其他原则保持不变。本文将介绍和解释所有改进。
二、RoBERTa功能介绍
2.1. 动态遮罩
从BERT的架构中,我们记得在预训练期间,BERT通过尝试预测一定比例的屏蔽令牌来执行语言建模。原始实现的问题在于,为跨不同批次的给定文本序列选择的掩码标记有时是相同的。
更准确地说,训练数据集被复制 10 次,因此每个序列仅以 10 种不同的方式被屏蔽。请记住,BERT运行40个训练时期,每个具有相同掩码的序列被传递给BERT四次。正如研究人员发现的那样,使用动态掩蔽稍微好一些,这意味着每次将序列传递给BERT时都会唯一地生成掩码。总体而言,这导致训练期间重复的数据较少,使模型有机会处理更多不同的数据和掩码模式。
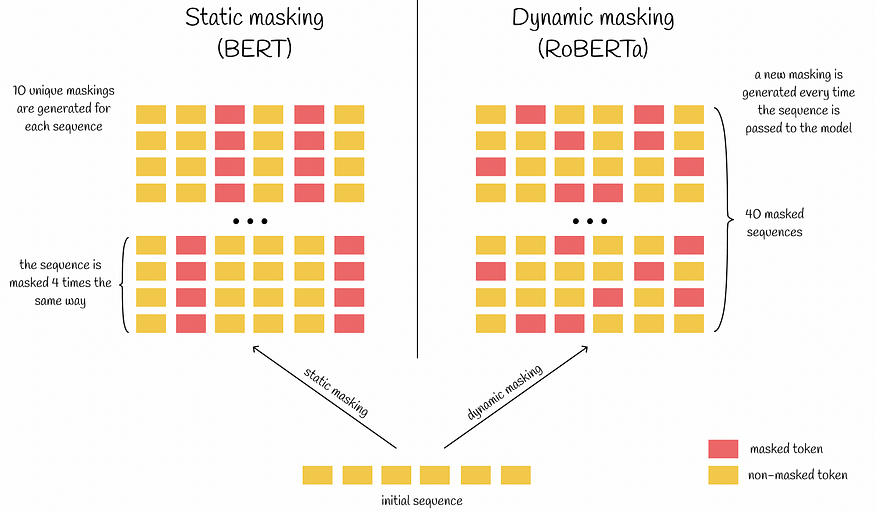
静态屏蔽与动态屏蔽
2.2. 下一句预测
该论文的作者进行了研究,以找到一种最佳方法来模拟下一个句子预测任务。因此,他们发现了几个有价值的见解:
- 删除下一句预测损失会导致性能稍好。
- 与传递由多个句子组成的序列相比,将单个自然句子传递到 BERT 输入会损害性能。解释这种现象的最可能的假设之一是模型很难仅依靠单个句子学习长期依赖关系。
- 通过从单个文档而不是多个文档中采样连续句子 来构建输入序列更有益。通常,序列总是由单个文档的连续完整句子构造而成,因此总长度最多为 512 个标记。当我们到达文档的末尾时,问题就出现了。在这方面,研究人员比较了是否值得停止对此类序列的句子进行采样,或者是否值得对下一个文档的前几个句子进行额外采样(并在文档之间添加相应的分隔符标记)。结果表明,第一种选择更好。
最终,对于最终的RoBERTa实现,作者选择保留前两个方面,省略第三个方面。尽管观察到第三个见解背后的改进,但研究人员并没有不继续下去,否则,这将使以前实现之间的比较更加成问题。发生这种情况是因为到达文档边界并在那里停止意味着输入序列将包含少于 512 个标记。为了在所有批次中具有相似数量的令牌,在这种情况下需要增加批大小。这导致了批次大小的变化和更复杂的比较,这是研究人员想要避免的。

2.3. 增加批量大小
NLP的最新进展表明,随着学习率和训练步骤数量的适当减少,批量大小的增加通常会提高模型的性能。
提醒一下,BERT基础模型在256个序列的批量大小上进行了一百万步的训练。作者尝试在2K和8K的批量大小上训练BERT,并选择后一个值来训练RoBERTa。相应的训练步数和学习率值分别变为31K和1e-3。
同样重要的是要记住,批量大小的增加会导致通过称为“梯度累积”的特殊技术更容易并行化。
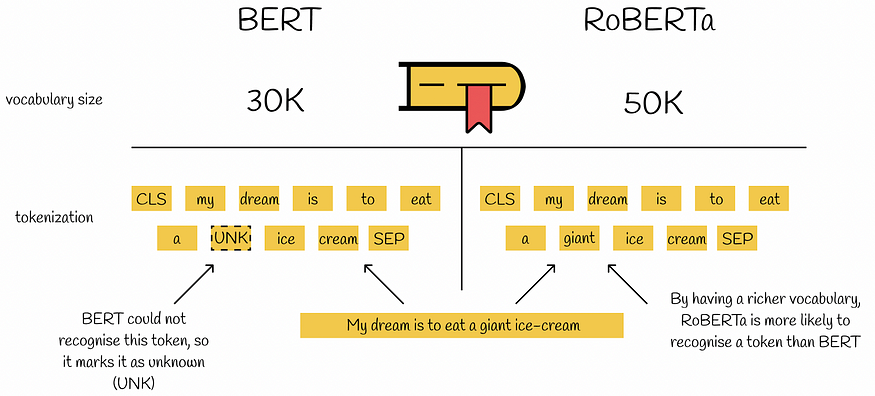
2.4. 字节文本编码
在NLP中,存在三种主要类型的文本标记化:
- 字符级标记化
- 子词级标记化
- 单词级标记化
原始的BERT使用词汇量为30K的子词级标记化,这是在输入预处理和使用几种启发式方法后学习的。RoBERTa使用字节而不是Unicode字符作为子词的基础,并将词汇表大小扩展到50K,而无需任何预处理或输入标记化。这导致BERT基础和BERT大型模型分别有15M和20M的附加参数。RoBERTa中引入的编码版本显示出比以前稍差的结果。
然而,与BERT相比,RoBERTa中的词汇量增长允许在不使用未知标记的情况下对几乎任何单词或子单词进行编码。这给RoBERTa带来了相当大的优势,因为该模型现在可以更全面地理解包含生僻词的复杂文本。
三、预训练
除此之外,RoBERTa应用了上述所有四个方面,具有与BERT large相同的架构参数。RoBERTa的参数总数为355M。
RoBERTa在五个海量数据集的组合上进行预训练,总共产生160 GB的文本数据。相比之下,BERT large 仅在 13 GB 的数据上进行预训练。最后,作者将训练步骤的数量从100K增加到500K。
因此,RoBERTa在最流行的基准测试中在XLNet上的表现优于BERT。
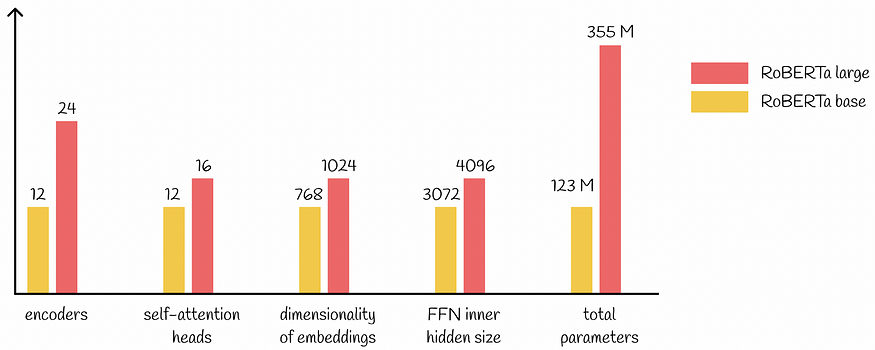
四、RoBert版本
与BERT类似,研究人员开发了两个版本的RoBERTa。基本版和大型版本中的大多数超参数都是相同的。下图显示了主要差异:
- RoBERTa中的微调过程类似于BERT。
-
五、结论
- 在本文中,我们研究了BERT的改进版本,该版本通过引入以下方面来修改原始训练程序:
- 动态遮罩
- 省略下一句预测目标
- 较长句子的训练
- 增加词汇量
- 使用更大的数据批次进行更长时间的训练
- 由此产生的RoBERTa模型在顶级基准测试上似乎优于其祖先。尽管配置更复杂,但RoBERTa仅添加了15M个附加参数,保持了与BERT相当的推理速度。
-
资源
- RoBERTa:一种鲁棒优化的BERT预训练方法
- 维亚切斯拉夫·叶菲莫夫