设计师专业网站seo的中文意思
目录
整理的更全面的API及用法
创建Stream流
中间操作
filter 过滤
map 映射
flatMap 扁平映射
sorted 排序
limit 截断
skip 跳过
distinct 去重
peek 遍历
终端操作
forEach 遍历
forEachOrdered 顺序遍历
min 统计最小值
max 统计最大值
count 统计元素数量
findFirst 查找第一个元素
findAny 找到最后一个元素
noneMatch 检查流中的所有元素是否都不满足给定的条件, 如果所有元素都不满足条件,则返回 true, 如果有任何一个元素满足条件,则返回 false
anyMatch 检查流中的元素是否至少有一个满足给定的条件
allMatch 检查流中的所有元素是否都满足给定的条件
reduce 规约为单个值
summaryStatistics 流中所有的统计信息
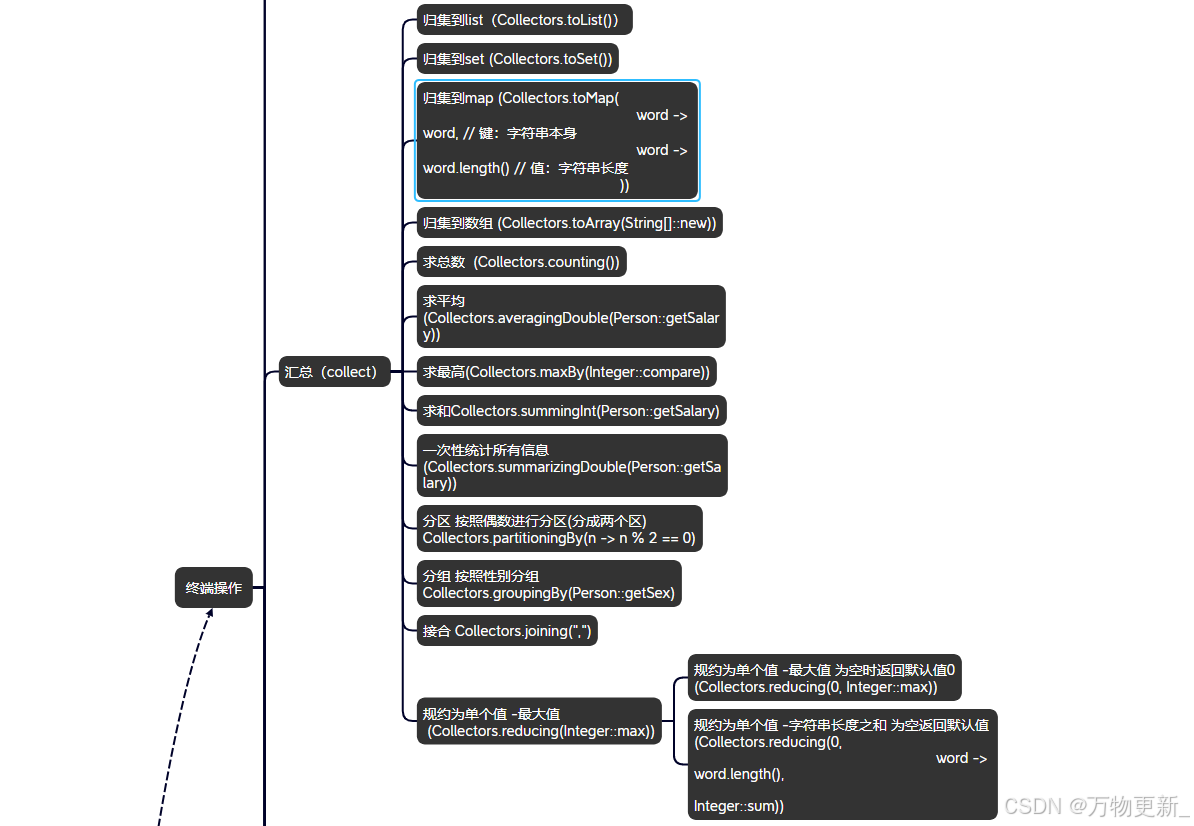
collect 汇总:
归集到set(Collectors.toSet()) 去重确保数据唯一性
归集到map (Collectors.toMap())
归集到数组 (Collectors.toArray())
计算元素的次数 (Collectors.counting())
计算平均值 (Collectors.averagingDouble())
最大值 (Collectors.maxBy())
求和 (Collectors.summingInt())
一次性统计 (Collectors.summarizingDouble())
按条件分成两个区 (Collectors.partitioningBy())
按照条件分组 (Collectors.groupingBy())
接合 (Collectors.joining())
规约 Collectors.reducing()
并行

Stream流的基础知识参考资料
万字详解 Stream 流式编程,写代码也可以很优雅_大模型输出怎么流式输出 stream设为true 没生效-CSDN博客
整理的更全面的API及用法
创建Stream流
1.从集合创建:通过调用集合的 stream() 方法来创建一个 Stream 对象
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
Stream<Integer> stream = numbers.stream();2.从数组创建:java 8 引入了 Arrays 类的 stream() 方法,我们可以使用它来创建一个 Stream 对象
String[] names = {"Alice", "Bob", "Carol"};
Stream<String> stream = Arrays.stream(names); 3.通过 Stream.of() 创建:我们可以使用 Stream.of() 方法直接将一组元素转换为 Stream 对象
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5);4.通过 Stream.builder() 创建:如果我们不确定要添加多少个元素到 Stream 中,可以使用 Stream.builder() 创建一个 Stream.Builder 对象,并使用其 add() 方法来逐个添加元素,最后调用 build() 方法生成 Stream 对象
tream.Builder<String> builder = Stream.builder();
builder.add("Apple");
builder.add("Banana");
builder.add("Cherry");
Stream<String> stream = builder.build();5.从 I/O 资源创建:Java 8 引入了一些新的 I/O 类(如 BufferedReader、Files 等),它们提供了很多方法来读取文件、网络流等数据。这些方法通常返回一个 Stream 对象,可以直接使用
Path path = Paths.get("C:\\Users\\oak\\Desktop\\data.txt");try (Stream<String> stream = Files.lines(path,StandardCharsets.UTF_8)) {stream.forEach(System.out::println);// 使用 stream 处理数据} catch (IOException e) {e.printStackTrace();}try (BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream("C:\\\\Users\\\\oak\\\\Desktop\\\\data.txt"), StandardCharsets.UTF_8))) {Stream<String> lines = br.lines(); // 返回一个Stream<String>lines.forEach(System.out::println); // 处理每一行} catch (IOException e) {e.printStackTrace();}6.通过生成器创建:除了从现有的数据源创建 Stream,我们还可以使用生成器来生成元素。Java 8 中提供了 Stream.generate() 方法和 Stream.iterate() 方法来创建无限 Stream
Stream<Integer> stream = Stream.generate(() -> 0); // 创建一个无限流,每个元素都是 0Stream<Integer> stream = Stream.iterate(0, n -> n + 1); // 创建一个无限流,从 0 开始递增// 生成无限长度的任务流Stream<Instant> tasks = Stream.generate(Instant::now).filter(instant -> instant.getEpochSecond() % 5 == 0);// 模拟每 5 秒一次的任务tasks.limit(5).forEach(task -> {System.out.println("Executing task at: " + task);try {Thread.sleep(Duration.ofSeconds(1).toMillis());} catch (InterruptedException e) {Thread.currentThread().interrupt();}});long startTime = System.currentTimeMillis();Stream<Integer> stream = Stream.iterate(0, n -> n + 1);stream.filter(n -> n % 2 == 0).limit(50000).forEach(System.out::println);long endTime = System.currentTimeMillis();long executionTime = endTime - startTime;//159System.out.println("---------------------1结束--------------------"+executionTime );long startTime1 = System.currentTimeMillis();for (int i = 0; i < 100000; i++) {if(i % 2 == 0){System.out.println(i);}}long endTime1 = System.currentTimeMillis();long executionTime1 = startTime1 - endTime1;//92System.out.println("---------------------2结束--------------------"+executionTime1 );long startTime2 = System.currentTimeMillis();Stream<Integer> stream2 = Stream.iterate(0, n -> n + 1);stream2.filter(n -> n % 2 == 0).limit(50000).parallel().forEach(System.out::println);long endTime2 = System.currentTimeMillis();long executionTime2 = endTime2 - startTime2;//72 (无序)System.out.println("---------------------3结束--------------------"+executionTime2 );9.创建原始数据流, 适用于需要高效处理大量数值的情况:
IntStream intStream = IntStream.range(0, 10);
LongStream longStream = LongStream.rangeClosed(1, 5);
DoubleStream doubleStream = DoubleStream.iterate(0.0, d -> d + 0.5).limit(10);中间操作
filter 过滤
List<String> strings = Arrays.asList("apple", "banana", "cherry", "date", "elderberry", "fig");// 过滤长度大于 5 的字符串
List<String> filteredStrings = strings.stream().filter(s -> s.length() > 5).collect(Collectors.toList());map 映射
List<String> names = Arrays.asList("alice", "bob", "charlie");// 使用 map 方法将每个字符串转换为大写
List<String> uppercaseNames = names.stream().map(String::toUpperCase).collect(Collectors.toList()); flatMap 扁平映射
// 创建一个嵌套列表
List<List<Integer>> nestedList = Arrays.asList(Arrays.asList(1, 2),Arrays.asList(3, 4),Arrays.asList(5, 6)
);// 使用 flatMap 方法将嵌套列表扁平化
List<Integer> flatList = nestedList.stream().flatMap(subList -> subList.stream()).collect(Collectors.toList());sorted 排序
//正序
List<Person> sortedPeople = people.stream().sorted(Comparator.comparing(Person::getAge)).collect(Collectors.toList());//倒序
List<Person> sortedPeople = people.stream().sorted(Comparator.comparing(Person::getAge).reversed()).collect(Collectors.toList());limit 截断
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);// 使用 limit 方法获取前三个元素
List<Integer> limitedNumbers = numbers.stream().limit(3).collect(Collectors.toList());skip 跳过
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);// 使用 skip 方法跳过前两个元素
List<Integer> skippedNumbers = numbers.stream().skip(2).collect(Collectors.toList());distinct 去重
List<Integer> numbers = Arrays.asList(1, 2, 2, 3, 4, 4, 5, 6, 6, 7, 8, 8, 9, 10, 10);// 使用 distinct 方法去除重复的元素
List<Integer> distinctNumbers = numbers.stream().distinct().collect(Collectors.toList());peek 遍历
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);// 使用 peek 方法打印每个元素
List<Integer> processedNumbers = numbers.stream().peek(System.out::println).collect(Collectors.toList());终端操作
forEach 遍历
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);// 使用 forEach 方法打印每个元素
numbers.stream().forEach(System.out::println);forEachOrdered 顺序遍历
List<Integer> numbers = Arrays.asList(10,1, 2, 3, 4, 5, 6, 7, 8, 9 );// 使用 forEachOrdered 方法打印每个元素
numbers.stream().forEachOrdered(System.out::println);min 统计最小值
List<String> words = Arrays.asList("apple", "banana", "cherry", "date", "elderberry", "fig");// 使用 min 方法找到最短的字符串
Optional<String> shortestWord = words.stream().min(Comparator.comparingInt(String::length));// 输出结果
shortestWord.ifPresent(System.out::println); // 如果存在则打印max 统计最大值
List<Integer> numbers = Arrays.asList(10, 20, 30, 40, 50, 60, 70, 80, 90, 100);// 使用 max 方法找到最大值
Optional<Integer> maxValue = numbers.stream().max(Integer::compare);// 输出结果
maxValue.ifPresent(System.out::println); // 如果存在则打印count 统计元素数量
List<Integer> numbers = Arrays.asList(10, 20, 30, 40, 50, 60, 70, 80, 90, 100);// 使用 count 方法计算元素数量
long count = numbers.stream().count();// 输出结果
System.out.println(count);//10findFirst 查找第一个元素
List<Integer> numbers = Arrays.asList(20, 100, 30, 40, 50, 60, 70, 80, 90, 100);// 使用 findFirst 方法查找第一个元素
Optional<Integer> firstNumber = numbers.stream().findFirst();// 输出结果
firstNumber.ifPresent(System.out::println); // 如果存在则打印 //20findAny 找到最后一个元素
List<String> words = Arrays.asList("apple", "banana", "elderberry", "cherry", "date", "fig");// 使用 findAny 方法随机选择长度大于等于 5 的一个字符串
Optional<String> anyLongWord = words.stream().parallel().filter(s -> s.length() >= 5).findAny();// 输出结果
anyLongWord.ifPresent(System.out::println); // 如果存在则打印 //cherry noneMatch 检查流中的所有元素是否都不满足给定的条件, 如果所有元素都不满足条件,则返回 true, 如果有任何一个元素满足条件,则返回 false
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);// 使用 noneMatch 方法检查是否有元素小于 0
boolean result = numbers.stream().noneMatch(n -> n < 0);// 输出结果
System.out.println(result); // 应该输出 trueanyMatch 检查流中的元素是否至少有一个满足给定的条件
List<Integer> numbers = Arrays.asList(1, -2, 3, 4, 5);// 使用 anyMatch 方法检查是否有元素小于 0
boolean result = numbers.stream().anyMatch(n -> n < 0);// 输出结果
System.out.println(result); // 应该输出 trueallMatch 检查流中的所有元素是否都满足给定的条件
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);// 使用 allMatch 方法检查所有元素是否都大于 0
boolean result = numbers.stream().allMatch(n -> n > 0);// 输出结果
System.out.println(result); // 应该输出 truereduce 规约为单个值
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);// 使用 reduce 方法求和
Integer sum = numbers.stream().reduce(0, Integer::sum);// 输出结果
System.out.println(sum); // 应该输出 15// 使用 reduce 方法查找最大值
Integer max = numbers.stream().reduce(Integer.MIN_VALUE, Integer::max);// 使用 reduce 方法查找最小值
Integer min = numbers.stream().reduce(Integer.MAX_VALUE, Integer::min);// 输出结果
System.out.println(max); // 应该输出 5
System.out.println(min); // 应该输出 1// 使用 reduce 方法计算乘积
Integer product = numbers.stream().reduce(1, (a, b) -> a * b);// 输出结果
System.out.println(product); // 应该输出 120List<String> words = Arrays.asList("Hello", "World", "Java", "Stream");// 使用 reduce 方法拼接字符串
String concatenatedString = words.stream().reduce("", (a, b) -> a + b);// 输出结果
System.out.println(concatenatedString); // 应该输出 HelloWorldJavaStreamsummaryStatistics 流中所有的统计信息
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);// 获取整数流的统计信息
ntSummaryStatistics stats = numbers.stream().mapToInt(Integer::intValue).summaryStatistics();// 输出结果
System.out.println("Count: " + stats.getCount()); // 应该输出 10
System.out.println("Min: " + stats.getMin()); // 应该输出 1
System.out.println("Max: " + stats.getMax()); // 应该输出 10
System.out.println("Average: " + stats.getAverage()); // 应该输出 5.5
System.out.println("Sum: " + stats.getSum()); // 应该输出 55List<Long> numbers = Arrays.asList(1L, 2L, 3L, 4L, 5L, 6L, 7L, 8L, 9L, 10L);// 获取长整型流的统计信息
LongSummaryStatistics stats = numbers.stream().mapToLong(Long::longValue).summaryStatistics();// 输出结果
System.out.println("Count: " + stats.getCount()); // 应该输出 10
System.out.println("Min: " + stats.getMin()); // 应该输出 1
System.out.println("Max: " + stats.getMax()); // 应该输出 10
System.out.println("Average: " + stats.getAverage()); // 应该输出 5.5
System.out.println("Sum: " + stats.getSum()); // 应该输出 55List<Double> numbers = Arrays.asList(1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0);// 获取浮点数流的统计信息
DoubleSummaryStatistics stats = numbers.stream().mapToDouble(Double::doubleValue).summaryStatistics();// 输出结果
System.out.println("Count: " + stats.getCount()); // 应该输出 10
System.out.println("Min: " + stats.getMin()); // 应该输出 1.0
System.out.println("Max: " + stats.getMax()); // 应该输出 10.0
System.out.println("Average: " + stats.getAverage()); // 应该输出 5.5
System.out.println("Sum: " + stats.getSum()); // 应该输出 55.0collect 汇总:
归集到list(Collectors.toList())
String[] wordsArray = {"Hello", "World", "Java", "Stream"};// 使用 toList 方法将数组转换为列表
List<String> wordsList = Arrays.stream(wordsArray).collect(Collectors.toList());// 输出结果
System.out.println(wordsList); // 应该输出 [Hello, World, Java, Stream]归集到set(Collectors.toSet()) 去重确保数据唯一性
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 3, 2);// 使用 toSet 方法将列表转换为 Set
Set<Integer> numberSet = numbers.stream().collect(Collectors.toSet());// 输出结果
System.out.println(numberSet); // 应该输出 [1, 2, 3, 4, 5](顺序可能不同)归集到map (Collectors.toMap())
List<String> words = Arrays.asList("apple", "banana", "cherry", "date");// 使用 toMap 方法将每个字符串作为键,其索引作为值
Map<String, Integer> wordIndexMap = words.stream().collect(Collectors.toMap(word -> word, // key mapperword -> words.indexOf(word) // value mapper));// 输出结果
System.out.println(wordIndexMap); // 应该输出 {apple=0, banana=1, cherry=2, date=3}归集到数组 (Collectors.toArray())
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);// 使用 toArray 方法将列表转换为数组
Integer[] numberArray = numbers.stream().toArray(Integer[]::new);// 输出结果
System.out.println(Arrays.toString(numberArray)); // 应该输出 [1, 2, 3, 4, 5]计算元素的次数 (Collectors.counting())
List<String> words = Arrays.asList("apple", "banana", "cherry", "date");// 使用 counting 方法计算字符 'a' 出现的次数
long count = words.stream().flatMapToInt(String::chars).filter(c -> c == 'a').collect(Collectors.counting());// 输出结果
System.out.println(count); // 应该输出 4 ("apple" 中有 1 个 'a',"banana" 中有 3 个 'a')计算平均值 (Collectors.averagingDouble())
List<Double> numbers = Arrays.asList(1.0, 2.0, 3.0, 4.0, 5.0);// 使用 averagingDouble 方法计算平均值
double average = numbers.stream().mapToDouble(Double::doubleValue) // 将 Double 转换为 double 值.average() // 计算平均值.orElse(Double.NaN); // 如果流为空,则返回 NaN// 输出结果
System.out.println(average); // 应该输出 3.0最大值 (Collectors.maxBy())
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);// 使用 maxBy 方法找出最大值
Optional<Integer> maxNumber = numbers.stream().collect(Collectors.maxBy(Integer::compare));// 输出结果
maxNumber.ifPresent(System.out::println); // 应该输出 5求和 (Collectors.summingInt())
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);// 使用 summingInt 方法计算总和
int totalSum = numbers.stream().collect(Collectors.summingInt(Integer::intValue));// 输出结果
System.out.println(totalSum); // 应该输出 15一次性统计 (Collectors.summarizingDouble())
List<Double> numbers = Arrays.asList(1.0, 2.0, 3.0, 4.0, 5.0);// 使用 summarizingDouble 方法生成统计摘要
DoubleSummaryStatistics stats = numbers.stream().collect(Collectors.summarizingDouble(Double::doubleValue));// 输出统计信息
System.out.println("Count: " + stats.getCount()); // 应该输出 5
System.out.println("Sum: " + stats.getSum()); // 应该输出 15.0
System.out.println("Min: " + stats.getMin()); // 应该输出 1.0
System.out.println("Max: " + stats.getMax()); // 应该输出 5.0
System.out.println("Average: " + stats.getAverage()); // 应该输出 3.0按条件分成两个区 (Collectors.partitioningBy())
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6);// 使用 partitioningBy 方法按奇偶性划分整数列表
Map<Boolean, List<Integer>> partitionedNumbers = numbers.stream().collect(Collectors.partitioningBy(n -> n % 2 == 0));// 输出结果
System.out.println("Even numbers: " + partitionedNumbers.get(true)); // 应该输出 [2, 4, 6]
System.out.println("Odd numbers: " + partitionedNumbers.get(false)); // 应该输出 [1, 3, 5]按照条件分组 (Collectors.groupingBy())
List<String> words = Arrays.asList("apple", "banana", "cherry", "date", "fig", "grape");// 使用 groupingBy 方法按字符串长度分组
Map<Integer, List<String>> groupedByLength = words.stream().collect(Collectors.groupingBy(String::length));// 输出结果
System.out.println(groupedByLength);
// 应该输出:
// {5=[apple, grape], 6=[banana, cherry], 4=[date, fig]}List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);// 使用 groupingBy 方法按数字的范围分组
Map<String, List<Integer>> groupedByRange = numbers.stream().collect(Collectors.groupingBy(n -> {if (n <= 5) return "1-5";else return "6-10";}));// 输出结果
System.out.println(groupedByRange);
// 应该输出:
// {1-5=[1, 2, 3, 4, 5], 6-10=[6, 7, 8, 9, 10]}接合 (Collectors.joining())
List<String> words = Arrays.asList("apple", "banana", "cherry", "date");// 使用 joining 方法连接字符串列表,以逗号作为分隔符,并添加方括号作为前缀和后缀
String joinedString = words.stream().collect(Collectors.joining(", ", "[", "]"));// 输出结果
System.out.println(joinedString); // 应该输出 "[apple, banana, cherry, date]"规约 Collectors.reducing()
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);// 使用 reducing 方法计算乘积
Optional<Integer> product = numbers.stream().collect(Collectors.reducing(1, (a, b) -> a * b));// 输出结果
System.out.println(product.orElse(null)); // 应该输出 120并行
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);// 创建并行流
numbers.parallelStream().forEach(System.out::println);List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);// 创建顺序流并转换为并行流
numbers.stream().parallel().forEach(System.out::println);// 使用并行流构造器创建 IntStream
IntStream.rangeParallel(0, 10).forEach(System.out::println);