国内外网站建设百度一下你就知道啦
1.问题:向量检索也易混淆,而关键字会更精准
在实际生产中,传统的关键字检索(稀疏表示)与向量检索(稠密表示)各有利弊。
举个具体例子,比如文档中包含很长的专有名词,
关键字检索往往更精准,
而向量检索容易引入概念混淆。
# 背景说明:在医学中“小细胞肺癌”和“非小细胞肺癌”是两种不同的癌症query = "非小细胞肺癌的患者"documents = ["玛丽患有肺癌,癌细胞已转移","刘某肺癌I期","张某经诊断为非小细胞肺癌III期","小细胞肺癌是肺癌的一种"
]query_vec = get_embeddings([query])[0]
doc_vecs = get_embeddings(documents)print("Cosine distance:")
for vec in doc_vecs:print(cos_sim(query_vec, vec))#### 输出Cosine distance:
0.8915268056308027
0.8895478505819983
0.9039165614288258
0.9131441645902685
2.解决:混合检索,结合不同检索算法
所以,有时候我们需要结合不同的检索算法,来达到比单一检索算法更优的效果。这就是混合检索。
混合检索的核心是,综合文档 d d d 在不同检索算法下的排序名次(rank),为其生成最终排序。
一个最常用的算法叫 Reciprocal Rank Fusion(RRF)
r r f ( d ) = ∑ a ∈ A 1 k + r a n k a ( d ) rrf(d)=\sum_{a\in A}\frac{1}{k+rank_a(d)} rrf(d)=∑a∈Ak+ranka(d)1
其中 A A A 表示所有使用的检索算法的集合, r a n k a ( d ) rank_a(d) ranka(d) 表示使用算法 a a a 检索时,文档 d d d 的排序, k k k 是个常数。
很多向量数据库都支持混合检索,比如 Weaviate、Pinecone 等。也可以根据上述原理自己实现。
3.简单示例
3.1 基于关键字检索的排序
import timeclass MyEsConnector:def __init__(self, es_client, index_name, keyword_fn):self.es_client = es_clientself.index_name = index_nameself.keyword_fn = keyword_fndef add_documents(self, documents):'''文档灌库'''if self.es_client.indices.exists(index=self.index_name):self.es_client.indices.delete(index=self.index_name)self.es_client.indices.create(index=self.index_name)actions = [{"_index": self.index_name,"_source": {"keywords": self.keyword_fn(doc),"text": doc,"id": f"doc_{i}"}}for i, doc in enumerate(documents)]helpers.bulk(self.es_client, actions)time.sleep(1)def search(self, query_string, top_n=3):'''检索'''search_query = {"match": {"keywords": self.keyword_fn(query_string)}}res = self.es_client.search(index=self.index_name, query=search_query, size=top_n)return {hit["_source"]["id"]: {"text": hit["_source"]["text"],"rank": i,}for i, hit in enumerate(res["hits"]["hits"])}
from chinese_utils import to_keywords # 使用中文的关键字提取函数# 引入配置文件
ELASTICSEARCH_BASE_URL = os.getenv('ELASTICSEARCH_BASE_URL')
ELASTICSEARCH_PASSWORD = os.getenv('ELASTICSEARCH_PASSWORD')
ELASTICSEARCH_NAME= os.getenv('ELASTICSEARCH_NAME')es = Elasticsearch(hosts=[ELASTICSEARCH_BASE_URL], # 服务地址与端口http_auth=(ELASTICSEARCH_NAME, ELASTICSEARCH_PASSWORD), # 用户名,密码
)# 创建 ES 连接器
es_connector = MyEsConnector(es, "demo_es_rrf", to_keywords)# 文档灌库
es_connector.add_documents(documents)# 关键字检索
keyword_search_results = es_connector.search(query, 3)print(json.dumps(keyword_search_results, indent=4, ensure_ascii=False))
{"doc_2": {"text": "张某经诊断为非小细胞肺癌III期","rank": 0},"doc_0": {"text": "玛丽患有肺癌,癌细胞已转移","rank": 1},"doc_3": {"text": "小细胞肺癌是肺癌的一种","rank": 2}
}```## 3.2 基于向量检索的排序```python
# 创建向量数据库连接器
vecdb_connector = MyVectorDBConnector("demo_vec_rrf", get_embeddings)# 文档灌库
vecdb_connector.add_documents(documents)# 向量检索
vector_search_results = {"doc_"+str(documents.index(doc)): {"text": doc,"rank": i}for i, doc in enumerate(vecdb_connector.search(query, 3)["documents"][0])
} # 把结果转成跟上面关键字检索结果一样的格式print(json.dumps(vector_search_results, indent=4, ensure_ascii=False))
{"doc_3": {"text": "小细胞肺癌是肺癌的一种","rank": 0},"doc_2": {"text": "张某经诊断为非小细胞肺癌III期","rank": 1},"doc_0": {"text": "玛丽患有肺癌,癌细胞已转移","rank": 2}
}
3.3 基于 RRF 的融合排序
def rrf(ranks, k=1):ret = {}# 遍历每次的排序结果for rank in ranks:# 遍历排序中每个元素for id, val in rank.items():if id not in ret:ret[id] = {"score": 0, "text": val["text"]}# 计算 RRF 得分ret[id]["score"] += 1.0/(k+val["rank"])# 按 RRF 得分排序,并返回return dict(sorted(ret.items(), key=lambda item: item[1]["score"], reverse=True))
import json# 融合两次检索的排序结果
reranked = rrf([keyword_search_results, vector_search_results])print(json.dumps(reranked, indent=4, ensure_ascii=False))
{"doc_2": {"score": 1.5,"text": "张某经诊断为非小细胞肺癌III期"},"doc_3": {"score": 1.3333333333333333,"text": "小细胞肺癌是肺癌的一种"},"doc_0": {"score": 0.8333333333333333,"text": "玛丽患有肺癌,癌细胞已转移"}
}
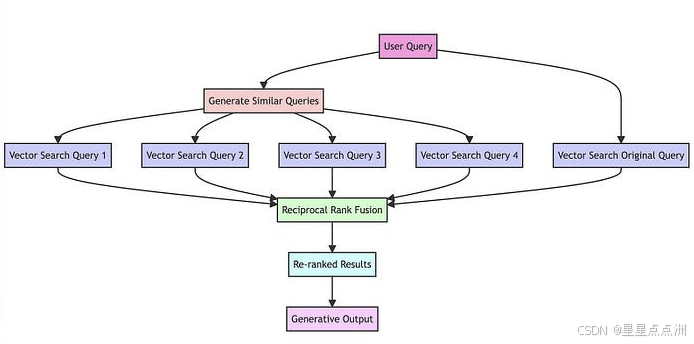
RAG-Fusion
RAG-Fusion 就是利用了 RRF 的原理来提升检索的准确性。
RRF (reciprocal rank fusion 倒秩融合)
原始项目(非常简短的演示代码):https://github.com/Raudaschl/rag-fusion