德州 网站建设济南百度竞价开户
正则表示式是用来匹配与查找字符串的,从网上爬取数据不可避免的会用到正则表达式。 Python 的表达式要先引入 re 模块,正则表达式以 r 引导。
Re库主要功能函数
函数 | 说明 |
re.search() | 在一个字符串中搜索匹配正则表达式的第一个位置,返回match对象 |
re.match() | 从一个字符串的开始位置匹配正则表达式,返回match对象 |
re.findall() | 搜索字符串,以列表类型返回全部能匹配的子串 |
re.split() | 将一个字符串按照正则表达式匹配结果进行分割,返回列表类型 |
re.finditer() | 搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素是math对象 |
re.sub() | 在一个字符串中替换所有匹配正则表示式的子串,返回替换后的字符串 |
1. 字符"\d"匹配0-9之间的一个数值
importre
reg=r"\d"
a=re.search(reg, "abc123cd")
print(a) # <re.Match object; span=(3, 4), match='1'>
b1=re.match(reg, "abc123cd")
print(b1) # None
b2=re.match(reg, "12abc123cd")
print(b2) # <re.Match object; span=(0, 1), match='1'>
c=re.findall(reg, "abc123cd4")
print(c) # ['1', '2', '3', '4']
d=re.split(reg, "abc123cd")
print(d) # ['abc', '', '', 'cd']
e=re.finditer(reg, "abc123cd")
formathine:print(math.group(), end=" ") # 1 2 3
print()
f=re.sub(reg, "*", "abc123cd4")
print(f) # abc***cd*2. 字符"+"重复前面一个匹配字符 一次或多次 >=1
importre
reg=r"b\d+"
a=re.search(reg, "a12b123c")
print(a) # <re.Match object; span=(3, 7), match='b123'>注意:r"b\d+" 第一个字符要匹配 "b" ,后面是连续的多个数字,因此是"b123"。
3. 字符"*"重复前面一个匹配字符零次或多次 >=0
importre
reg=r"ab+"
a=re.search(reg, "acabc")
print(a) # <re.Match object; span=(2, 4), match='ab'>
reg=r"ab*"
a=re.search(reg, "acabc")
print(a) # <re.Match object; span=(0, 1), match='a'>4. 字符"?"重复前面一个匹配字符零次或一次 0 or 1
importre
reg=r"ab?"
m=re.search(reg, "abbcabc")
print(m) # <re.Match object; span=(0, 2), match='ab'>问题:匹配结果为什么不是<re.Match object; span=(0, 1), match='a'>
原因:优先级:一次 > 零次
5. 字符"."代表任何一个字符,但是没有特别声明时不代表字符"\n"
importre
s="xaxby"
a=re.search(r"a.b", s)
print(a) # <re.Match object; span=(1, 4), match='axb'>6. "|"代表把左右分成两个部分
importre
s="xaabababy"
a=re.search(r"ab|ba", s)
print(a) # <re.Match object; span=(2, 4), match='ab'>7. 特殊字符使用反斜线""引导,例如"\r"、"\n"、"\t"、"\"分别表示 回车、换行符、制表符与反斜线本身
importre
reg=r"a\nb?"
a=re.search(reg, "ca\nbcabc")
print(a) # <re.Match object; span=(1, 4), match='a\nb'>8. 字符"\b"表示单词结尾,单词结尾包括各种空白字符或者字符串结尾
importre
reg=r"car\b"
a=re.search(reg, "The car is black")
print(a) # <re.Match object; span=(4, 7), match='car'>9. "[]"中的字符表示任意选择一个,如果字符是 ASCII 码中连续的一组,那么可以使用"-"符号连接,例如[0-9]表示0-9的其中一个数字,[A-Z]表示A-Z的其中一个大写字符,[0-9A-Z]表示0-9的其中一个数字或者是A-Z的其中一个大写字符
import re
reg = r"x[0-9]y"
a = re.search(reg, "xyx2y")
print(a) # <re.Match object; span=(2, 5), match='x2y'>10. "^"匹配字符串开头位置
import re
reg = r"^ab" # 以"ab"开头
a = re.search(reg,"cabcab")
print(a) # None11. "^"出现在[]的第一个位置,就表示取反,例如ab0-9表示不是a、b也不是0-9的数字
import re
reg=r"x[^ab0-9]y"
a = re.search(reg,"xayx2yxcy")
print(a) # <re.Match object; span=(6, 9), match='xcy'>12. "\s"匹配任何空白字符,等价"[\r\n\x20\t\f\v]"
import re
s = "la ba\tbxy"
a = re.search(r"a\sb", s)
print(a) # <re.Match object; span=(1, 4), match='a b'>13. "\w"匹配包括下划线内的单词字符,等价于"[a-zA-Z0-9_]"
import re
reg = r"\w+"
a = re.search(reg, "Python is easy")
print(a) # <re.Match object; span=(0, 6), match='Python'>14."$"字符匹配字符串的结尾位置
import re
reg = r"ab$"
a = re.search(reg, "abcab")
print(a) # <re.Match object; span=(3, 5), match='ab'>15. 使用括号(...)可以把(...)看成一个整体,经常于"+"、"*"、"?"等符号连续使用,对(...)部分进行重复
import re
reg = r"(ab)+"
a = re.search(reg, "ababcab")
print(a) # <re.Match object; span=(0, 4), match='abab'>search函数虽然只返回第一次匹配的结果,但是只要连续使用 search 函数就可以找到字符串中全部匹配的字符串
应用举例
例:匹配找出英文句子中所有单词
importre
s="I am testing search function"
reg=r"[A-Za-z]+\b"
a=re.search(reg, s)
whilea!=None:start=a.start()end=a.end()print(s[start:end])s=s[end:]a=re.search(reg, s)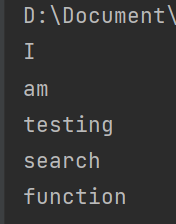
经典正则表达式
表达式 | 表示的字符串 |
^[A-Za-z]+$ | 由26个字母组成的字符串 |
^[A-Za-z0-9]+$ | 由26个字母和数字组成的字符串 |
^-? \d+$ | 整数形式的字符串(^-?表示±号) |
[1-9]\d{5} | 中国境内邮政编码,6位 |
[\u4e00-\u9fa5] | 匹配中文字符 |
\d{3}- \d{8}|\d{4}-\d{7} | 国内电话号码,010-68913536 |
\w+@(\w+.)+\w+ | 邮箱 |