索引
- 索引:一种有序的存储结构,按照单个或者多个列的值进行排序。
- 索引的目的:提升搜索效率。
- 索引分类:
- 数据结构
- B+ 树索引(映射的是磁盘数据)
- hash 索引(快速锁定内存数据)
- 全文索引
- 将存储在数据库中的整本书和整篇文章中的任意内容信息查找出来的技术。
- 在短字符串中用 LIKE %;在全文索引中用 match 和 against。
- 一般使用 elasticsearch。
- 物理存储
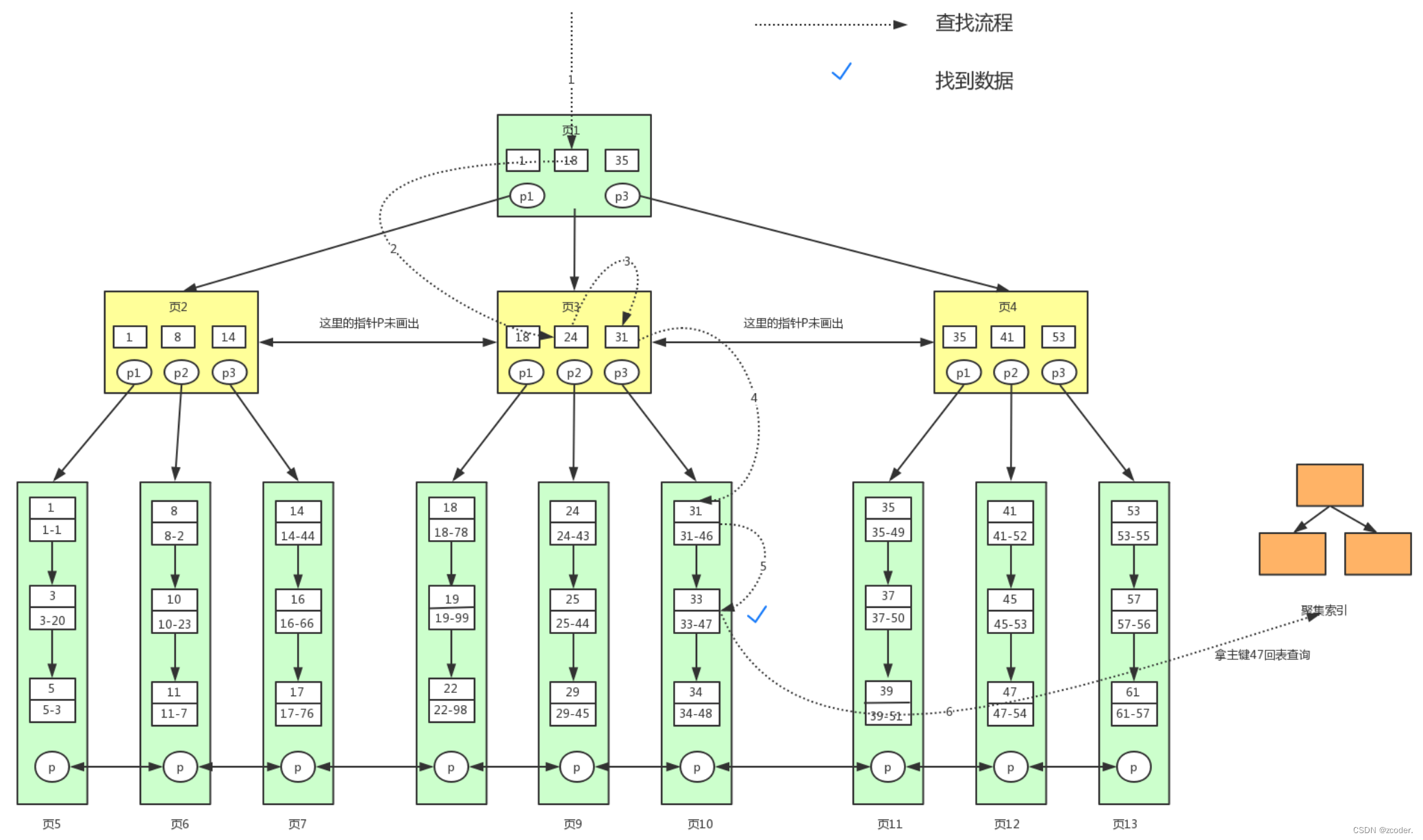
- 聚集索引(聚簇索引):主键所对应的 B+ 树。(包含主键 ID 和表数据)
- 辅助索引(二级索引):除了主键之外的其它索引。(只包含 key 和主键 ID)
- 回表查询:辅助索引 B+ 树通过 key 查找到主键 ID,然后通过主键 ID 查找聚簇索引 B+ 树从而得到表记录。
struct zcoder_tb {int id; string name; string phone; short age;
}; map<int, zcoder_tb>
map<string, int>
map<string, int>
- 列属性
- 列的个数
- 索引代价
- 占用空间(有多个索引,就有多个 B+ 树)。
- 维护的代价:DML 操作变慢(如果修改的字段有索引(非聚簇索引),除了要修改聚簇索引 B+ 树,还要修改对应的辅助索引 B+ 树)。
- 索引的使用场景
- 不使用索引的场景
- 不使用 where / / /group by / / /order by
- 列中的数据区分度不高
- 经常修改的列
- 表数据量少
- innodb 中 B+ 树(多路平衡搜索树)
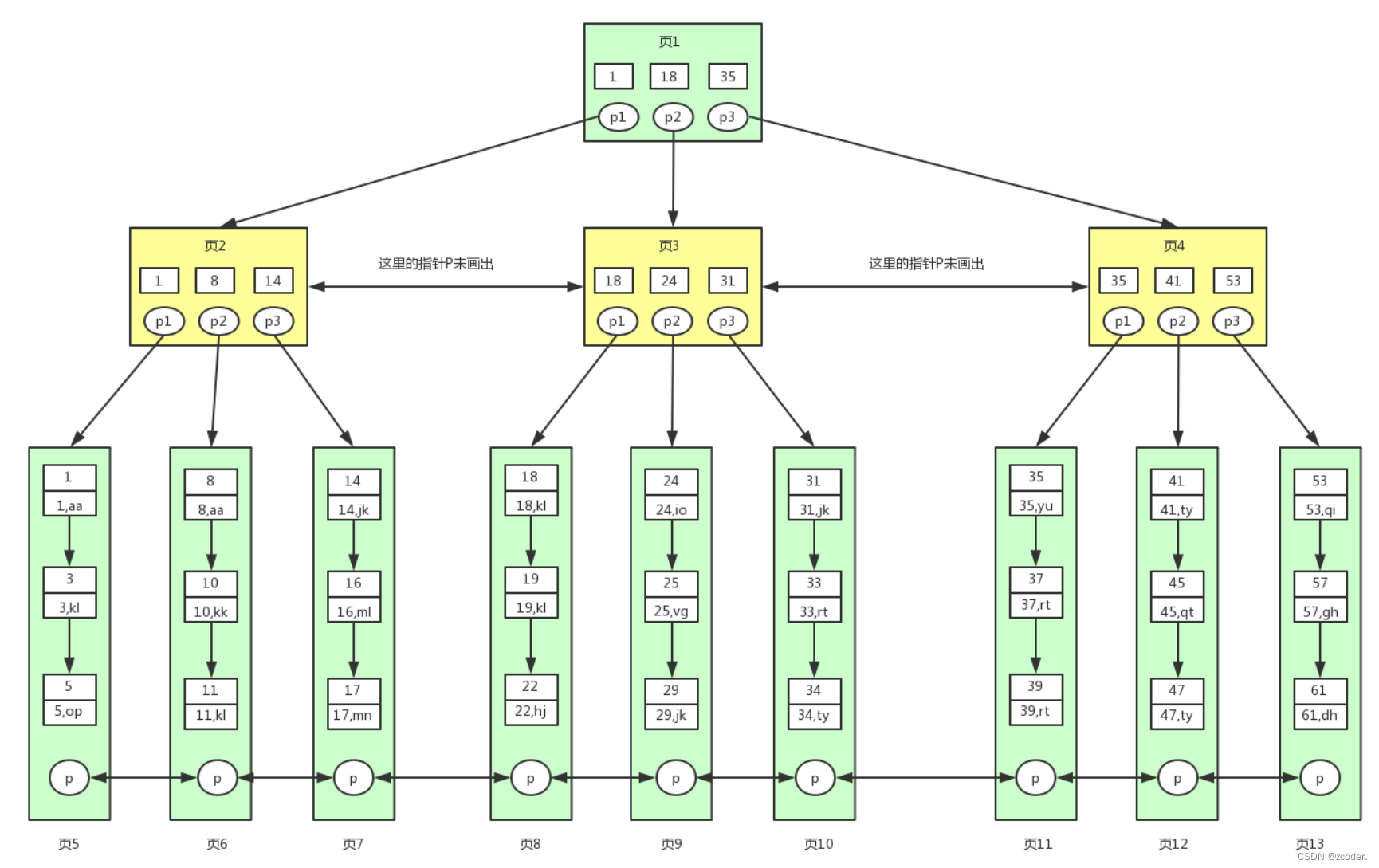
- 特征:
- 非叶子节点只存储索引信息(只存储 key)。
- 叶子节点还存储数据信息(存储 key 和 value)。
- 叶子节点之间依次相连。
- 节点的大小为 16 KB,映射的是连续的磁盘页(通过 mmap 映射磁盘数据)。
- 一个叶子节点至少存储两行数据,如果某一行数据大于 16 KB,则会截取一部分数据进行存储,并保留一个地址位(记录另一个 B+ 树所对应的地址),然后把剩余的数据存储在另一个 B+ 树中。
- 为什么采用 “多路” 的树结构
- 一个节点多条链路,相较于平衡二叉搜索树是一个更加矮胖的结构,树的高度较低,较少的磁盘 IO 次数来索引数据。
- 为什么非叶子节点只存储索引信息
- B+ 树节点映射固定大小的磁盘数据,可以包含更多的索引信息,能快速锁定数据所在叶子节点的位置。
- 为什么叶子节点依次相连
- 索引信息和数据信息的分层管理,便于高效地组织磁盘数据,快速实现单点和范围查询。
- 聚簇索引查找流程
select * from user where id >= 18 and id < 40;
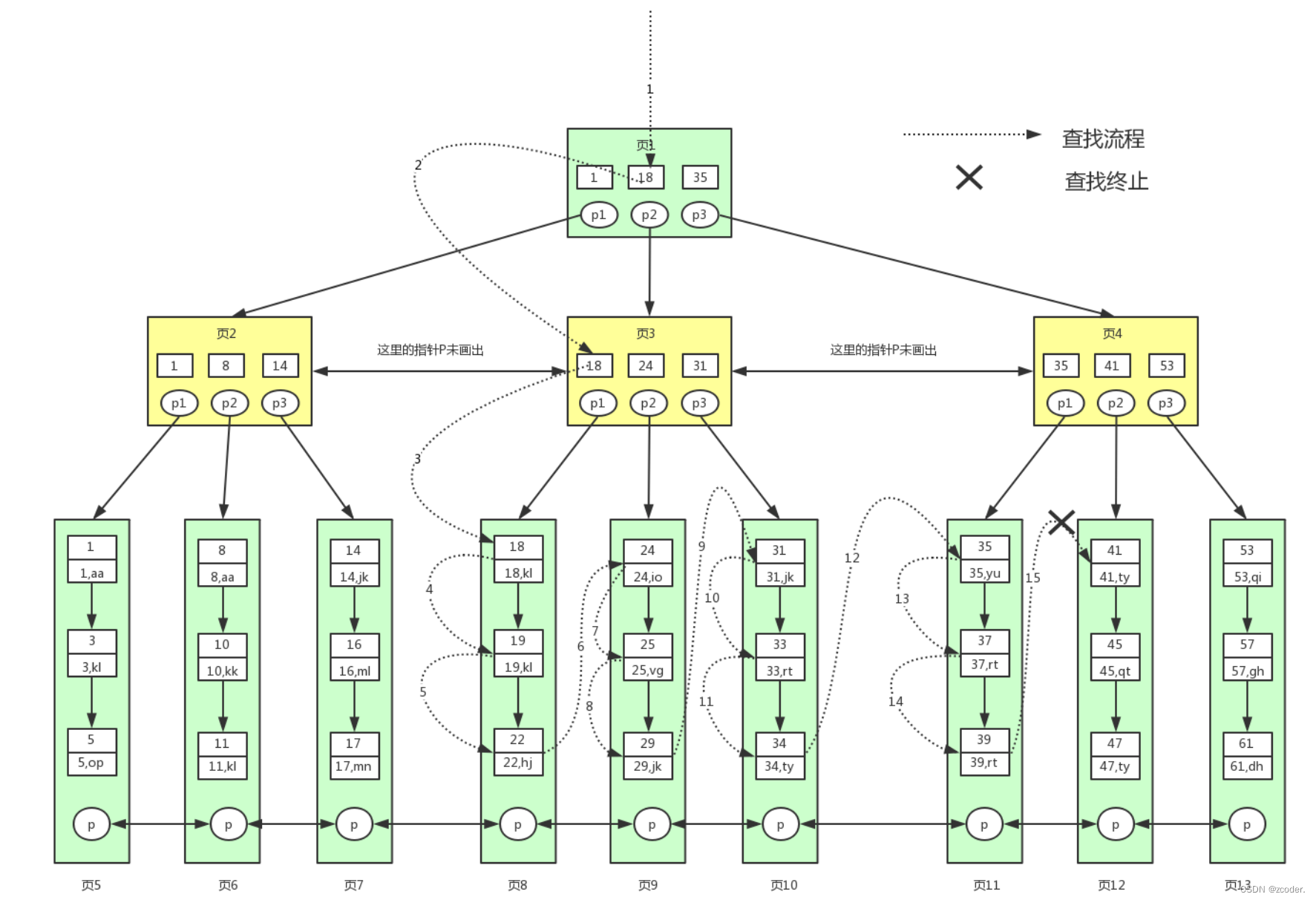
- 辅助索引查找流程
- 辅助索引的叶子节点不包含行记录的全部数据,只存储了用来排序的 key 和一个 bookmark,该书签存储了聚集索引的 key。
select * from user where lockyNum = 33;
- innodb 体系结构

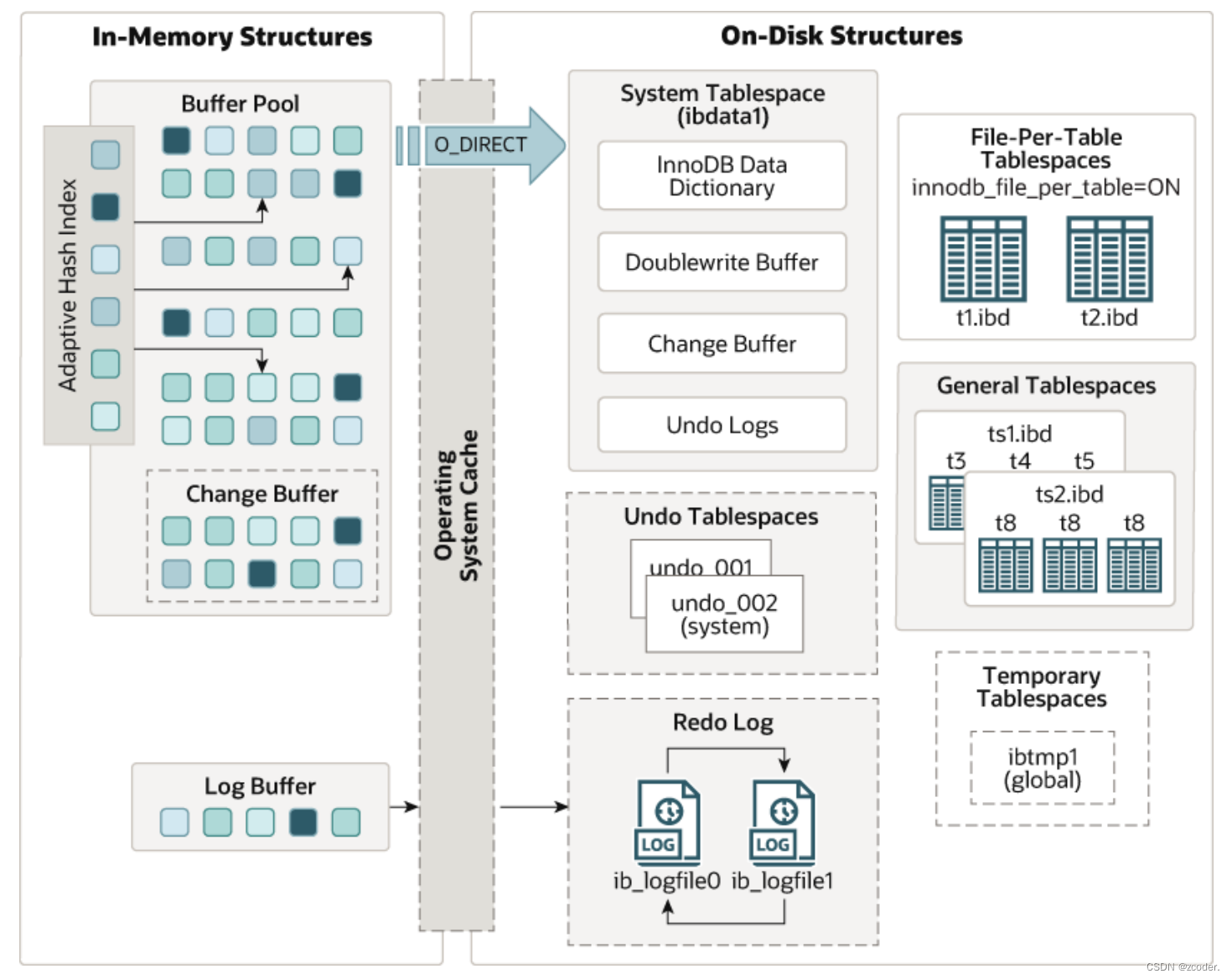
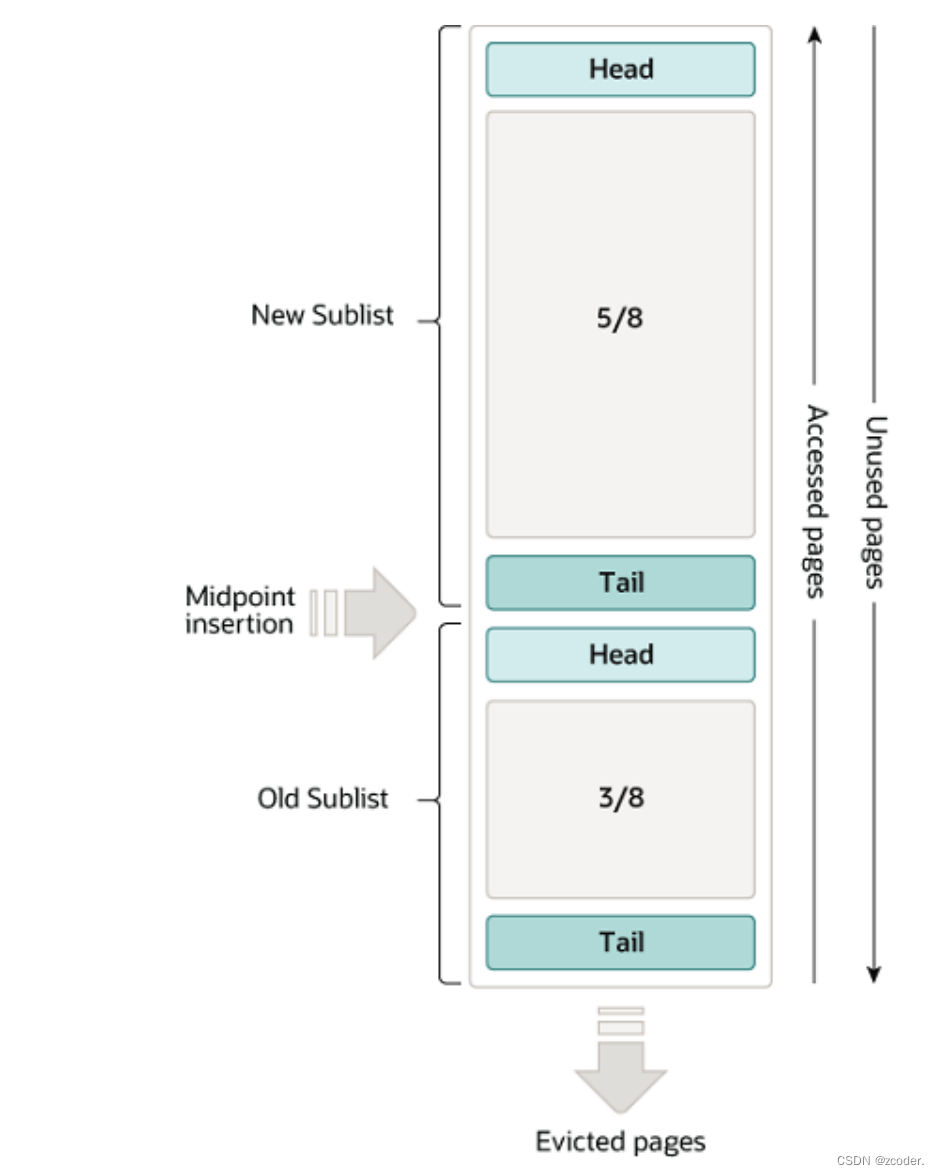
- Buffer Pool
- 缓存表和索引数据( 聚簇索引 B+ 树的数据)。
- 采用 LRU 算法,只缓存比较热的数据。
- 缓存大小为 128 MB。
- 有三个链表组织数据
- free list 组织 Buffer Pool 中未使用的缓存页。
- flush list 组织 Buffer Pool 中的脏页,也就是待刷磁盘的页。
- lru list 组织 Buffer Pool 中的冷热数据,当 Buffer Pool 没有空闲页时,将把 lru list 中最久未使用的数据淘汰。
- Buffer Pool 中的数据修改没有刷到磁盘,怎么确保内存中数据安全(mysql 关闭时,内存数据丢失)?
- Change Buffer
- Change Buffer 缓存辅助索引的数据变更(DML 操作),Change Buffer 中的数据将会异步 merge 到 Buffer Pool 中。
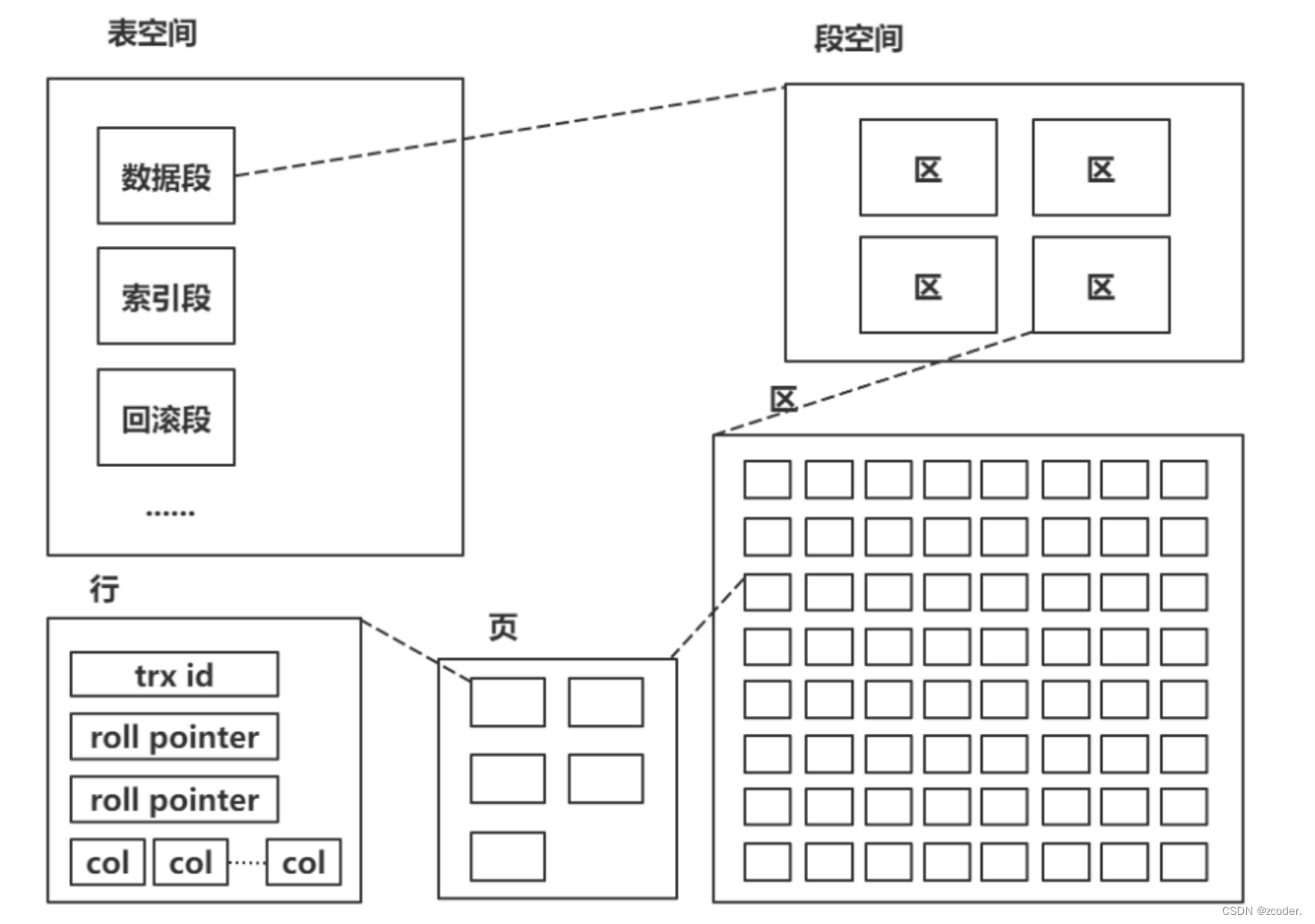
索引存储
- innodb 由段、区、页组成,段分为数据段、索引段、回滚段等。区大小为 1 MB(一个区由 64 个连续页构成),页的默认值为 16 KB,页为逻辑页,磁盘物理页大小一般为 4KB 或者 8KB。
- 为了保证区中的页连续,存储引擎一般一次从磁盘中申请 4~5 个区。
- 顺序内存 IO(数组) > > >> >> 随机内存 IO(红黑树) ≈ \approx ≈ 顺序磁盘 IO > > >> >> 随机磁盘 IO
索引覆盖
- 一种数据查询方式。
- 针对的是辅助索引。
- 直接通过辅助索引 B+ 树就能获取要查询的值,而无需通过回表查询。
- 在 select 中尽量写我们所需要的字段。
最左匹配规则
- 针对组合索引。
- 从左到右依次匹配,遇到 > 、 < 、 b e t w e e n 、 l i k e >、<、between、like >、<、between、like 就停止匹配。
- 尽量扩展索引,而不是单独创建索引。
索引下推
- 目的:减少回表次数,减少 server 层和存储引擎层的交互次数,从而提升查询效率。
- 对象:辅助索引(普通索引和联合索引场景居多)。
- 5.6 版本后支持。
- 没有索引下推机制:server 层向存储引擎层请求数据,在 server 层根据索引条件进行数据过滤。
- 有索引下推:将索引条件判断下推到存储引擎中过滤数据,最终由存储引擎进行数据汇总返回给 server 层。
索引失效
- where
- LIKE 模糊查询,通配符 % 开头。
explain select * from zcoder_tb where name like '%张';
- 索引字段参与运算。
from_unixtime(idx) = '2024-02-21';
idx = unix_timestamp("2024-02-21")
- 索引字段发生隐式转换。
- 将列隐式转换为某个类型,实际等价于在索引列上作用了隐式转换函数。
- 在索引字段上使用 NOT、<> 、!= 。
id <> 0;
idx > 0 or idx < 0;
- 组合索引中,没有使用第一列索引。
索引原则
- 查询频次较高且数据量大的表建立索引,索引选择使用频次较高,过滤效果好的列或者组合。
- 使用短索引,节点包含的信息多,较少磁盘 IO 操作。比如: smallint,tinyint。
- 对于组合索引,考虑最左侧匹配原则和索引覆盖。
- 尽量选择区分度高的列作为索引,该列的值相同的越少越好。
- 尽量扩展索引,在现有索引的基础上,添加复合索引,最多 6 个索引。
- 不要 select *,尽量只列出需要的列字段,方便使用索引覆盖。
- 索引列,列尽量设置为非空。
- 对于很长的动态字符串,考虑使用前缀索引。 注意:前缀索引不能做 order by 和 group by。
有时候需要索引很长的字符串,这会让索引变的大且慢。
通常情况下可以使用某个列开始的部分字符串作为索引,这样大大的节约索引空间,从而提高索引效率。
但这会降低索引的区分度,索引的区分度是指不重复的索引值和数据表记录总数的比值。
索引的区分度越高则查询效率越高,因为区分度更高的索引可以让 MySQL 在查找的时候过滤掉更多的行。
对于 BLOB , TEXT , VARCHAR 类型的列,必要时使用前缀索引。
因为 MySQL 不允许索引这些列的完整长度,使用该方法的诀窍在于要选择足够长的前缀以保证较高的区分度。select count(distinct left(name,3))/count(*) as sel3, count(distinct left(name,4))/count(*) as sel4, count(distinct left(name,5))/count(*) as sel5, count(distinct left(name,6))/count(*) as sel6, from user;
alter table user add key(name(4));
- 可选:开启自适应 hash 索引或者调整 Change Buffer。
select @@innodb_adaptive_hash_index;
set global innodb_adaptive_hash_index=1; select @@innodb_change_buffer_max_size;
set global innodb_change_buffer_max_size=30;
出现了 SQL 比较慢,如何解决?
- 找到 SQL 语句
- show processlist
show processlist:查看连接线程,可以查看此时线上运行的 SQL 语句。
如果要查看完整的 SQL 语句:SHOW FULL PROCESSLIST, 然后优化该语句。
- 开启慢日志查询
SHOW GLOBAL VARIABLES LIKE 'slow_query%';
SHOW GLOBAL VARIABLES LIKE 'long_query%';
SET GLOBAL slow_query_log = ON;
SET GLOBAL long_query_time = 4;
slow_query_log = ON
long_query_time = 4
slow_query_log_file = D:/mysql/mysql57-slow.log
mysqldumpslow -s t -t 10 -g 'select' D:/mysql/mysql57-slow.log
- 分析 SQL 语句
- 索引
- SQL 语句
- in 和 not in 优化成联合查询
- 减少联合查询
- 工作中不要用 age 字段,而是存储他的生日(年月日)
主键选择
- innodb 中表是索引组织表,每张表有且仅有一个主键。
- 如果显式设置 PRIMARY KEY,则该 key 作为该表的主键。
- 如果没有显式设置,则从非空唯一索引中选择:
- 只有一个非空唯一索引,则选择该索引为主键。
- 有多个非空唯一索引,则选择声明的第一个作为主键。
- 没有非空唯一索引,则自动生成一个 6 字节的 _rowid 作为主键。