甘肃网站设计公司网站维护公司
1.前言
RDD
JAVA中的IO
1.小知识点穿插
1. 装饰者设计模式
装饰者设计模式:本身功能不变,扩展功能.
举例: 数据流的读取
一层一层的包装,进而将功能进行进一步的扩展

2.sleep和wait的区别
本质区别是字体不一样,sleep斜体,wait正常
斜体是静态方法
sleep:静态方法,和对象无关
t1.sleep 当前休眠的不是t1线程,而是调用方法的线程,如果在主线程运行,调用的就是主线程,
与对象无关,得不到对象锁
wait :成员方法 ,与对象相关
t2.wait 当前等待的线程是t2线程
能得到对象锁,能释放.
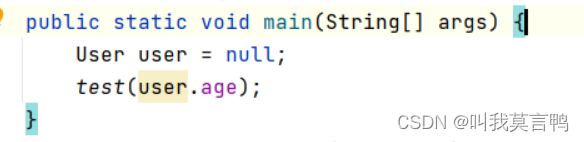
空指针异常:调用一个为null的对象的成员属性或成员方法,会发生空指针异常,
注意 是成员的 ,如果是静态的,与动态就无关了.
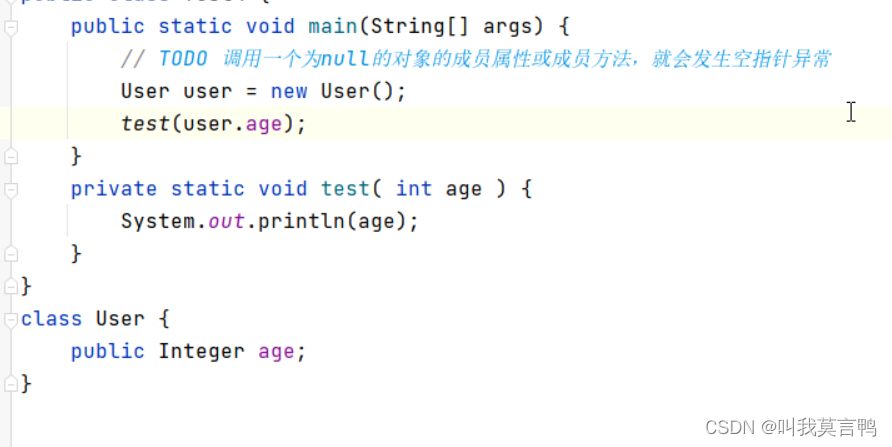
为什么会出现空指针?
报错的时候,给的是.class的位置,不一定完全对应java的问题,
去看字节码Terminal 输入javap -c +名称 -v的话,更详细

intValue是一个成员方法,但是此时age没有赋值,是null, 空对象的成员方法调用
this与super

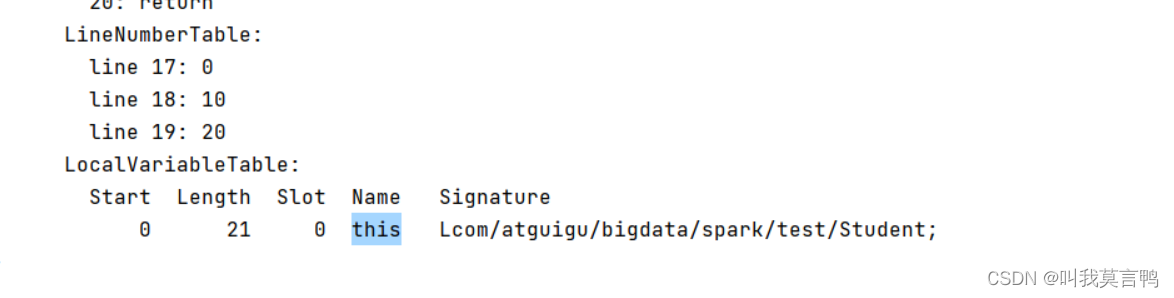
this是当前方法的局部变量,
super只在编译时出现,this可以在运行时出现
3.关于import *
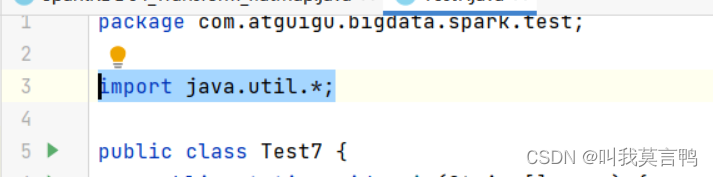
这个是给javac 用的,让javac自动去找
编译成.class 时,需要什么就导什么,而不是全部都导
2.正题
1.注意点 切片与读取的不同
HADOOP切片逻辑是均分
但是读取数据进行分区保存时,不能均分,
HADOOP是按行读,而不是字节,
为啥HADOOP按行读取,一行就是一个业务数据
但是切片是均分,指的是字节均分
2.hadoop读取按照偏移量读取,同一个数据的偏移量不能被重复读取,也就是必须重来?
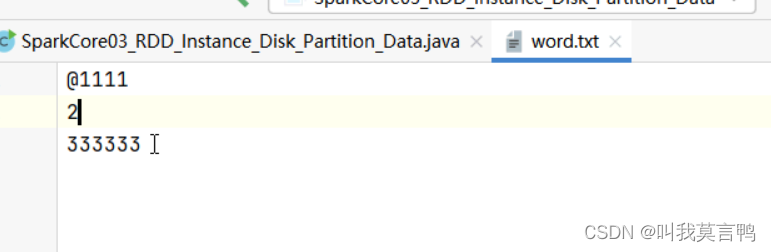
5+2+1+2+6 =16
4个分区,能均分
4个分区,读按行读,所以最后一个是空 数据倾斜
2.转换算子
1.是什么?
Transformation转换算子
转换方法
算子是个啥?
认知心理学 解决问题的状态: 初始状态(提出问题) -> 解决 不强调过程
转换:一个东西变成另外一个东西
所谓的转换算子,就是调用RDD对象的功能(方法)转变成一个新RDD





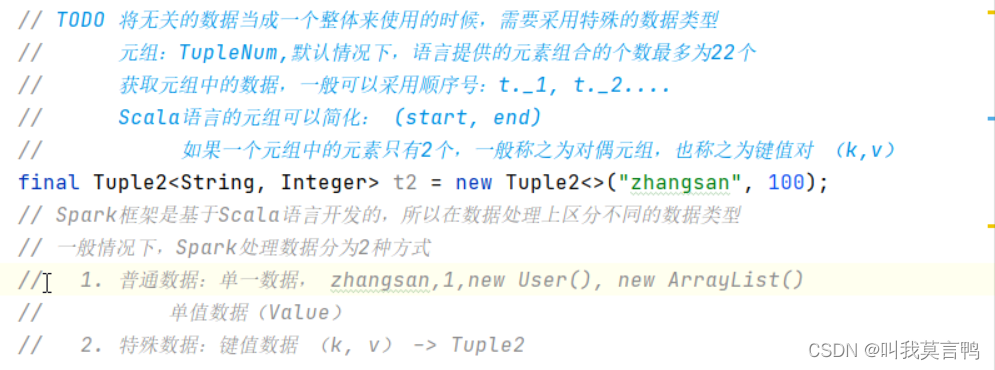
元组,需要先知道一共多少个数据, 默认元组最多为22个
元组是专门用来存放无关数据的,不同数据类型也能存
取的时候

如果元组中元素就两个,称为对偶元组,也称为键值对
RDD不保存(处理后的)数据,RDD是容器,但是容器是工具,存储数据的,是数组,链表,而不是容器

加这个才能将类中的方法可以进行函数式
只需要考虑方法输入输出

因为必须有返回值,马丁知道,所以return 可以省略
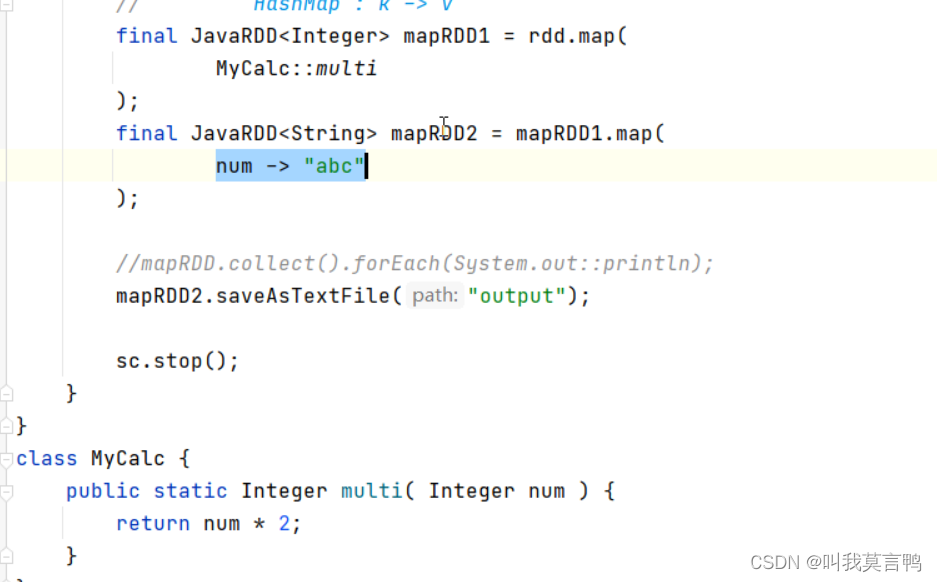
想省略参数,得有方法
如果一个整体需要拆分成多个个体,这种操作,叫做扁平化
Flat就是变
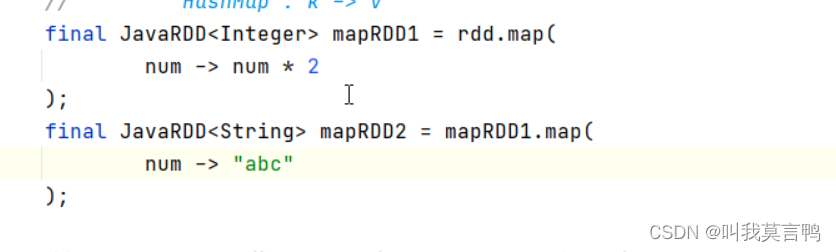
3.map
一个输入 一个输出 不能一个输入多个输出
package com.atguigu.core.rdd.transform;import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;import java.util.Arrays;
import java.util.List;public class SparkRDDmap {public static void main(String[] args) {JavaSparkContext sc = new JavaSparkContext("local[*]","SPARK_mapT");List<Integer> dataList = Arrays.asList(1,2,3,4);JavaRDD<Integer> rdd = sc.parallelize(dataList, 3);JavaRDD<Integer> rddMap = rdd.map(in -> in * 2);// 用流的形式进行操作rddMap.collect().forEach(System.out::println);sc.stop();}
}
4.flatMap
1.flatMap与Map的区别
map:一个输入,一个输出 做不到一个输入多个输出 也做不到多个输入少个输出
flatmap 扁平化 一个输入 n个输出 n(0和任意正整数)
整体拆成个体,但是每个个体都要使用
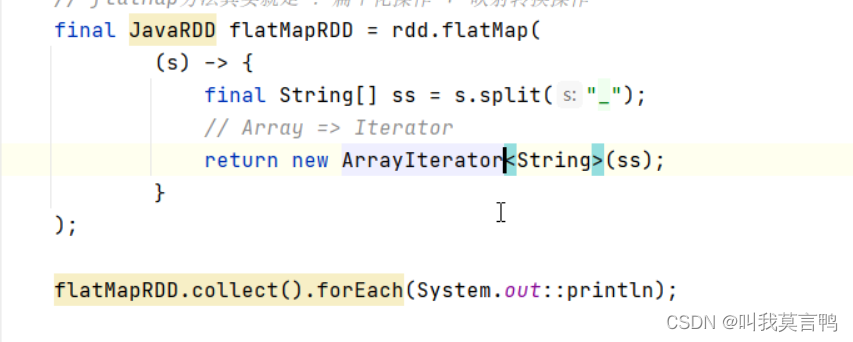
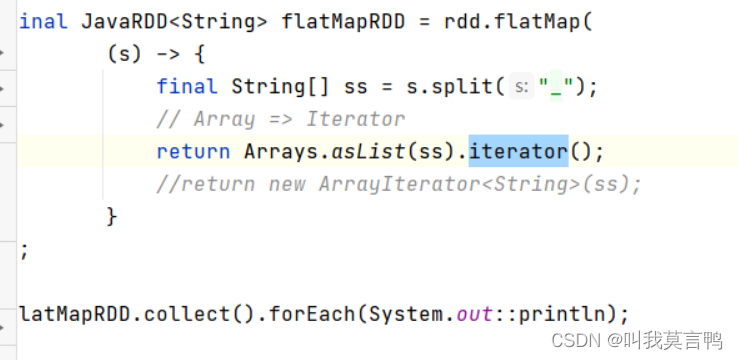
注意,这里的return 是泛型(不加也行) ,也可以是迭代器
5.分组
1.注意点 一个组的数据必定在一个分区
分组不是分区,分组是将数据按组划分,是将所有数据重新进行划分,按组成编制,
本来数据是单独放入区中的,而现在的数据,是以组为单位放入区的,而不是说一个分区里面只能有一个组,分组与分区,无关
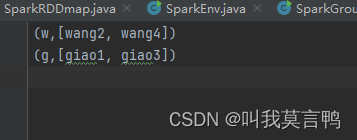
Spark的分组,一个组的数据放置在一个分区中(把之前的分区聚合了)

组是输出 组内数据是输入
输出 就是分组规则
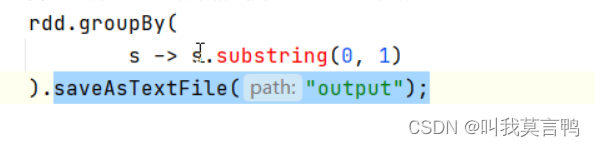
这种写法,直接. 中间结果不会在内存中留下
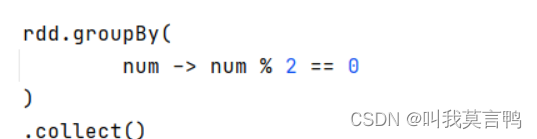
奇偶分组,这个的组名是true false
奇偶分组,去掉==0时,组名为0 1
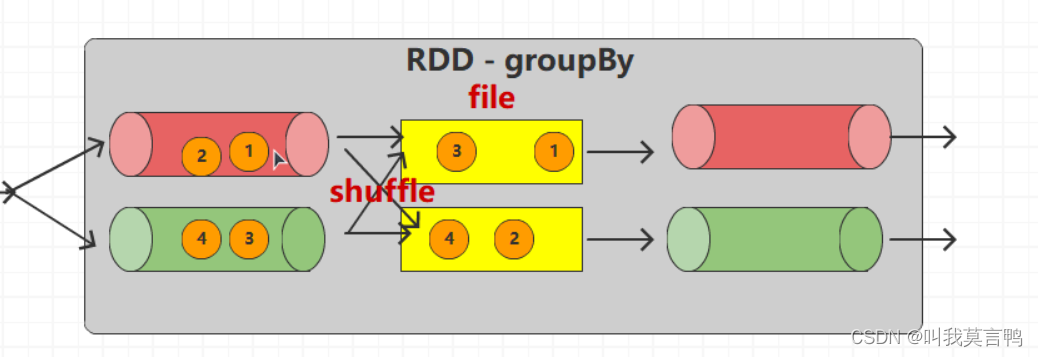
分组过程中,将已分组的数据先放入磁盘,分完组,重新按组分流,动态改变分区数量
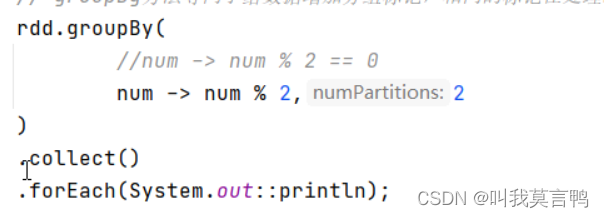
默认分区数是不变的,这里主动修改分区数,才改变的