北京北站武汉seo引擎优化
又到了一年一度的背题时刻,但是收到的题库是Word版的,页数特别多

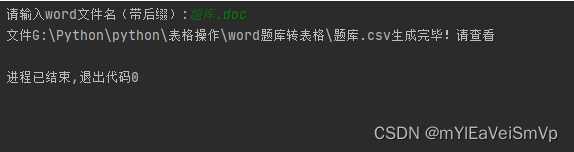
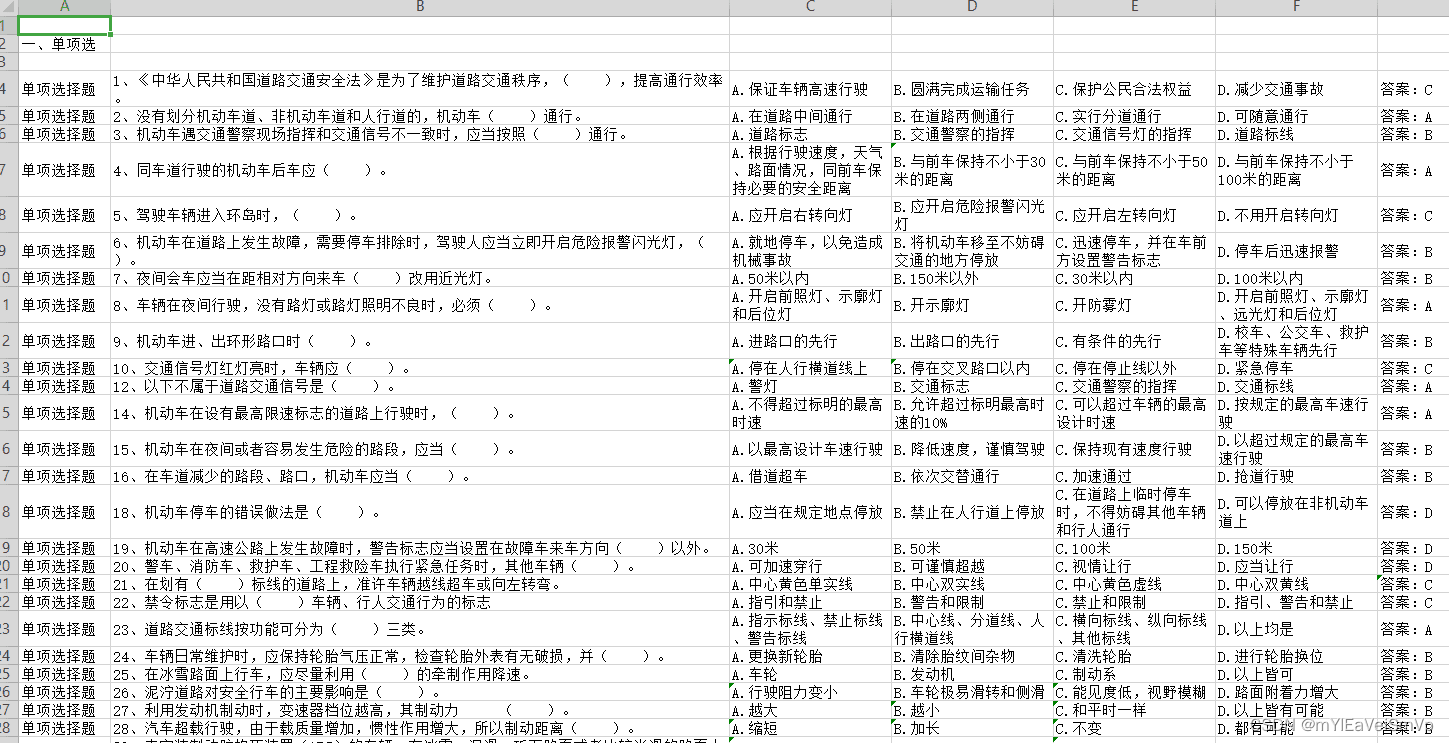
话不多说,上代码,有图有真相,代码里面备注的很详细
# 导入所需库
import csv
import os
import refrom docx import Document
from win32com import client as wc# 打开word文档def doc_to_docx(doc_file):full_path = os.path.abspath(doc_file) # 绝对路径,便于分离文件位置、名和后缀word = wc.Dispatch("Word.Application")doc = word.Documents.Open(full_path)doc.SaveAs(os.path.splitext(full_path)[0] + '.docx', 12) # 保存只改后缀 12 为docxdoc.Close()word.Quit()return os.path.splitext(full_path)[0] + '.docx'def save_to_csv(doc_name, date): # date为list [[1],[2],[3]...]name = os.path.abspath(doc_name)# os.path.splitext(name)[0]out = open(f'{os.path.splitext(name)[0]}.csv', 'a', encoding='utf-8', newline='')csv_write = csv.writer(out, dialect='excel')for row in date:csv_write.writerow(row)out.close()print(f'文件{os.path.splitext(name)[0]}.csv生成完毕!请查看')if __name__ == '__main__':"""为防止格式错乱,请先在源文件里执行将^l替换为^p操作默认每个题目开头序号都是数字,如果不是,需要修改question_start_num对应的re代码"""file_name = input("请输入word文件名(带后缀):") # "2.doc"TG_style = '一二三四五六七八九、' # 大题干类型(最后一位为符号)choose_split = "、" # 选项分割符号A、 A.if file_name.endswith('.doc'): # 加快处理速度:.docx比doc处理速度快,所以如果不是x结尾的转成x的file_name = doc_to_docx(file_name)document = Document(file_name)# 获取所有段落all_paragraphs = document.paragraphsstart_num = 0 # 主干序号下角序号TX = '' # 题型All_content = [] # 存储所有题内容tem = [] # 临时存储每个题类型、题干、选项、答案for paragraph in all_paragraphs:# 打印每一个段落的文字# print([paragraph.text])tittle_split = '、'question_start_num = re.compile(f'^\d') # 识别题干头是否是数字p = re.compile(f'^{TG_style[start_num] + TG_style[-1]}') # 匹配开头字符,筛选出大标号,区分题目类型tittle_ret = question_start_num.search(paragraph.text) # 识别题干头ret = p.search(paragraph.text) # 识别题型if ret:TX = paragraph.text.replace((TG_style[start_num] + TG_style[-1]), '', 1)start_num += 1# tittle_num = 1# print(TG)All_content.append(tem)tem = []All_content.append([paragraph.text]) # 读完题型,说明进入了题目内容else:if tittle_ret: # 是否是题干All_content.append(tem) # 如果是题干,证明上一题遍历完毕,进行缓存tem = [TX] # 保存题型在第一位# print(f"{TG}{paragraph.text}")# tittle_num += 1 # 遇到题号不连续时继续处if All_content: # 不是题干,缓存写了,说明在读取选项'''此处为了区分一行有多个选项的情况,逐个读取出来'''chooses = re.split(f"[A-Za-z]{choose_split}", paragraph.text)for choose in chooses:if choose.replace(' ', ''): # 替换掉选项中空格进行过滤#print(choose)tem.append(choose)save_to_csv(file_name, All_content)题库已打包,有环境的直接RUN,有问题可以咨询(不保证一定解决)