可以做课程的网站搜狗搜索引擎优化论文

现在,您已经了解了如何调整和对齐大型语言模型以适应您的任务,让我们讨论一下将模型集成到应用程序中需要考虑的事项。
在这个阶段有许多重要的问题需要问。第一组问题与您的LLM在部署中的功能有关。您需要模型生成完成的速度有多快?您有多少计算预算可用?您是否愿意为改善推理速度或降低存储空间而牺牲模型性能?
第二组问题与您的模型可能需要的额外资源有关。您是否打算让您的模型与外部数据或其他应用程序进行交互?如果是的话,您将如何连接到这些资源?
最后,还有一个问题,即您的模型将如何被使用。您的模型将通过什么样的预期应用程序或API界面来使用?
让我们首先探讨一些在将模型部署到推理之前用于优化模型的方法。
虽然我们可以将几节课用于讨论这个主题,但本节的目标是为您介绍最重要的优化技术。大型语言模型在计算和存储要求方面提出了推理挑战,以及确保消费应用程序具有低延迟。无论是在本地部署还是部署到云上,当部署到边缘设备时,这些挑战都会更加突出。

提高应用程序性能的主要方法之一是减小LLM的大小。这可以允许模型更快地加载,从而减少推理延迟。但是,挑战在于在保持模型性能的同时减小模型的大小。对于生成模型,某些技术比其他技术效果更好,准确性和性能之间存在权衡。在本节中,您将了解三种技术。
蒸馏使用一个较大的模型,即教师模型,来训练一个较小的模型,即学生模型。然后,您可以使用较小的模型进行推理,以降低存储和计算预算。与量化感知训练类似,后期训练量化将模型的权重转换为较低精度的表示,例如16位浮点或8位整数。如您在课程第一周学到的那样,这会减小模型的内存占用。第三种技术,模型修剪,删除了对模型性能贡献不大的冗余模型参数。让我们更详细地讨论这些选项。

模型蒸馏是一种侧重于使用较大的教师模型来训练较小的学生模型的技术。学生模型学会统计上模仿教师模型的行为,可以是在最终预测层或模型的隐藏层中。
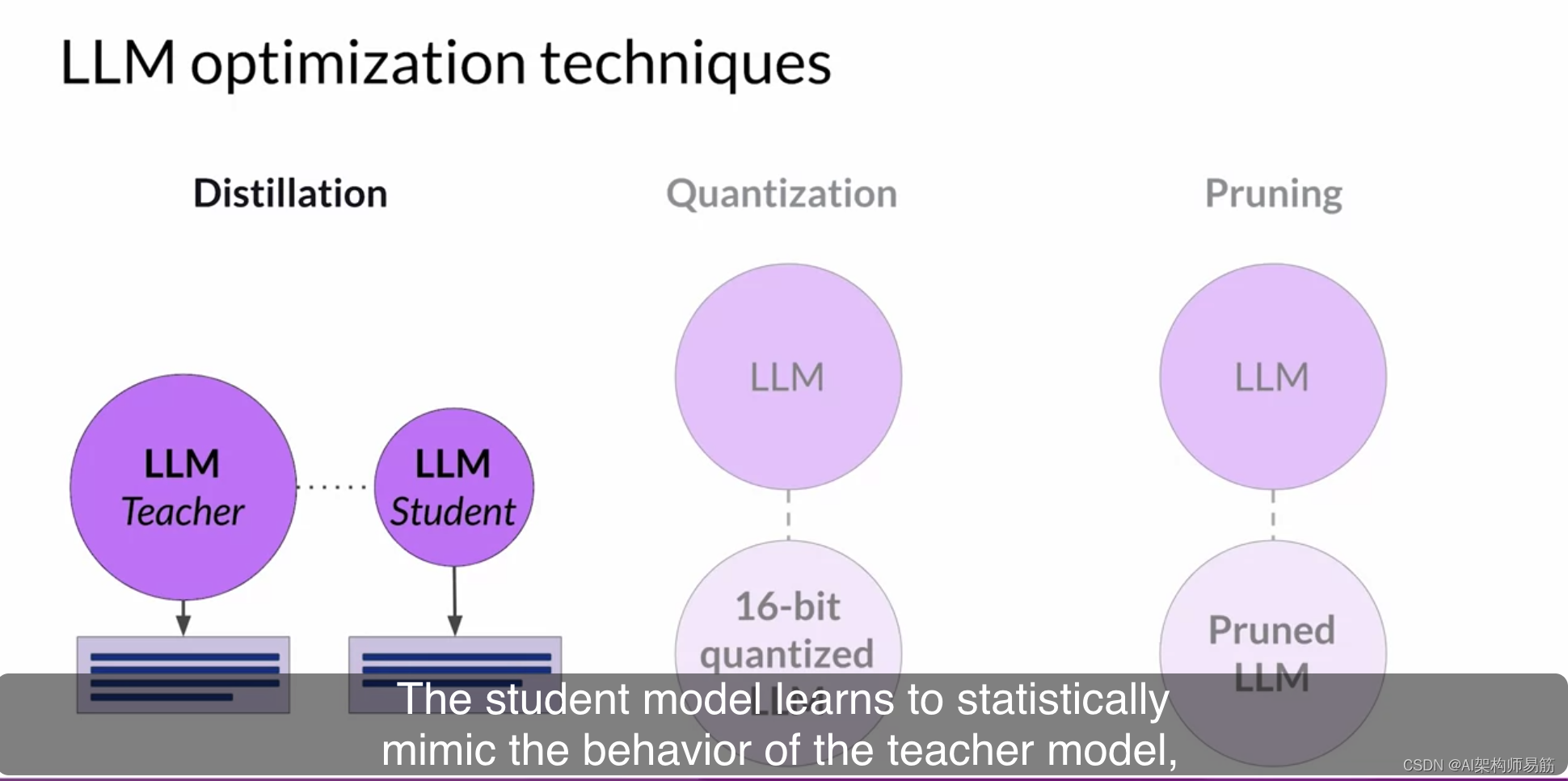
这里我们将重点放在第一种选项上。您可以使用您的微调LLM作为教师模型,为学生模型创建一个较小的LLM。您冻结教师模型的权重,并使用它来为您的训练数据生成完成。同时,您使用学生模型为训练数据生成完成。通过最小化称为蒸馏损失的损失函数来实现教师和学生模型之间的知识蒸馏。为了计算这个损失,蒸馏使用了由教师模型的softmax层产生的标记概率分布。
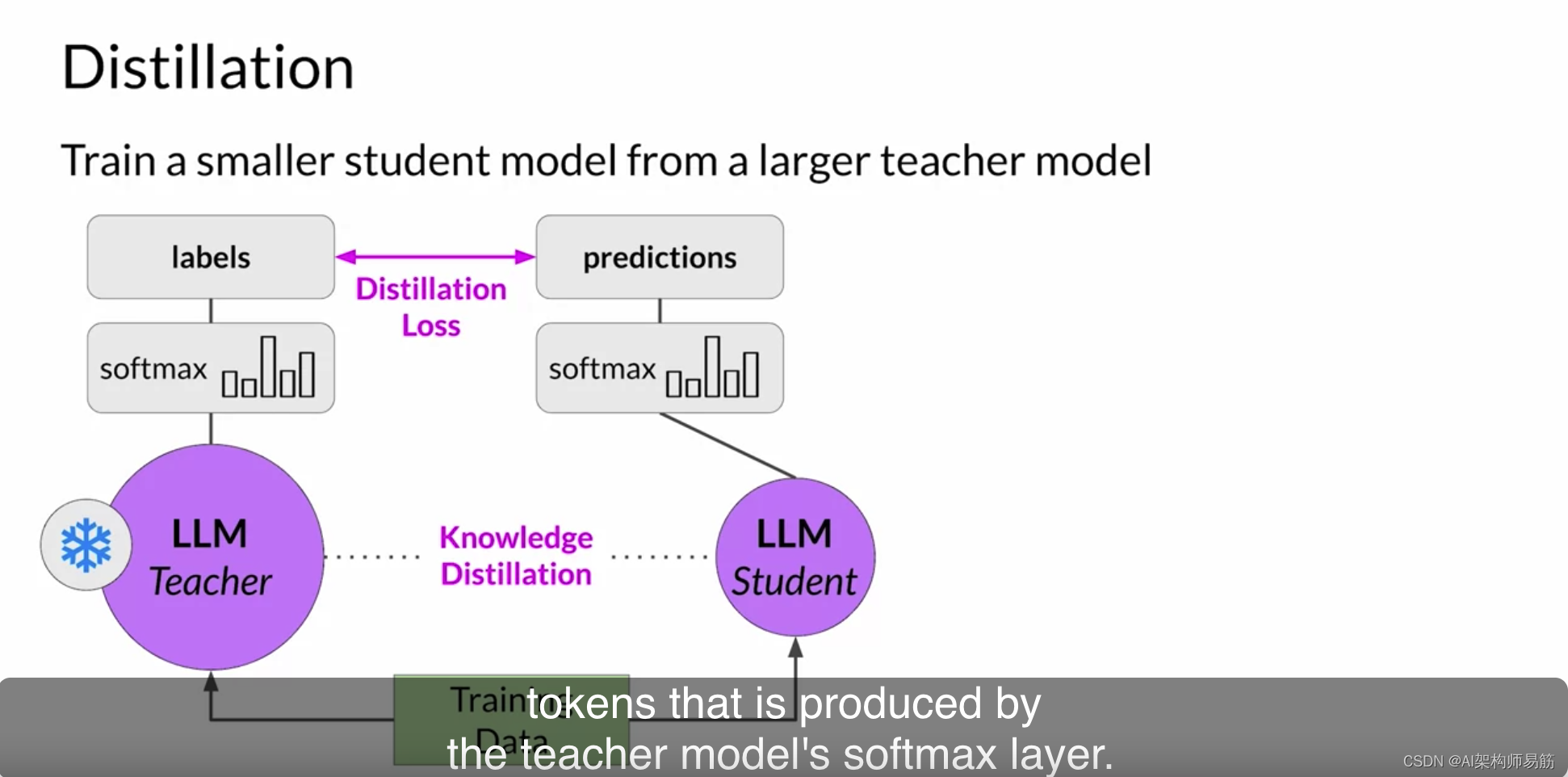
现在,教师模型已经在训练数据上进行了微调。因此,概率分布可能与基本事实数据非常接近,标记中的令牌不会有太大的变化。这就是为什么蒸馏应用了一个小技巧,即在softmax函数中添加温度参数。如您在第一课中学到的,温度越高,模型生成的语言的创造力就越大。
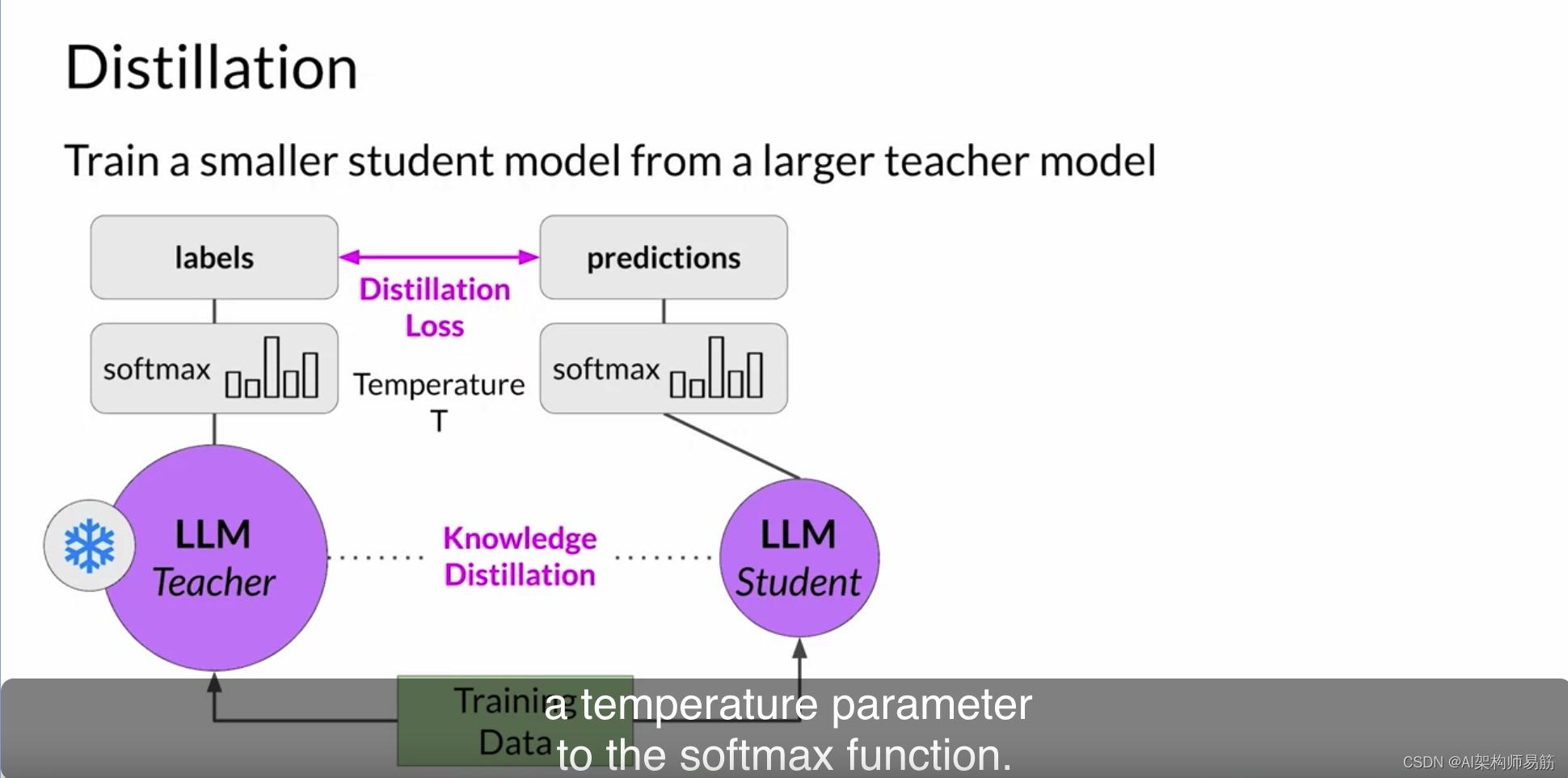
通过一个大于一的温度参数,概率分布变得更广泛,峰值不那么尖锐。
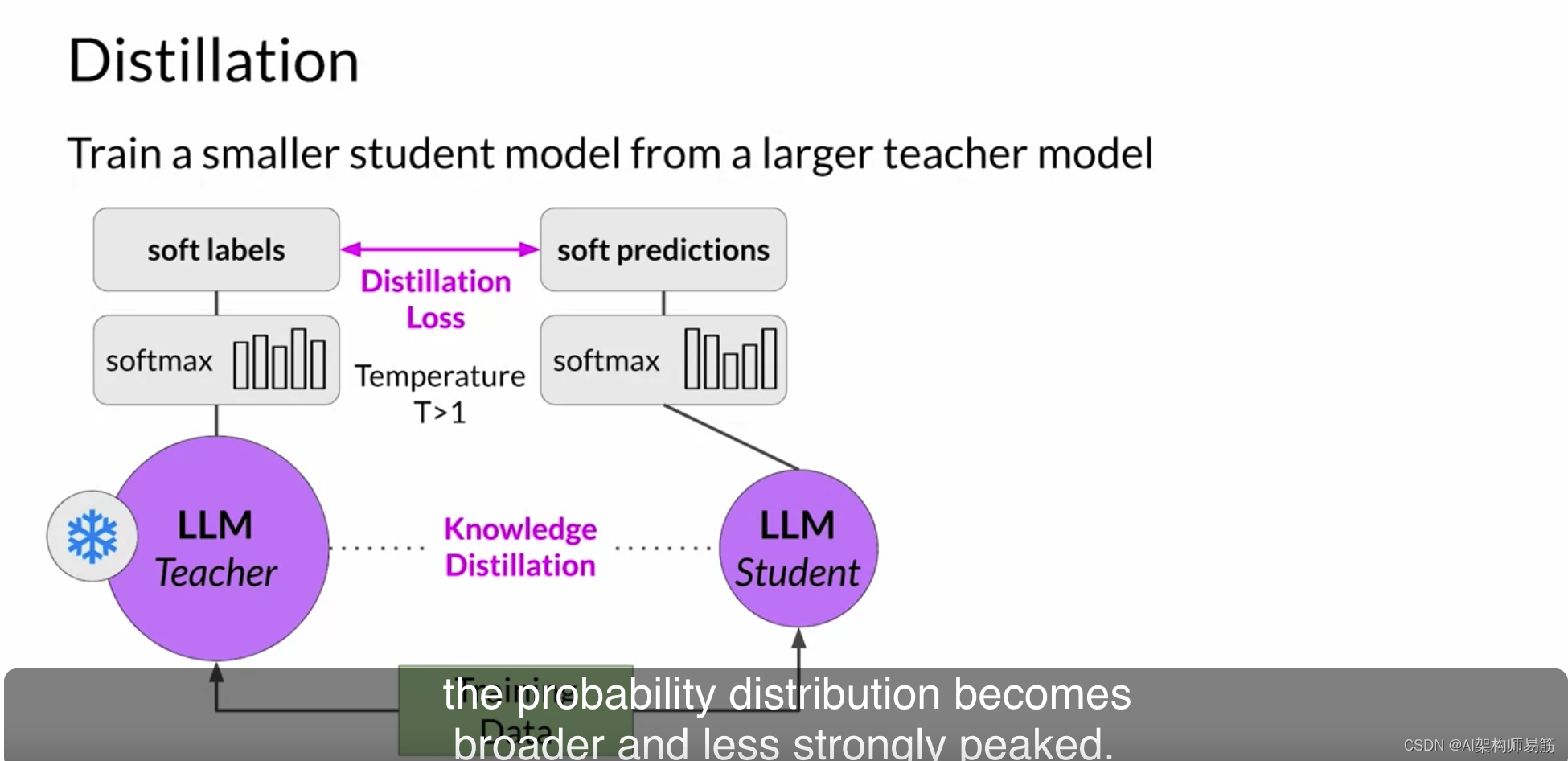
这种较软的分布为您提供了一组与基本事实标记相似的标记。
在蒸馏的上下文中,教师模型的输出通常被称为软标签,
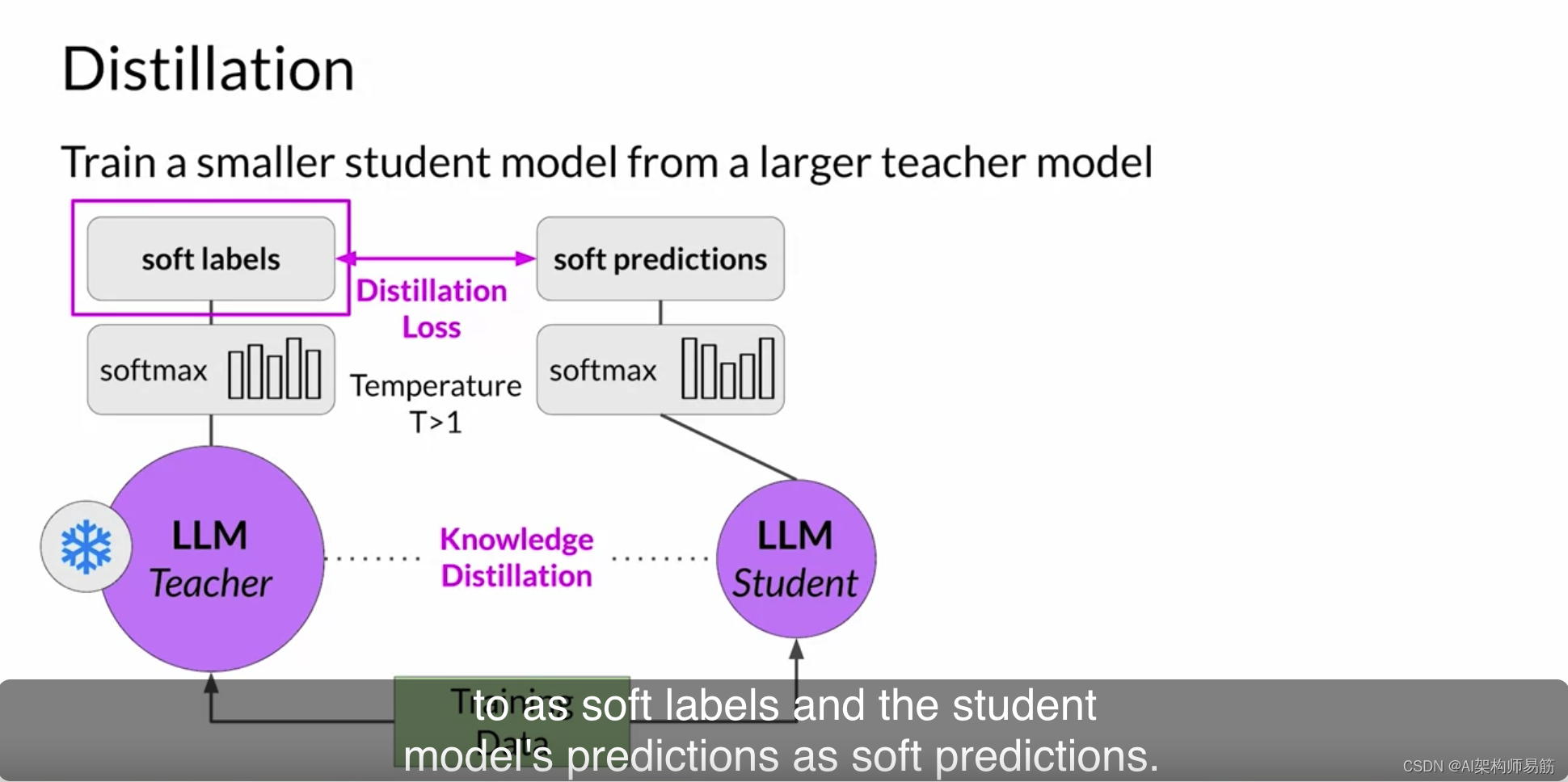
学生模型的预测被称为软预测。
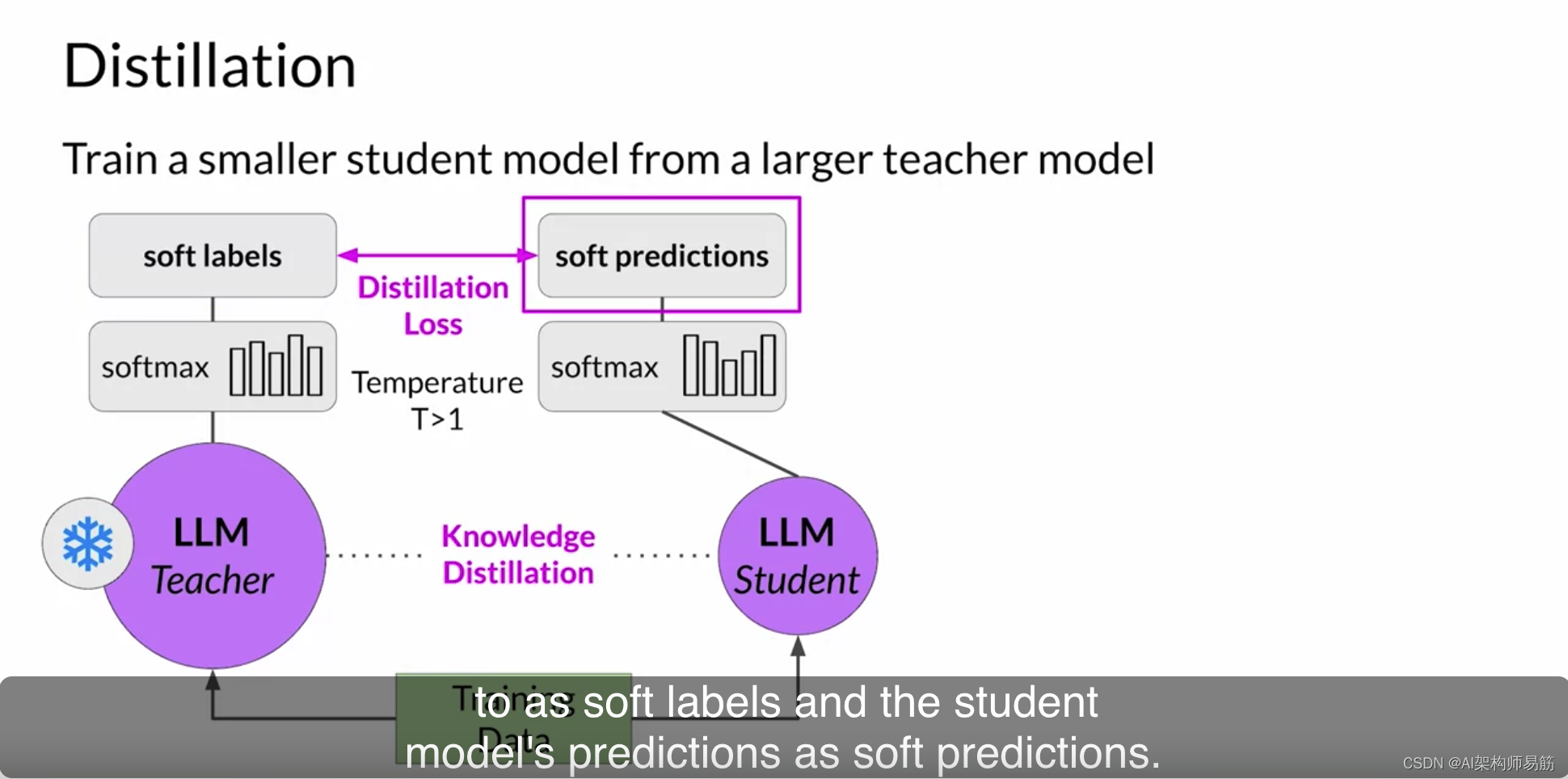
同时,您训练学生模型生成基于您的基本事实训练数据的正确预测。在这里,您不会改变温度设置,而是使用标准的softmax函数。蒸馏将学生和教师模型之间的损失和学生损失结合起来,通过反向传播来更新学生模型的权重。
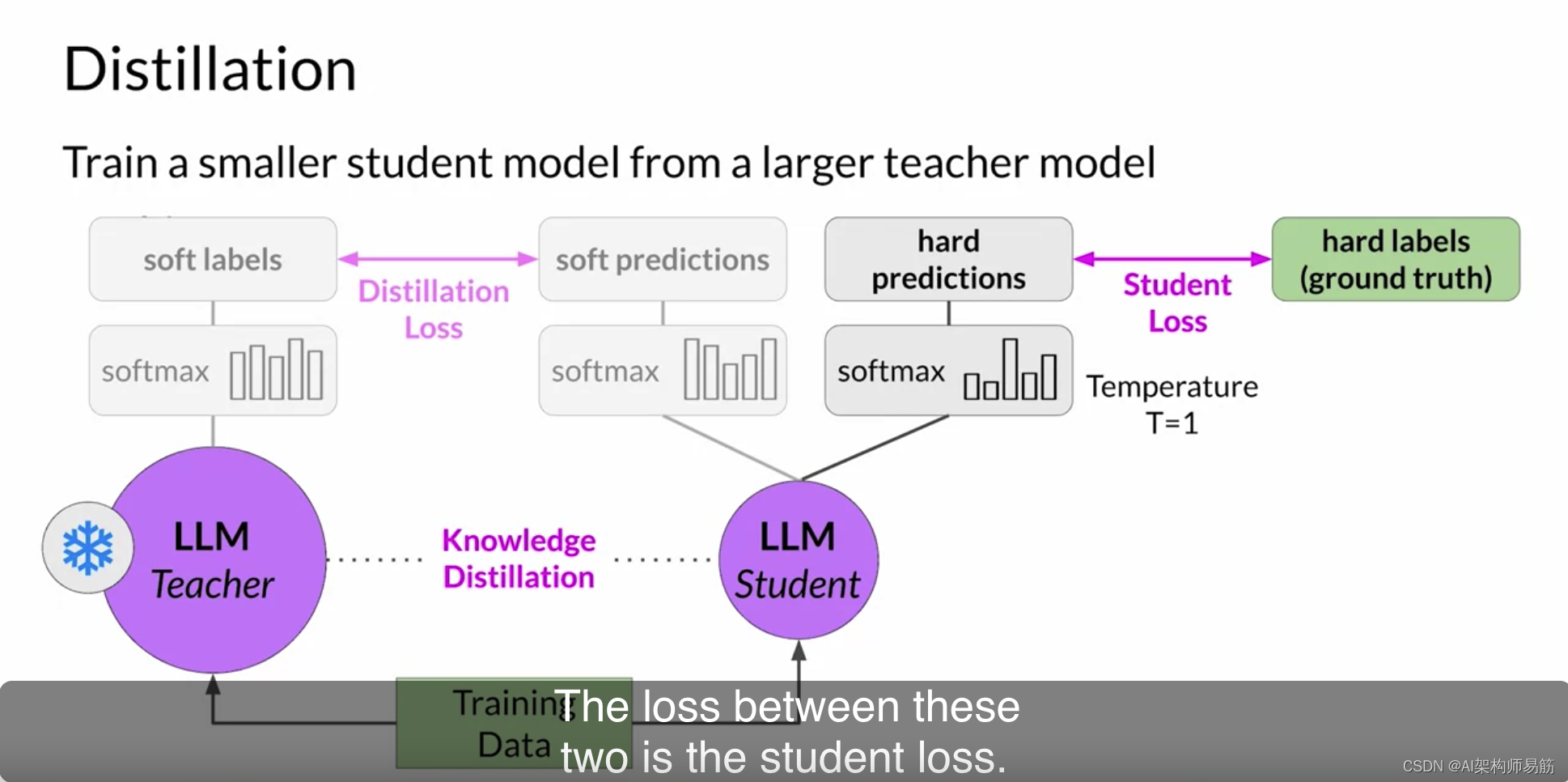
蒸馏方法的关键好处是可以在部署中使用较小的学生模型,而不是教师模型。
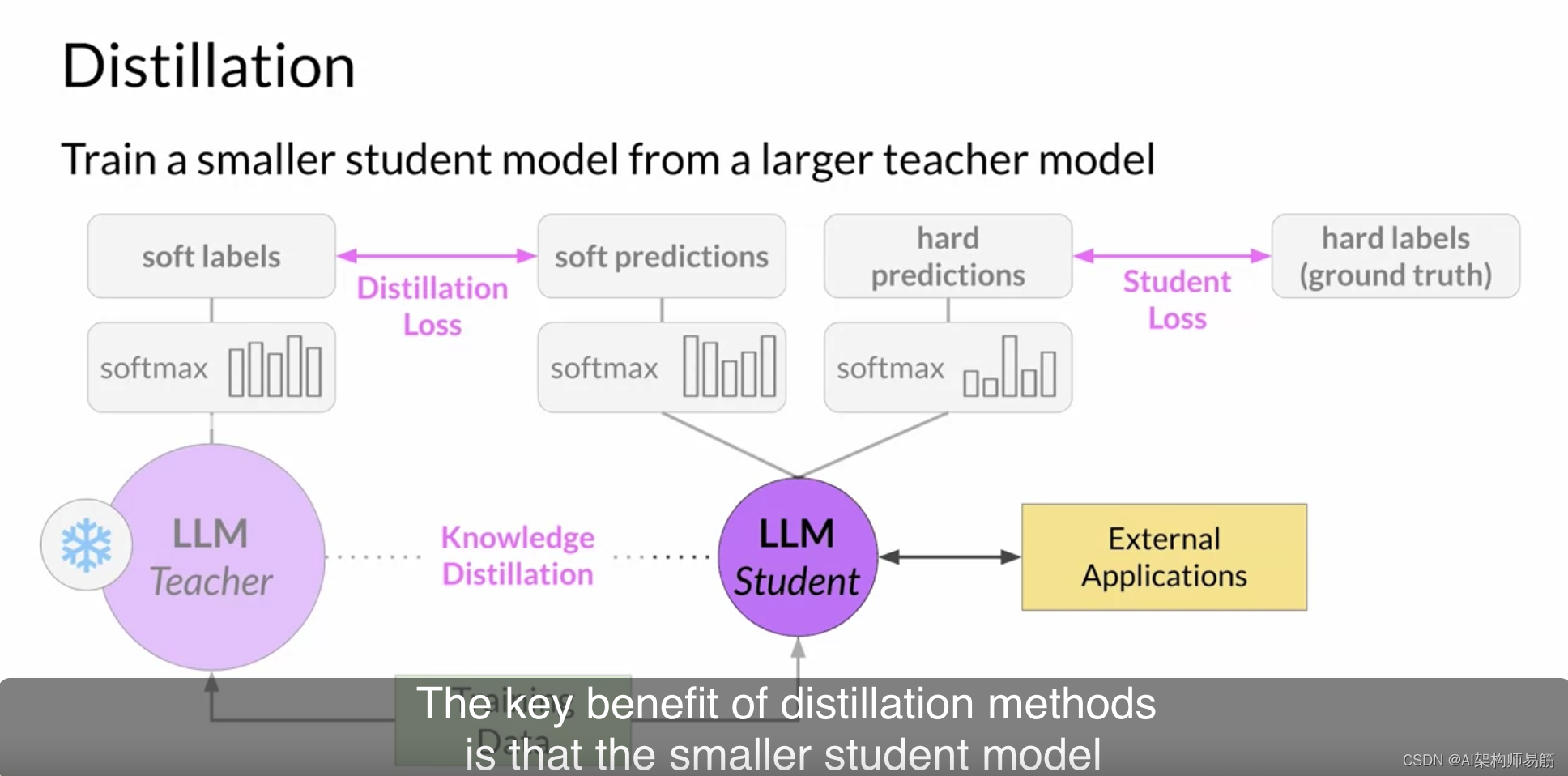
在实践中,蒸馏对生成解码器模型通常不太有效。通常对仅编码器模型,如具有大量表示冗余的Bert模型,更有效。请注意,使用蒸馏,您训练了一个第二个较小的模型,用于推理。您没有以任何方式减小初始LLM的模型大小。
接下来,让我们看看下一个可以实际减小LLM大小的模型优化技术。在第一周,您已经在培训的上下文中介绍了第二种方法,即量化感知训练Specifically Quantization Aware Training,简称QAT。
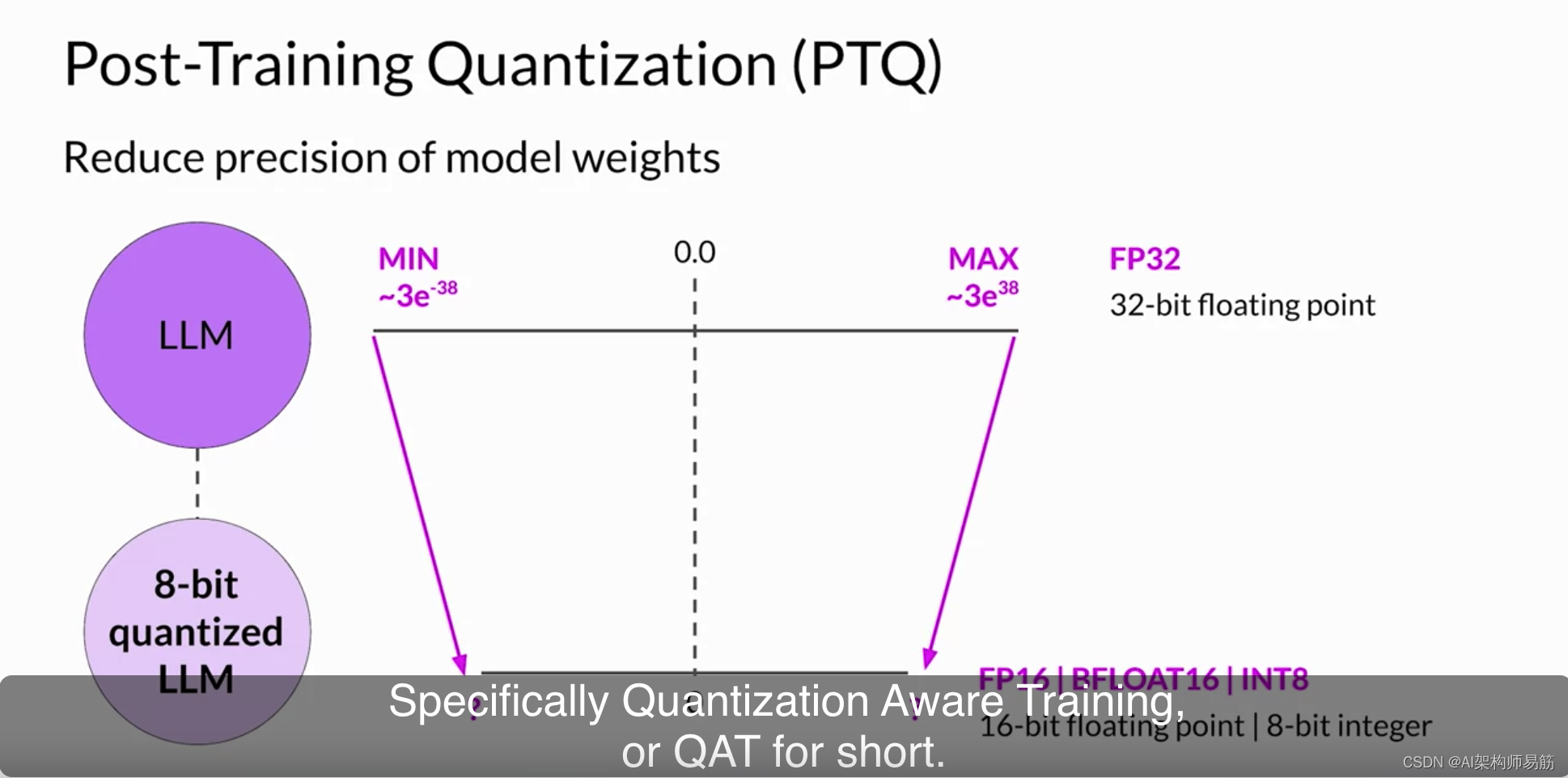
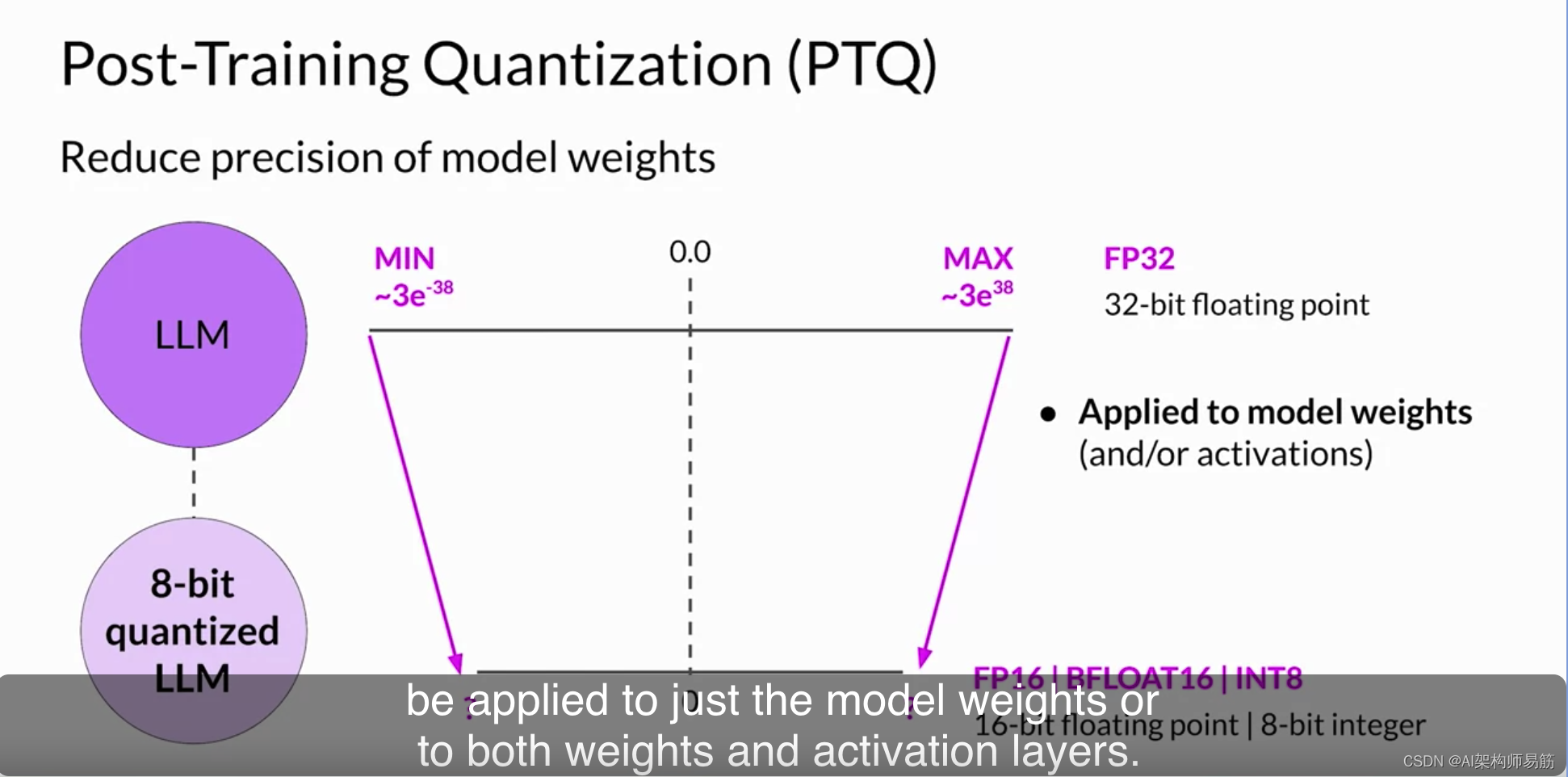
然而,一旦模型训练完毕,您可以执行后期训练量化Post Training quantization,简称PTQ,以优化部署。PTQ将模型的权重转换为较低精度的表示,例如16位浮点或8位整数,以减小模型大小和内存占用,以及模型服务所需的计算资源。一般来说,包括激活的量化方法对模型性能的影响较大。
量化还需要额外的校准步骤,以统计捕获原始参数值的动态范围。
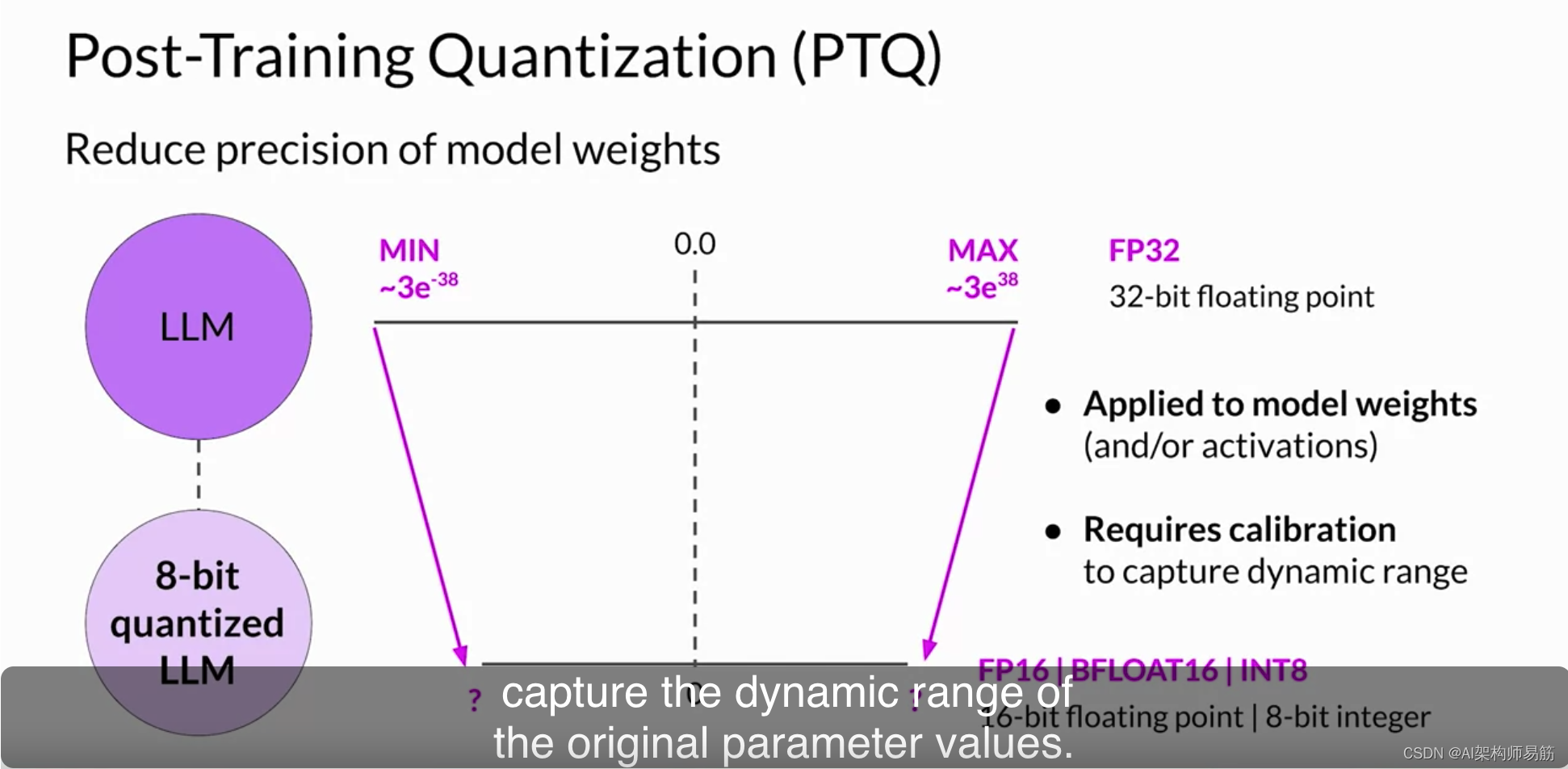
与其他方法一样,存在权衡,因为有时量化会导致模型评估指标略微下降。然而,这种降低通常可以抵消成本节省和性能提高的成本。
最后一个模型优化技术是修剪Pruning。在高层次上,目标是通过消除对总体模型性能贡献不大的权重来减小推理的模型大小。这些权重的值非常接近或等于零。请注意,一些修剪方法需要对模型进行全面重新训练,而其他方法属于参数高效微调的范畴,例如LoRA。还有一些方法专注于后期修剪。在理论上,这可以减小模型的大小并提高性能。然而,在实践中,如果只有一小部分模型权重接近零,那么模型的大小和性能可能没有太大影响。

量化、蒸馏和修剪都旨在减小模型大小,以提高推理时的模型性能,而不影响准确性。优化您的模型以供部署将有助于确保您的应用程序运行良好,并为用户提供最佳体验。
Reference
https://www.coursera.org/learn/generative-ai-with-llms/lecture/qojKp/model-optimizations-for-deployment