百度网盟推广费用是多少seo分析
1. Transformer 由来 & 特点
1.1 从NLP领域内诞生
"Transformer"是一种深度学习模型,首次在"Attention is All You Need"这篇论文中被提出,已经成为自然语言处理(NLP)领域的重要基石。这是因为Transformer模型有几个显著的优点:
-
自注意力机制(Self-Attention):这是Transformer最核心的概念,也是其最大的特点。通过自注意力机制,模型可以关注输入序列中的所有位置,并为每个位置分配不同的注意力权重。这使得模型能够更好地处理长距离的依赖关系,也就是说,对于句子中距离较远的单词,模型也能有效地捕获其关系。
-
并行计算:在之前的很多模型中,如RNN(循环神经网络),处理序列数据需要按照时间步顺序进行,这在处理长序列时会非常慢。而Transformer模型可以同时处理所有的输入,这使得它在大规模数据训练中有显著的效率提升。
-
可扩展性:Transformer模型可以轻松地通过增加层数、隐藏层单元数等来增加模型大小,使其能够处理更复杂的任务。
正因为这些优点,Transformer模型在很多NLP任务上都有出色的表现,包括机器翻译、文本摘要、情感分析等等。后续发展出的BERT、GPT等模型,都是基于Transformer的架构,进一步推动了AI领域的进步。
1.2 计算机视觉 + Transformer
尽管Transformer最初是为处理自然语言处理(NLP)任务设计的,但近年来,它也被广泛应用于计算机视觉(CV)领域,包括图像分类、对象检测、图像分割等任务。
Transformer在视觉领域的应用主要体现在以下两个方面:
-
图像中的长程依赖:与NLP问题类似,图像中的像素也存在长程依赖性。例如,一幅图像中的某个部分可能会对图像的其他部分产生影响。Transformer的自注意力机制可以捕捉到这些依赖关系。
-
端到端的全局优化:传统的卷积神经网络(CNN)通常会使用局部的卷积操作来提取图像特征,这些操作不容易捕获全局的图像信息。而Transformer的自注意力机制可以直接处理全局的信息,能实现端到端的全局优化。
其中,一个代表性的视觉Transformer模型是ViT(Vision Transformer)。ViT模型将图像切割为一系列小的patch,然后将这些patch视为序列输入,使用Transformer对其进行编码。这样就可以将全局的图像上下文信息整合到每一个patch的表示中,有助于提升视觉任务的性能。
至今为止,包括ViT在内的一些视觉Transformer模型已经在多个重要的计算机视觉任务中取得了最先进的结果,显示出Transformer架构的巨大潜力和广泛应用性。
必须读:ViT中的Self-Attention
1.3 自注意力机制 Self-Attention
自注意力机制(Self-Attention Mechanism),也被称为自我注意力机制或者只是注意力机制,是Transformer模型的核心部分。自注意力机制的基本思想是在处理序列数据时,不只是关注当前的输入,而是关注整个序列,并且为序列中的每一个元素赋予不同的重要性或权重。
自注意力机制的运作流程如下:
-
首先,每个输入元素都有三个向量表示:Query(查询),Key(键),Value(值)。这些向量是输入元素经过不同的线性转换(也就是乘以权重矩阵)得到的。
-
然后,通过计算Query和所有Key的点积,得到每个元素的得分。这个得分反映了当前元素与其他元素的关联程度。更高的得分意味着这两个元素更相关。
-
接着,将这些得分经过softmax函数转换为概率值,这样所有的得分加起来就为1了。这个概率值就是注意力权重,反映了模型对每个元素的关注程度。
-
最后,用这些注意力权重去加权求和所有的Value,得到最终的输出。
这样,每个输出都包含了整个序列的信息,而且这个信息的整合是根据每个元素与当前元素的相关性进行的。这使得模型能够捕捉到长距离的依赖关系,并且可以并行处理整个序列,大大提高了效率。这就是自注意力机制的魅力所在,也是Transformer模型能够在很多任务上取得优秀表现的原因。
2. 台大李宏毅:自注意力机制 Self-Attention
这一part是看视频做的笔记,视频可以在B站上找到~
- 可扩展性强:轻松增加Self-Attention的层数!!
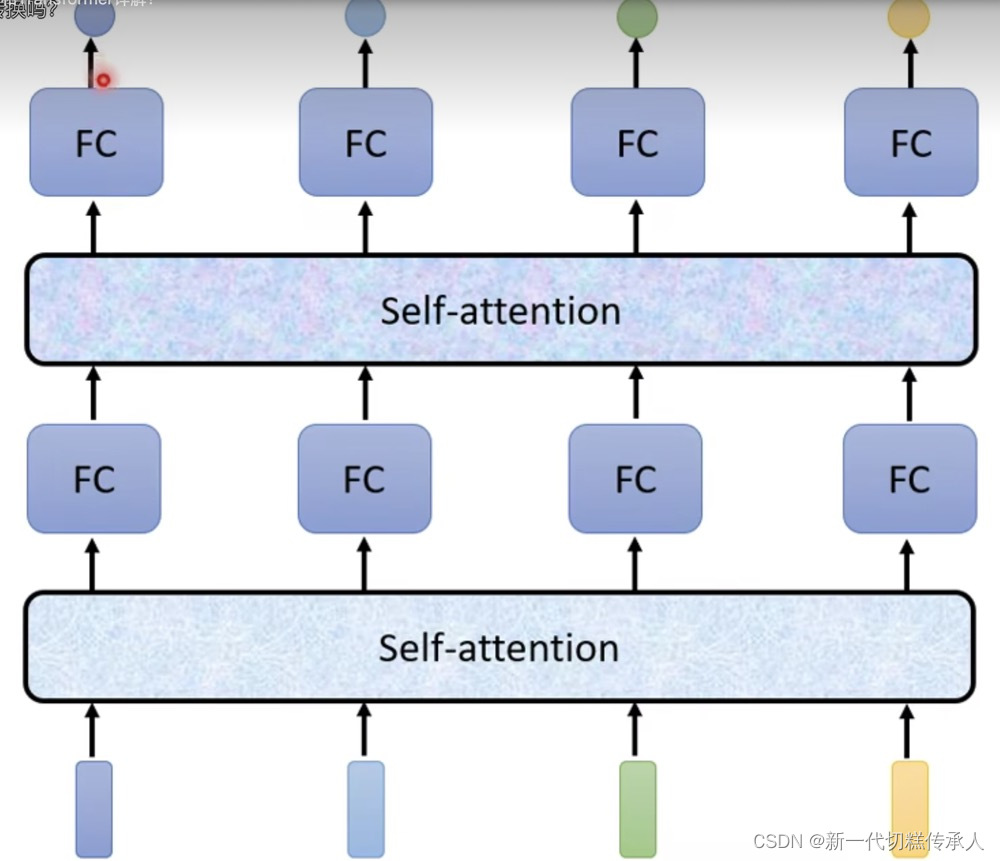
Seq2Seq模型:
- 自注意力机制核心:vector --> vector 考虑了整个input sequence才产生了每一个output!!!
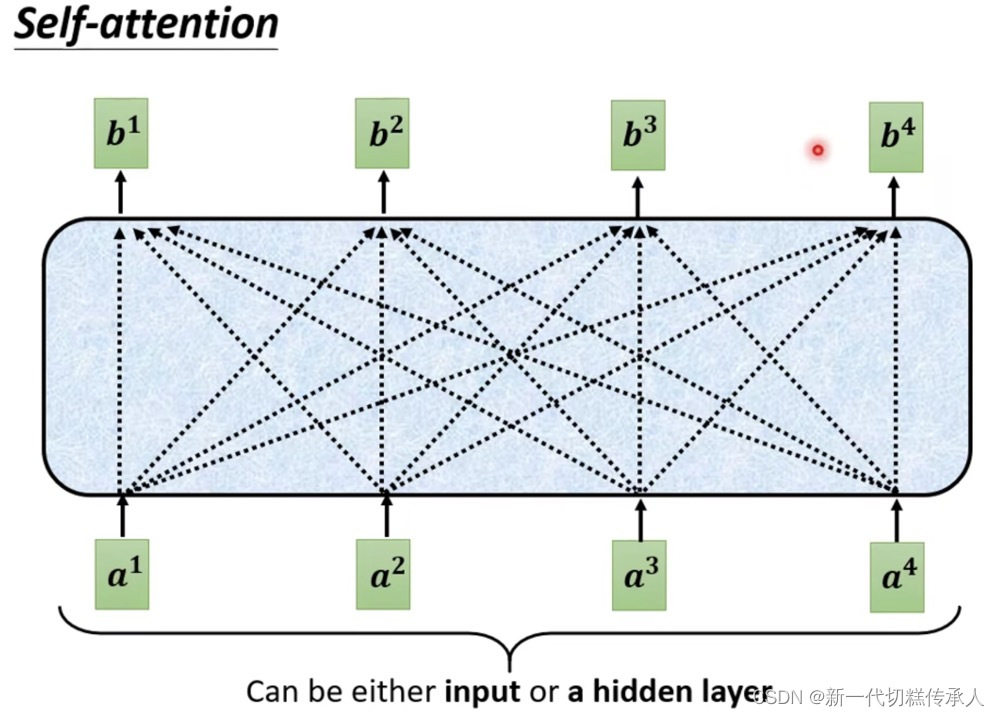
- 上图中,如何产生每一个output vector?
学习链接:20’25’'起看
Step 1: Find the relevant vectors in a sequence!
找到其它vectors中,哪些vector是对判断a1的label是重要的!
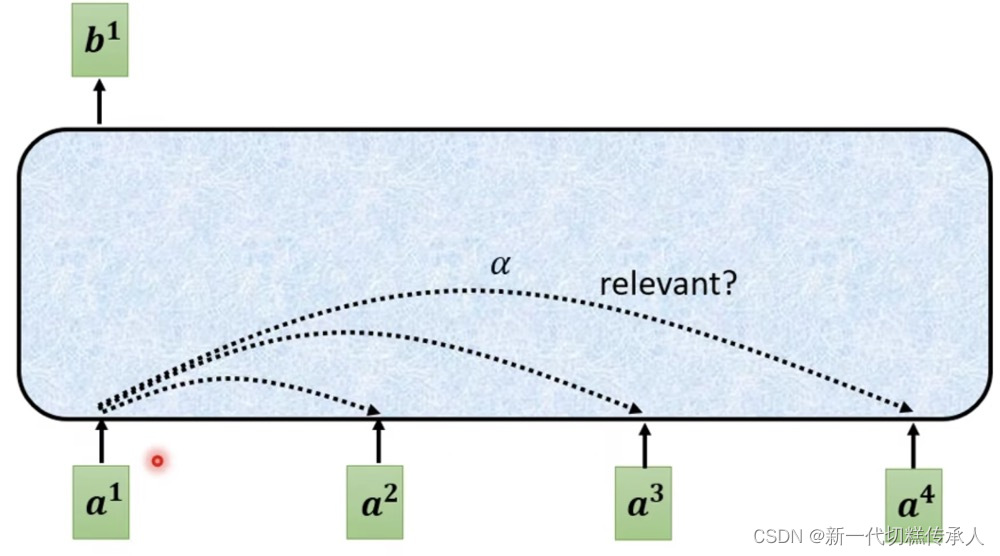
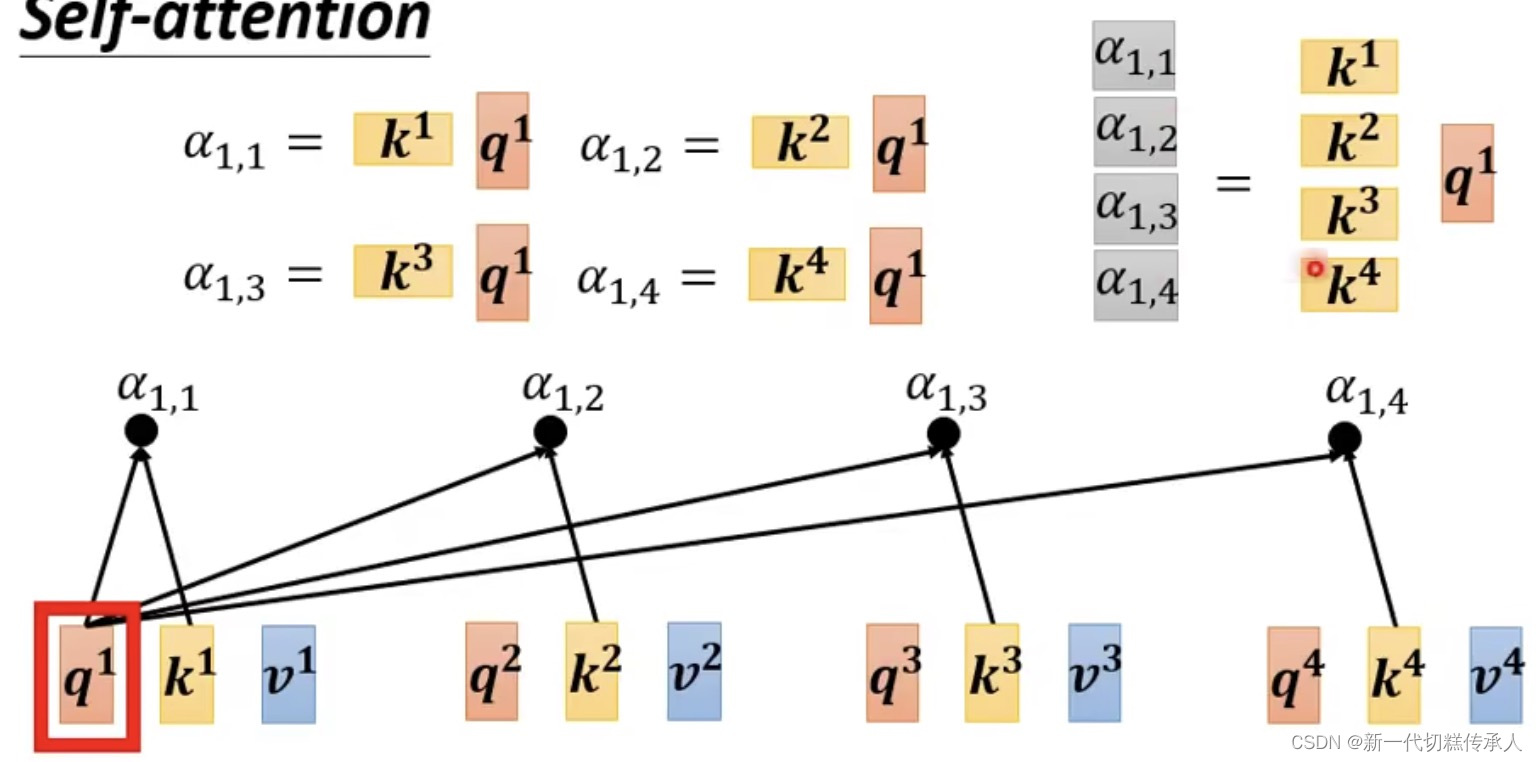
a1和a4有多相关?相关度α计算:使用「计算attention的module」!
下面是 两种常见的【相关度α计算module】
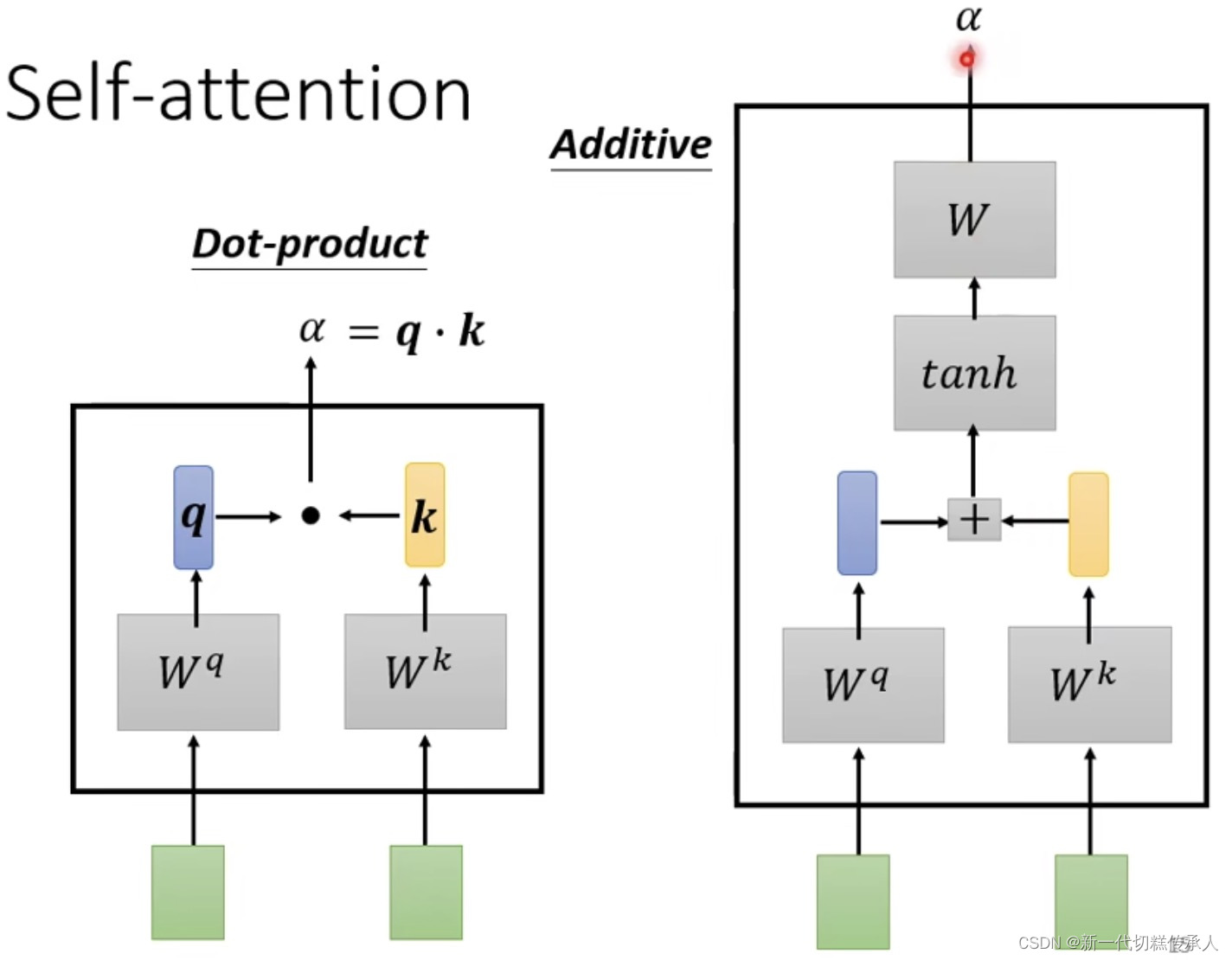
其中,Dot-product (点积)是最常用的,用在了 Transformer 里。
然后使用计算 Dot-product 来计算 attention score(即:关联性)。
下图中经过Dot-product得到的 α1,1 α1,2 … α1,4 就是 α1和α2,α3,α4的关联性!!!
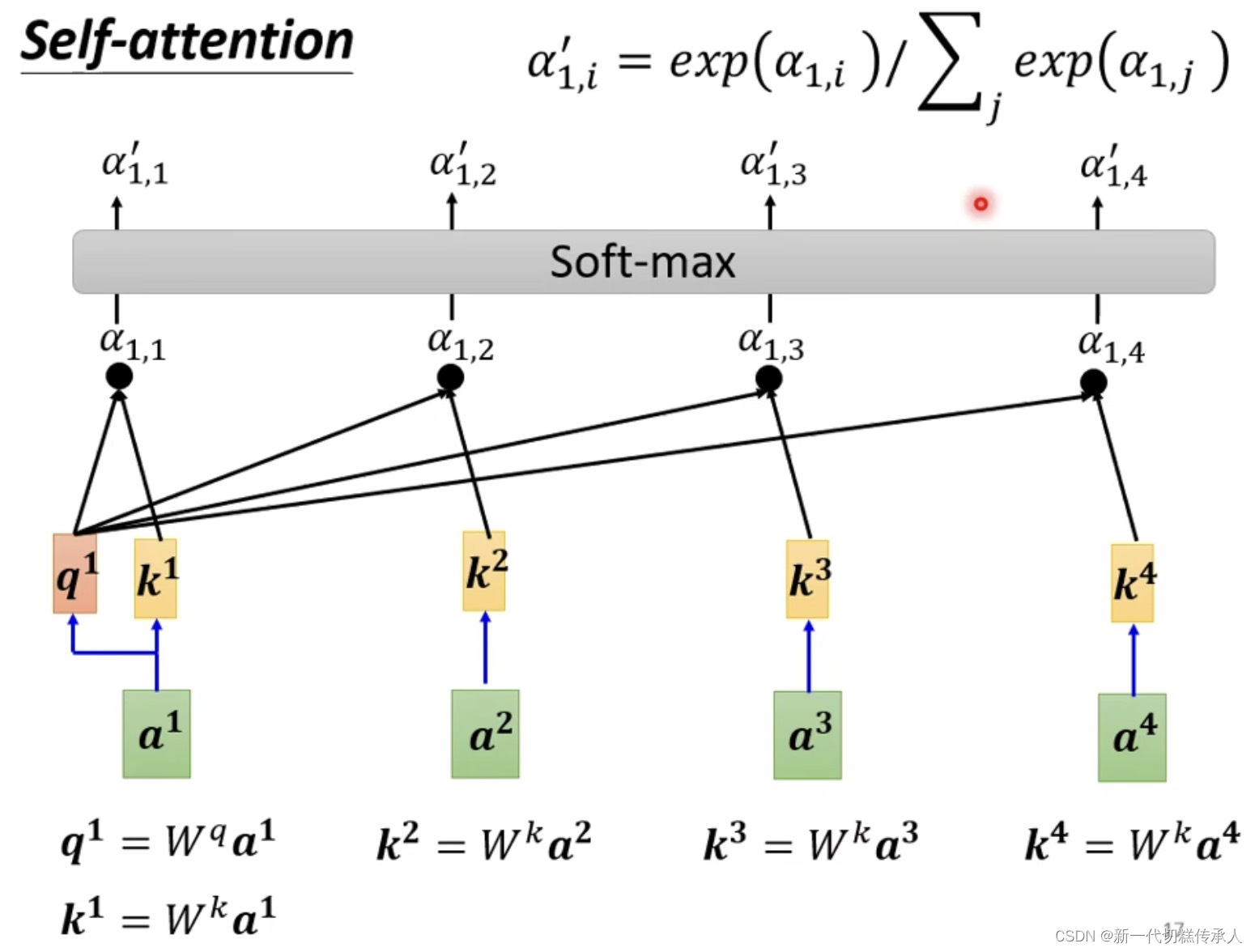
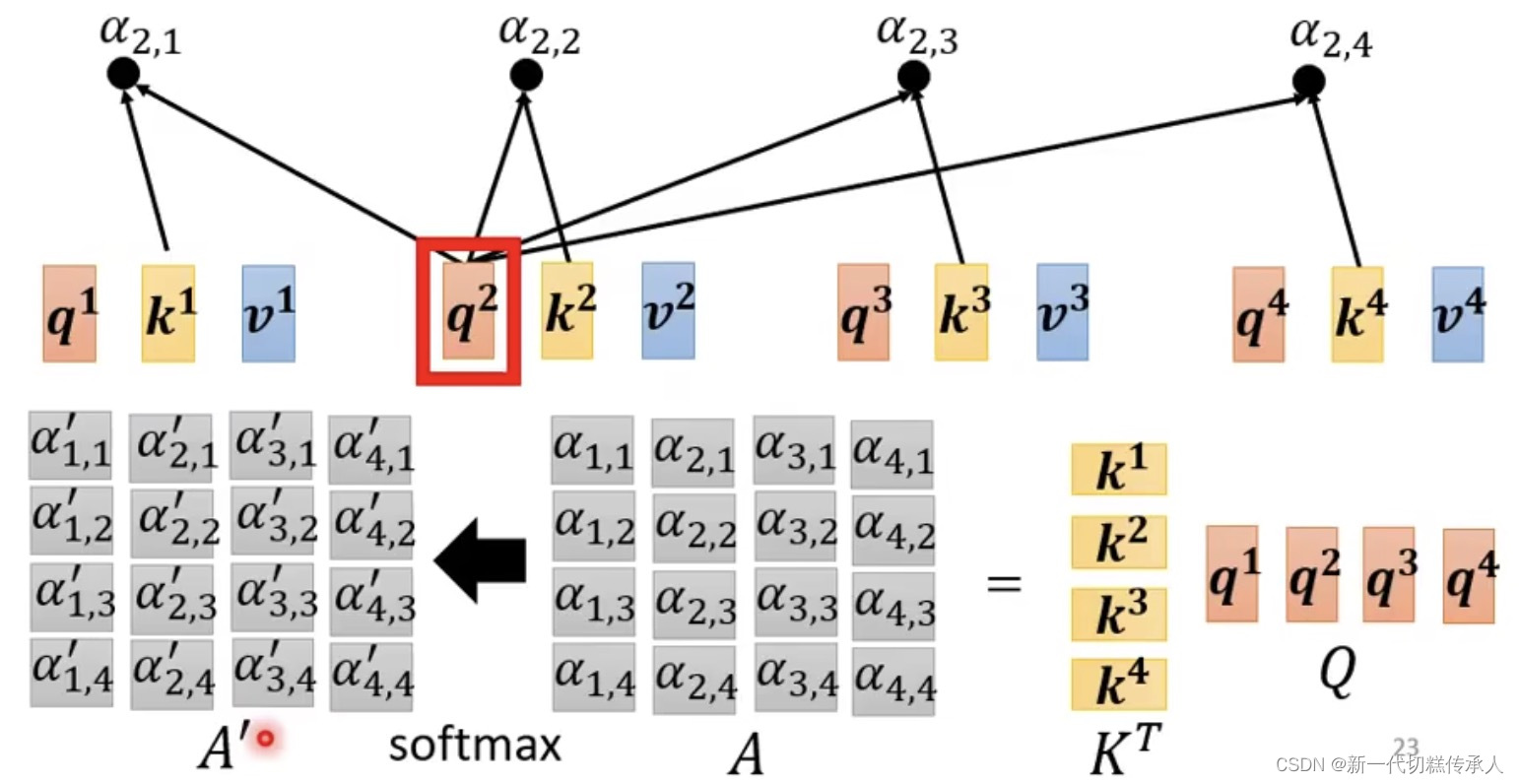
soft-max的作用是:生成「注意力权重」
将这些得分经过softmax函数转换为概率值,这样所有的得分加起来就为1了。这个概率值就是注意力权重,反映了模型对每个元素的关注程度。
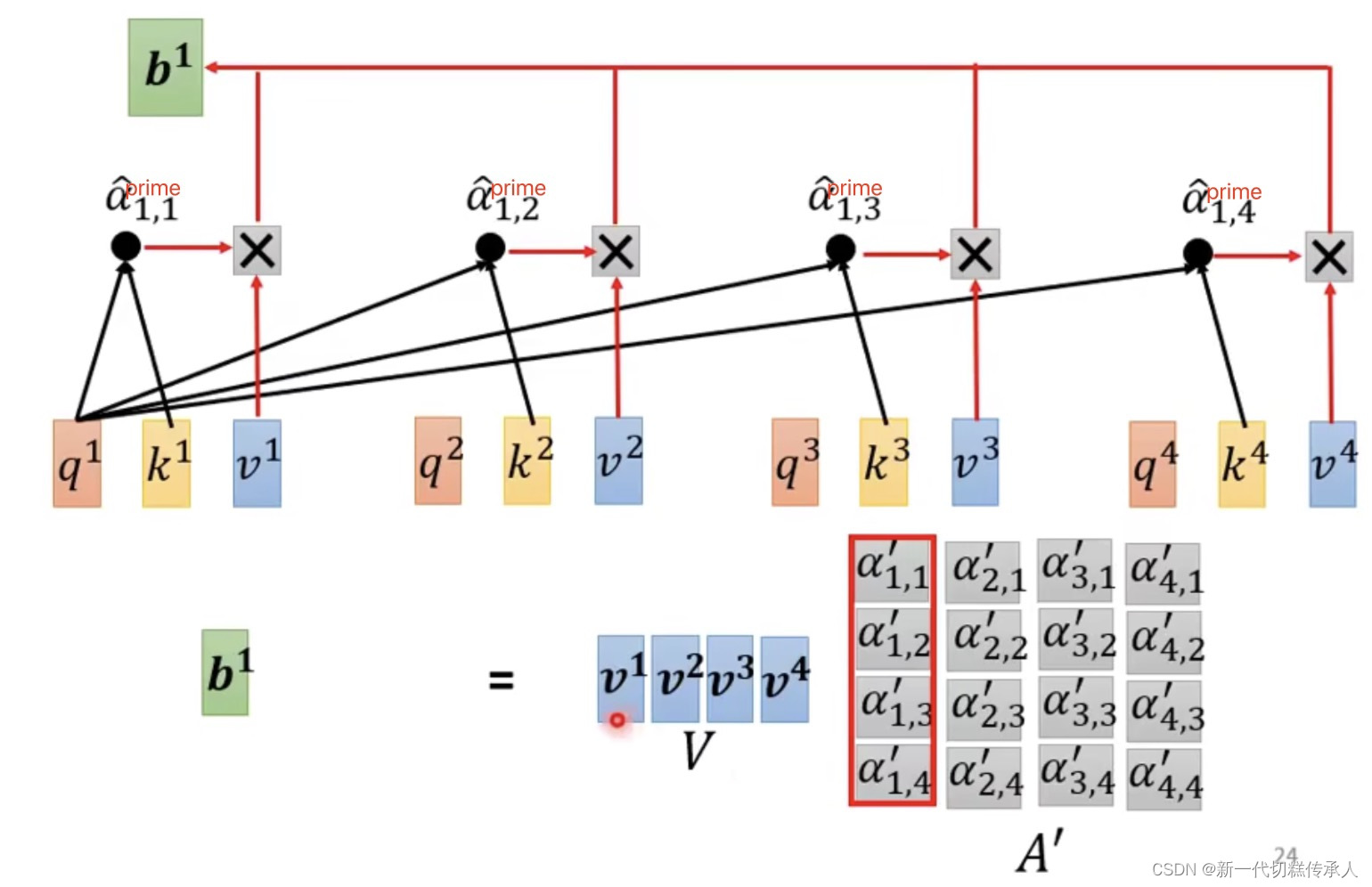
Step 2: Extract information based on attention scores!
根据attention score’ (注意力权重),去抽取重要的information!
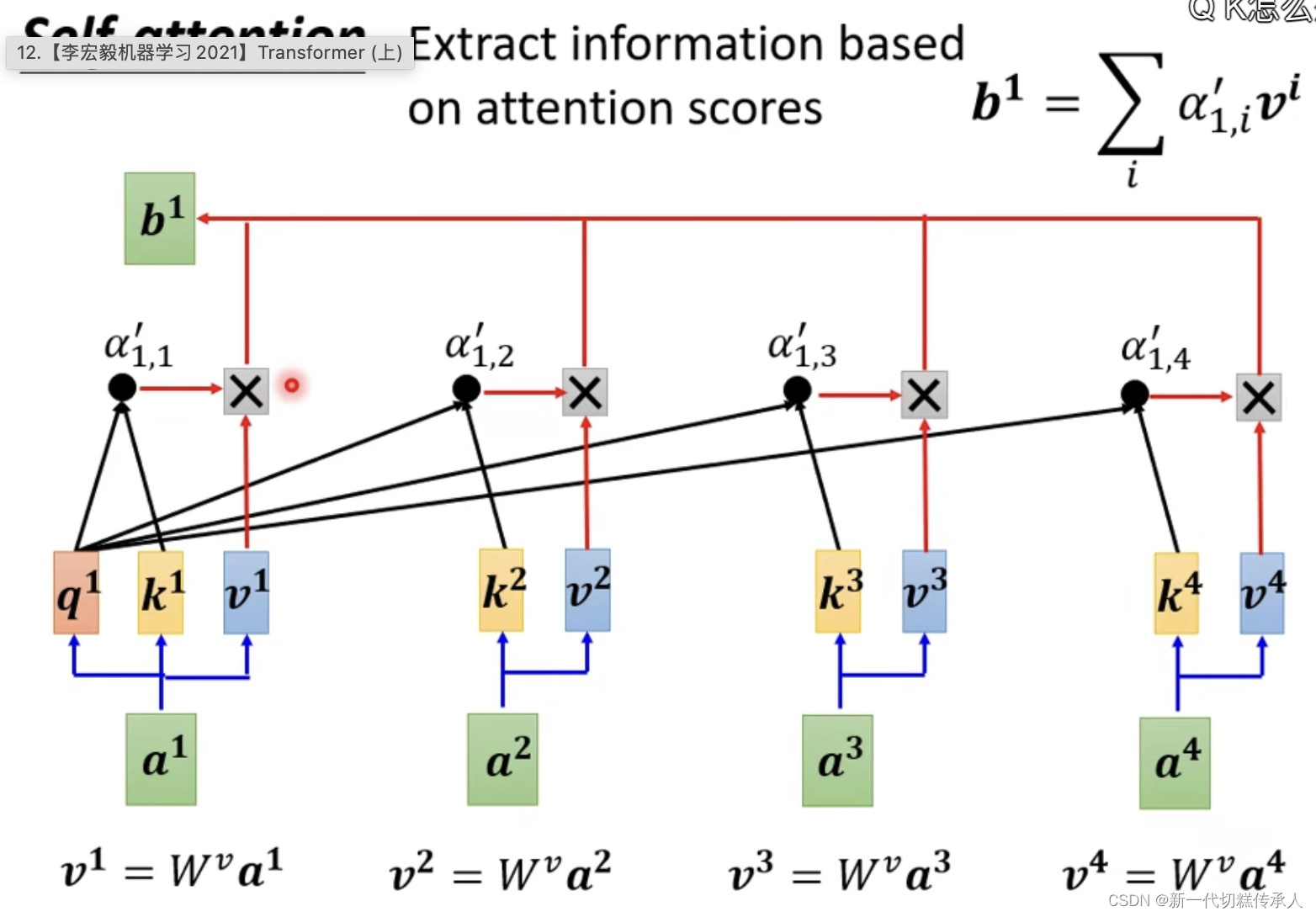
并行计算的思想在这也有体现!上图仅展示计算b1的过程,但b1、b2、b3、b4 实际上是平行被计算的,他们是并行的(从矩阵操作的角度看)!在大规模数据中效率也很高!
下面这些图是从矩阵计算的角度来看attention的执行过程~——
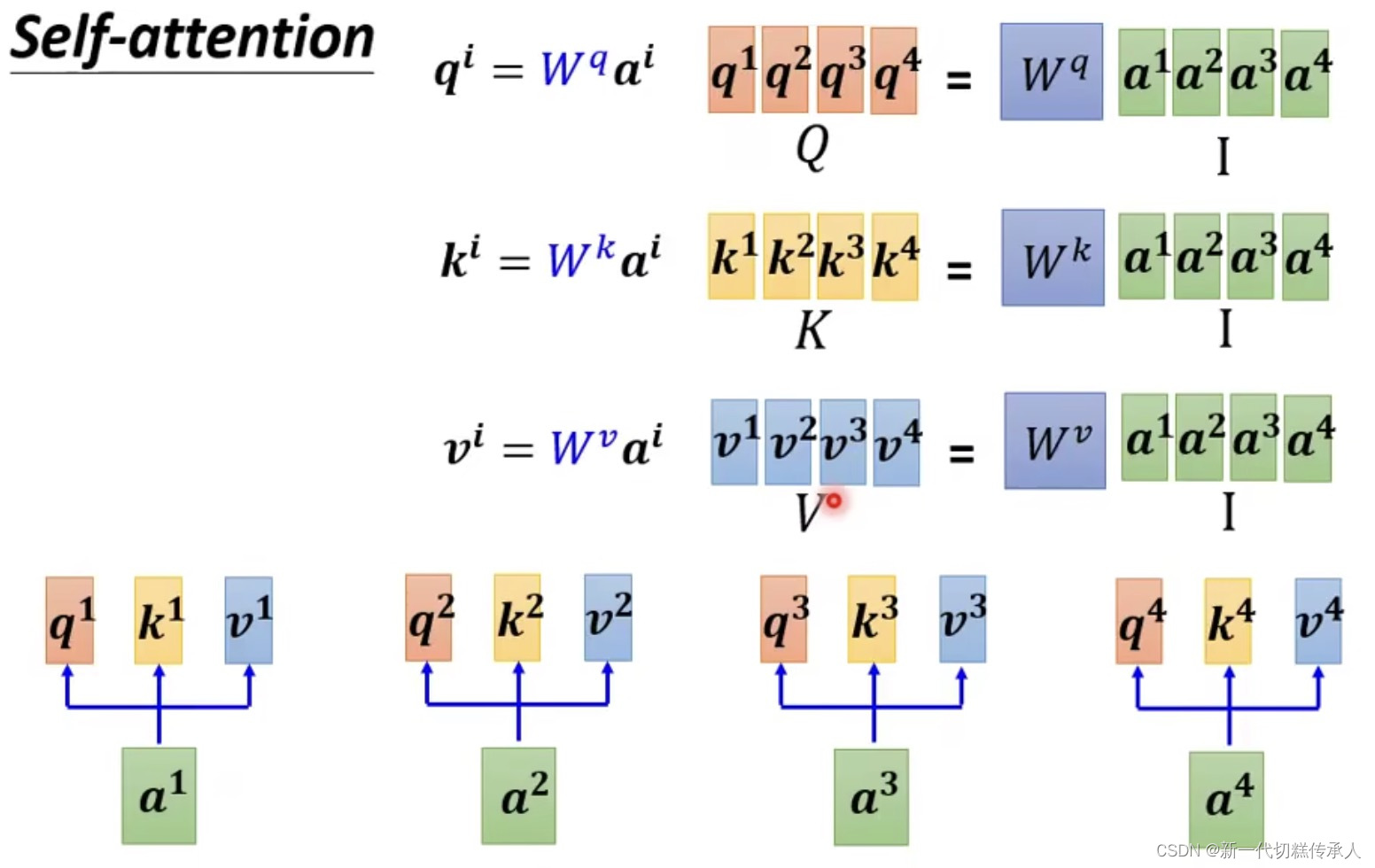
总而言之,言而总之,self-attention技术可以归结为 一整串的矩阵乘法: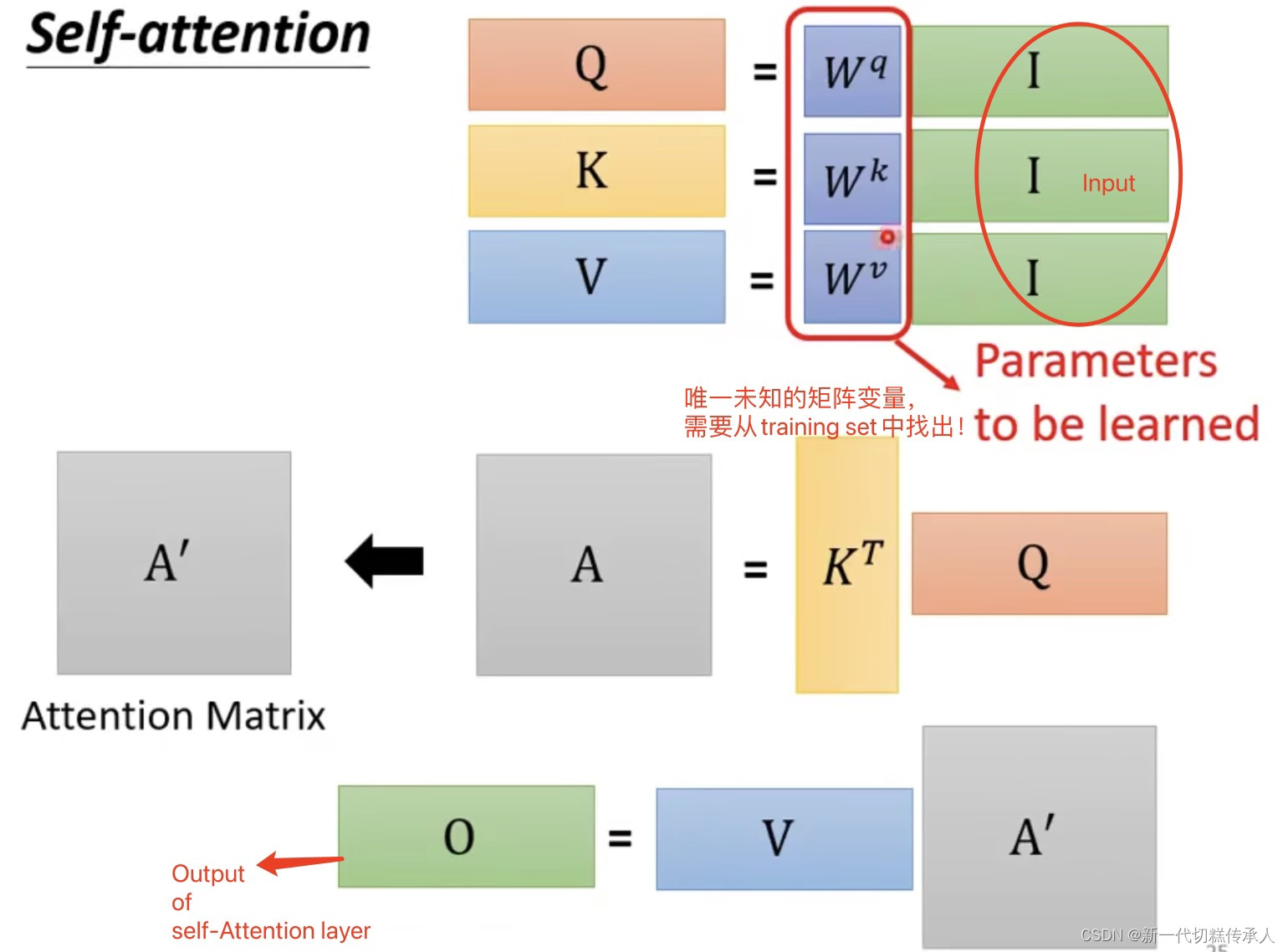
Multi-Head Attention
指的是多组q,k,v分别做self-attention,在同一个网络里。
特点:
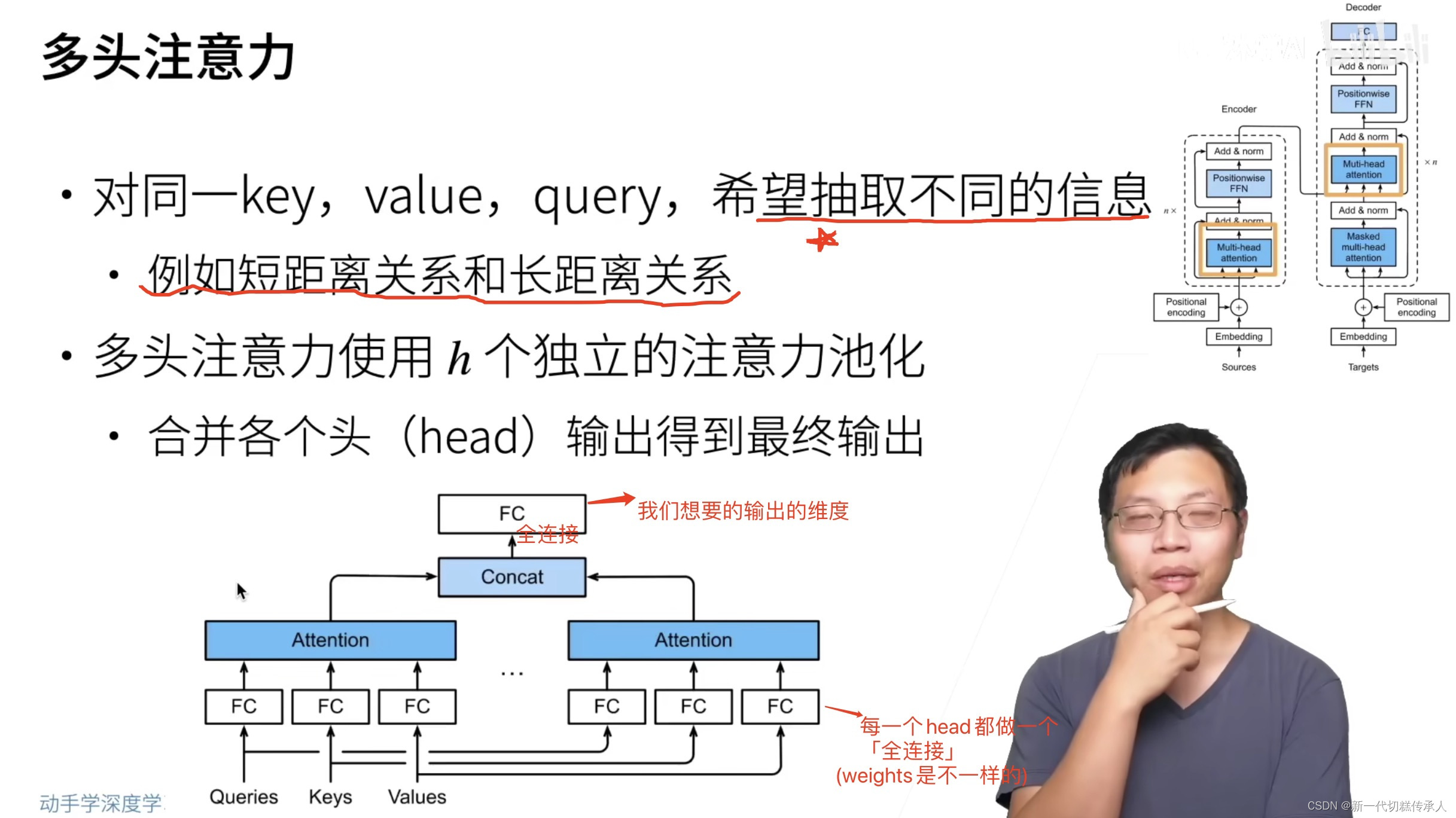
- 目的:多头注意力的设计允许模型同时在不同的表示子空间(representation subspaces)上学习和获取信息。每个头可以关注输入的不同部分。
- 定义:在传统的注意力机制中,我们有一个查询(Q), 键(K)和值(V)。对于多头注意力,我们不仅有一套Q、K和V,而是有多套(每个“头”一套)。这意味着模型可以在多个子空间上并行地学习不同的注意力权重。
- 操作:
对于每一个头,我们首先通过权重矩阵来线性变换输入的Q、K和V。
使用变换后的Q、K和V计算注意力权重并得到输出。
各个头的输出会被拼接起来,并通过另一个线性变换得到最终的多头自注意力输出。 - 参数共享:每个头都有自己的权重矩阵,但在整个模型的训练过程中,这些权重都是被学习的。这意味着每个头可以学到不同的注意力策略。
- 优点:通过使用多头,模型可以捕捉到更丰富的信息和更复杂的模式。例如,一个头可能会专注于句子的语法结构,而另一个头可能会专注于句子的语义内容。
- 实际应用:在NLP任务中,如机器翻译、文本分类等,使用多头自注意力机制的Transformer模型已经成为了一种标准做法。此外,这种结构也已被用于其他领域,如计算机视觉,因为它提供了强大的表征学习能力。(在实际实现中,需要注意如何正确地进行权重共享、如何组合多头输出以及如何调整头的数量来达到最佳的效果。)
Positional Encoding 「位置」
一句话概括,Positional Encoding就是句子中词语相对位置的编码,让Transformer保留词语的位置信息。
似乎在NLP用的多。看:【AI理论学习】对Transformer中Positional Encoding的理解
Self-Attention 在 CV领域的使用(原始idea):
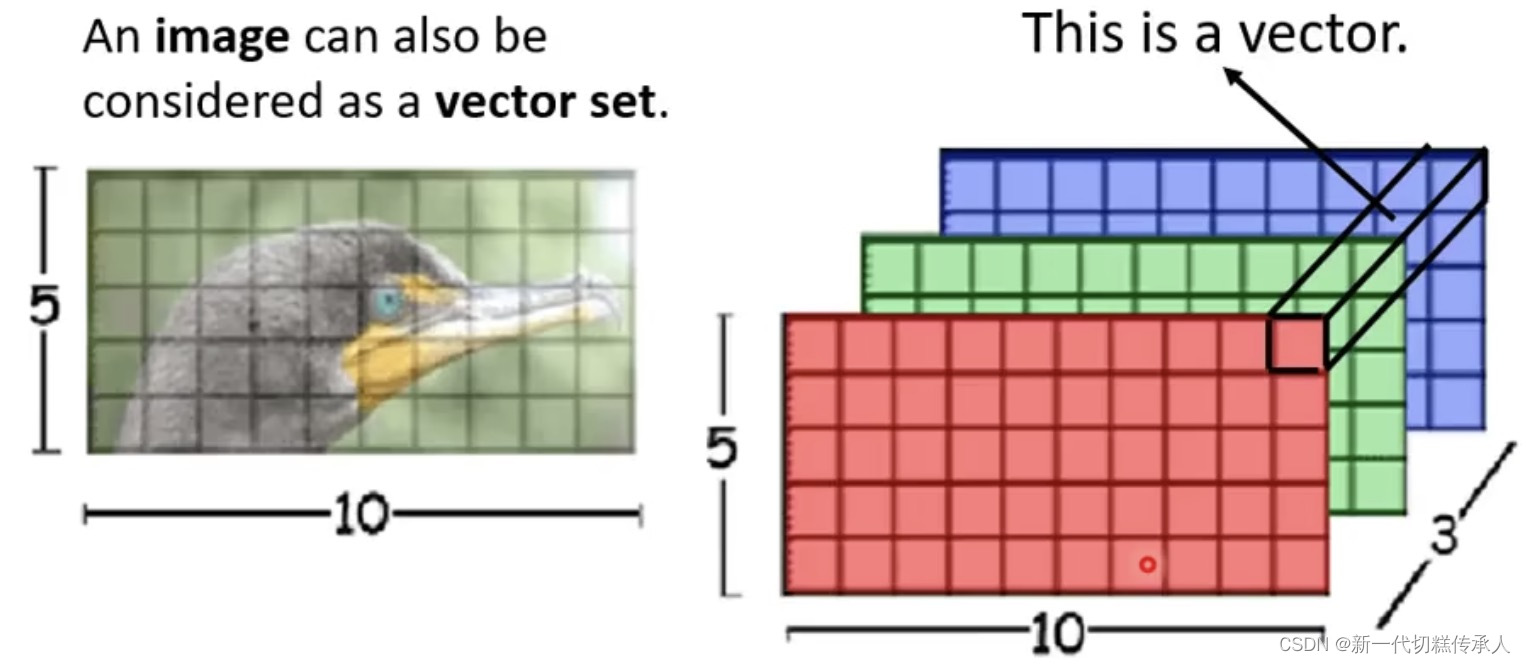
一张5x10 pixels的图可以看作是一个vector set。因为RGB的三channels图像那就是5x10x3的tensor,其中的每一个pixel就是一个三维的vector。
应用了 Self-Attention 的CV models:DETR,self-attention GAN

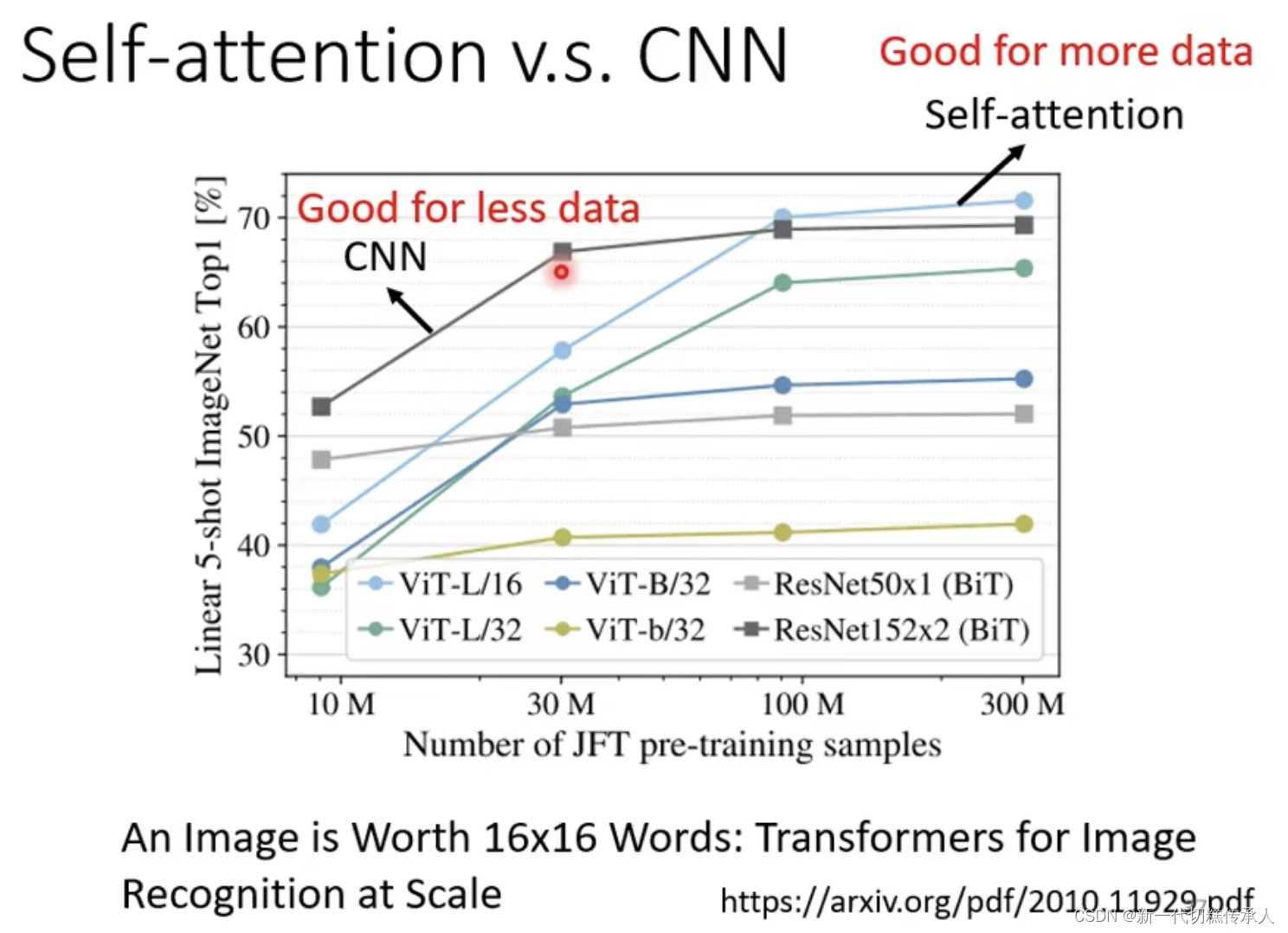
CNN其实就是self-Attention的一个特例。 但,数据量少的时候CNN更好用(此时self-attention因弹性大所以容易过拟合),而数据量多的时候self-attention能取得更好的结果! 参见下图。
此外,Self-Attention取代了RNN!因为干的事情是差不多的,但RNN需要大量的memory,而self-attention能做到“天涯若比邻”!!(如下图所示)
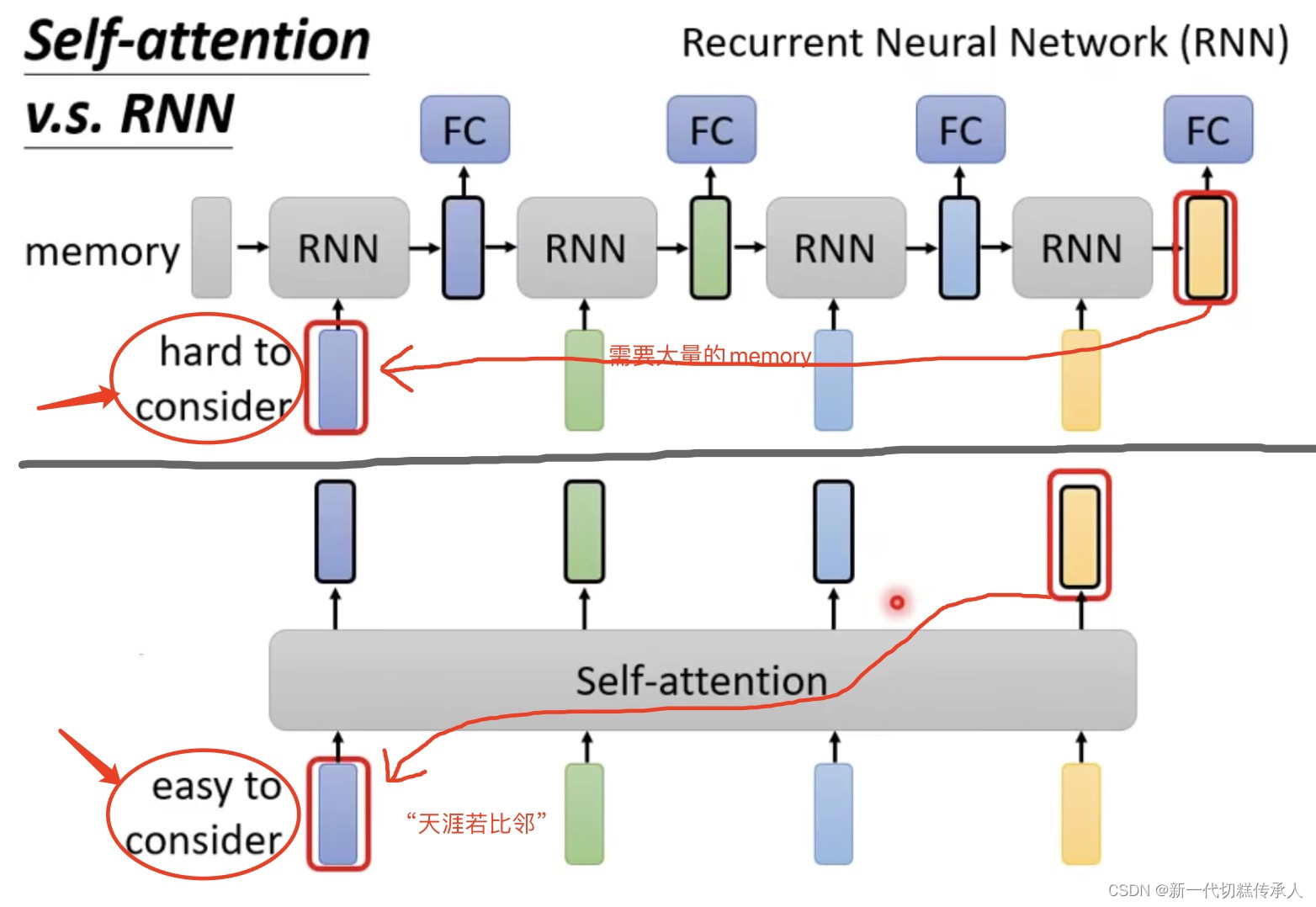
而且,RNN在计算时不是parallel的!它需要从左到右一个一个往下继续计算(看上图可知)。而self-Attention是parallel计算的,可以平行处理所有的输出,效率非常高!工业界已逐渐把RNN架构的产物逐渐改成self-Attention架构了。
3. 台大李宏毅:Transformer
3.1 概述 | Encoder | Decoder
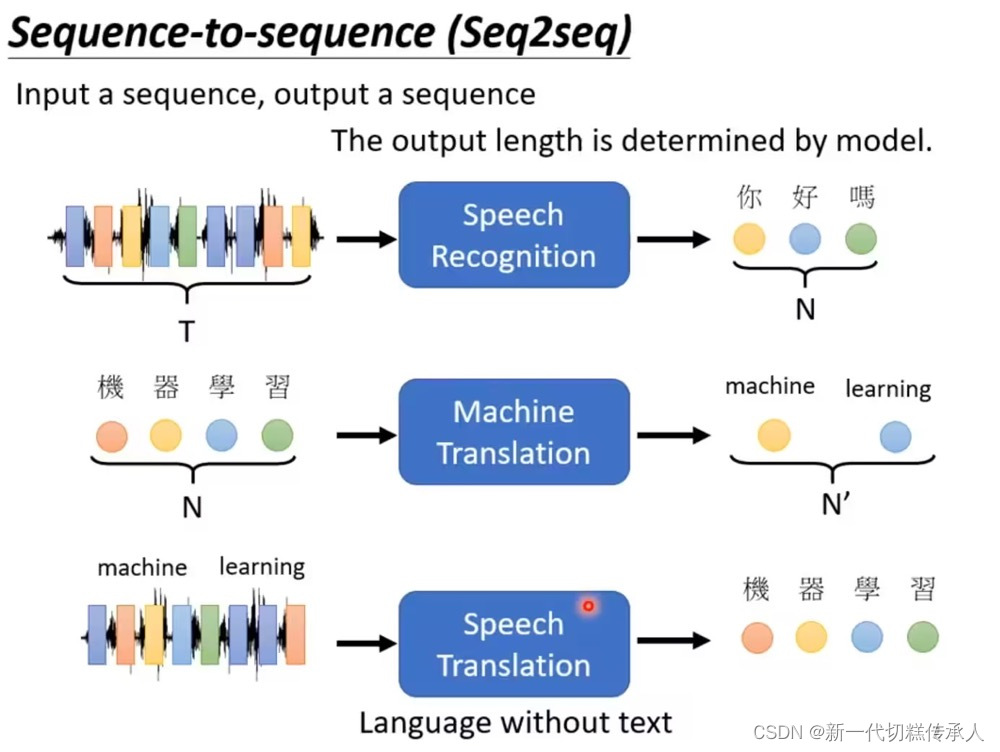
Transformer是一个sequence-to-sequence (Seq2seq) model。也就是input和output都是sequence。而output的sequence,可以是定长的,也可以是和input一样长的,也可能是我们不知道有多长的需要机器自己判别的。
例如:语音辨识,声音讯号–>文本,这个场景下的output就是机器自己决定的。机器翻译同理。
文本 & 声音讯号互转 案例:中文文字---->台语/闽南语 点击精准空降
「硬train一发」指不知道输出是多长的,干脆直接把数据丢进去让seq2seq模型自己来决定输出啥。
Seq2seq模型中,Encoder读入数据,处理后丢给Decoder,由Decoder来决定要输出多少东西。
1. Encoder
Input一排向量,output一个同样长度的向量。
每个Encoder里面可能有好几个blocks,每个block里面可能有好几个layers在干各种事情!
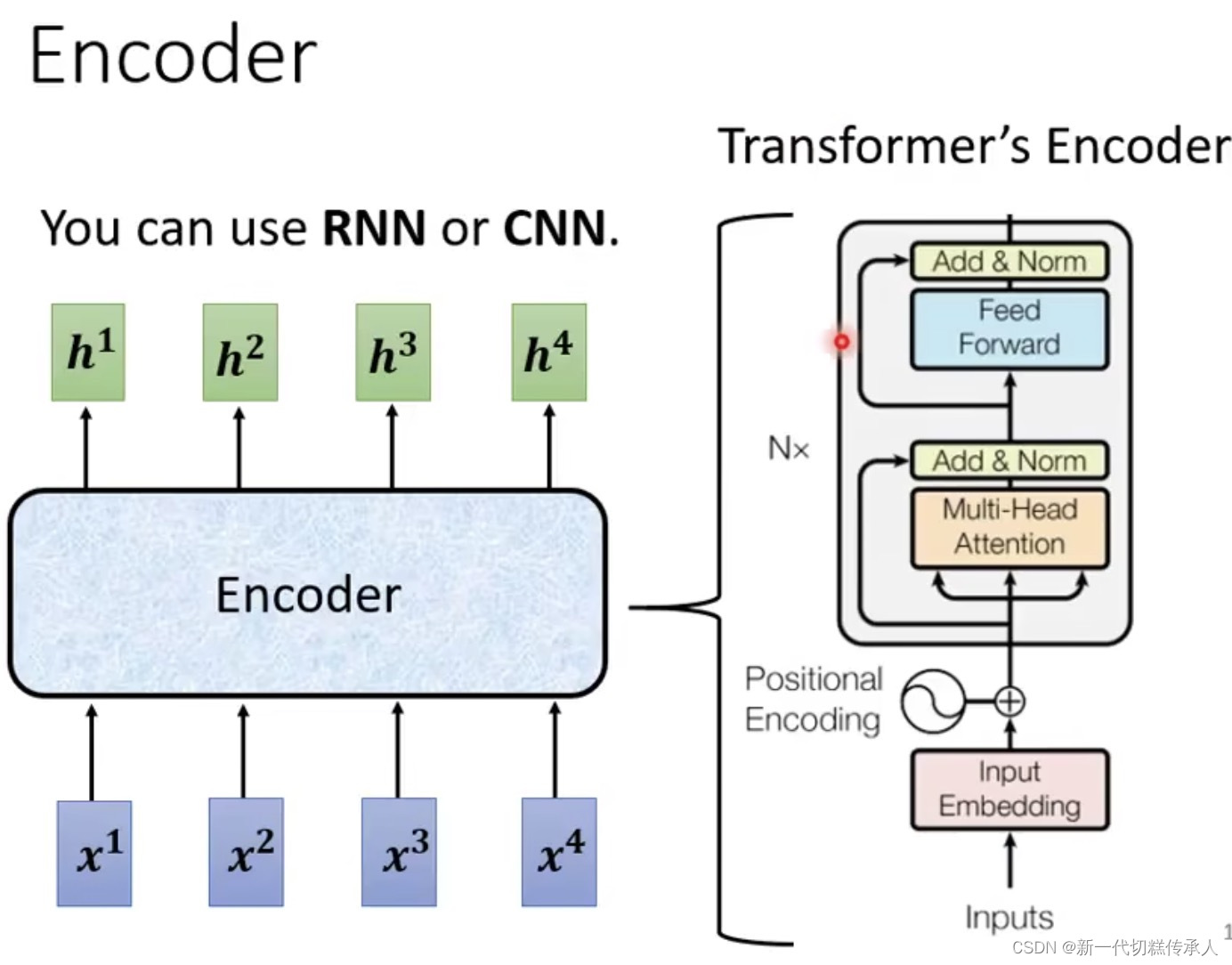
2. Decoder
以语音辨识为例,即声音讯号转文字。
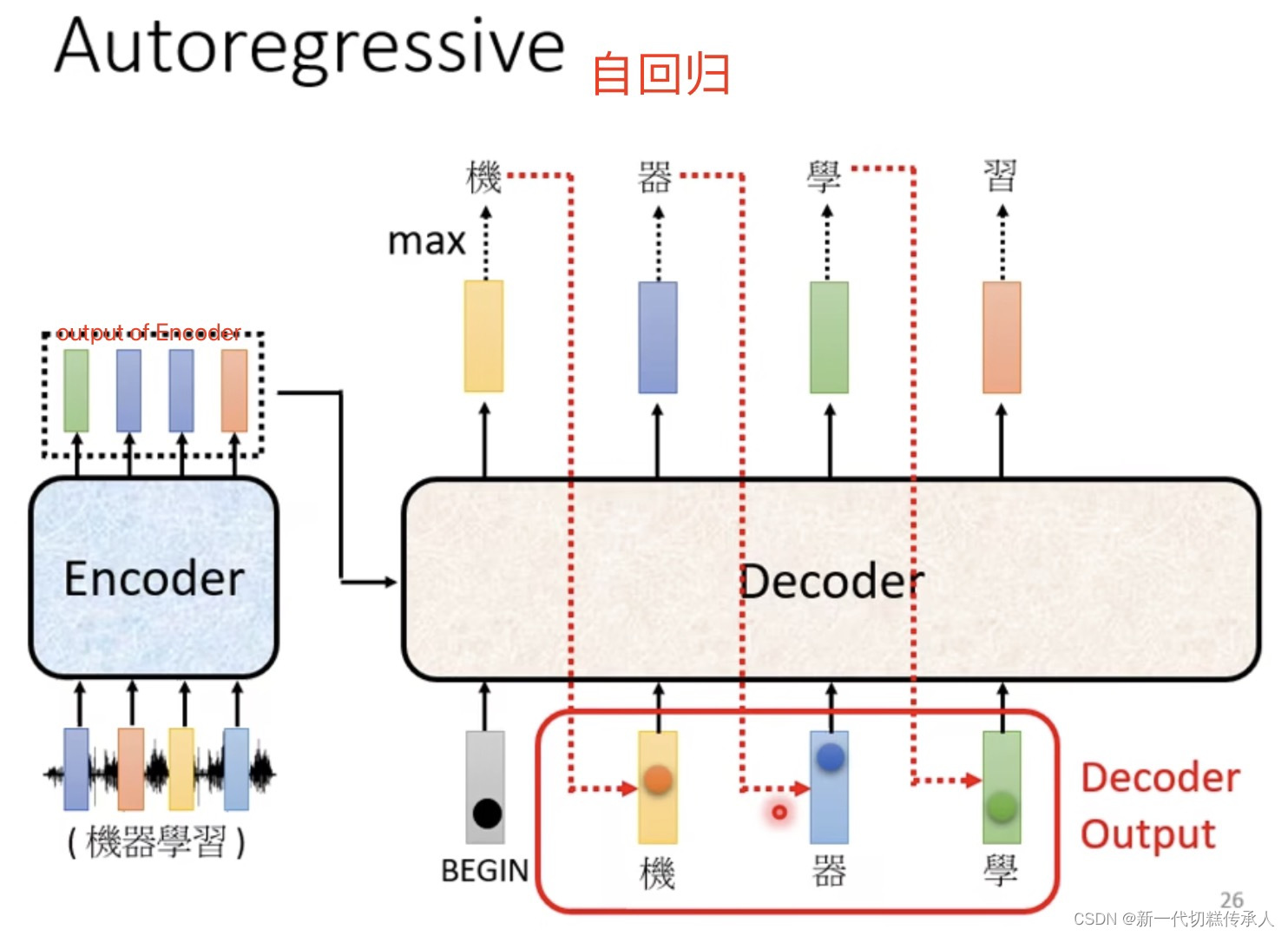
Decoder必须自己决定输出的sequence的长度。
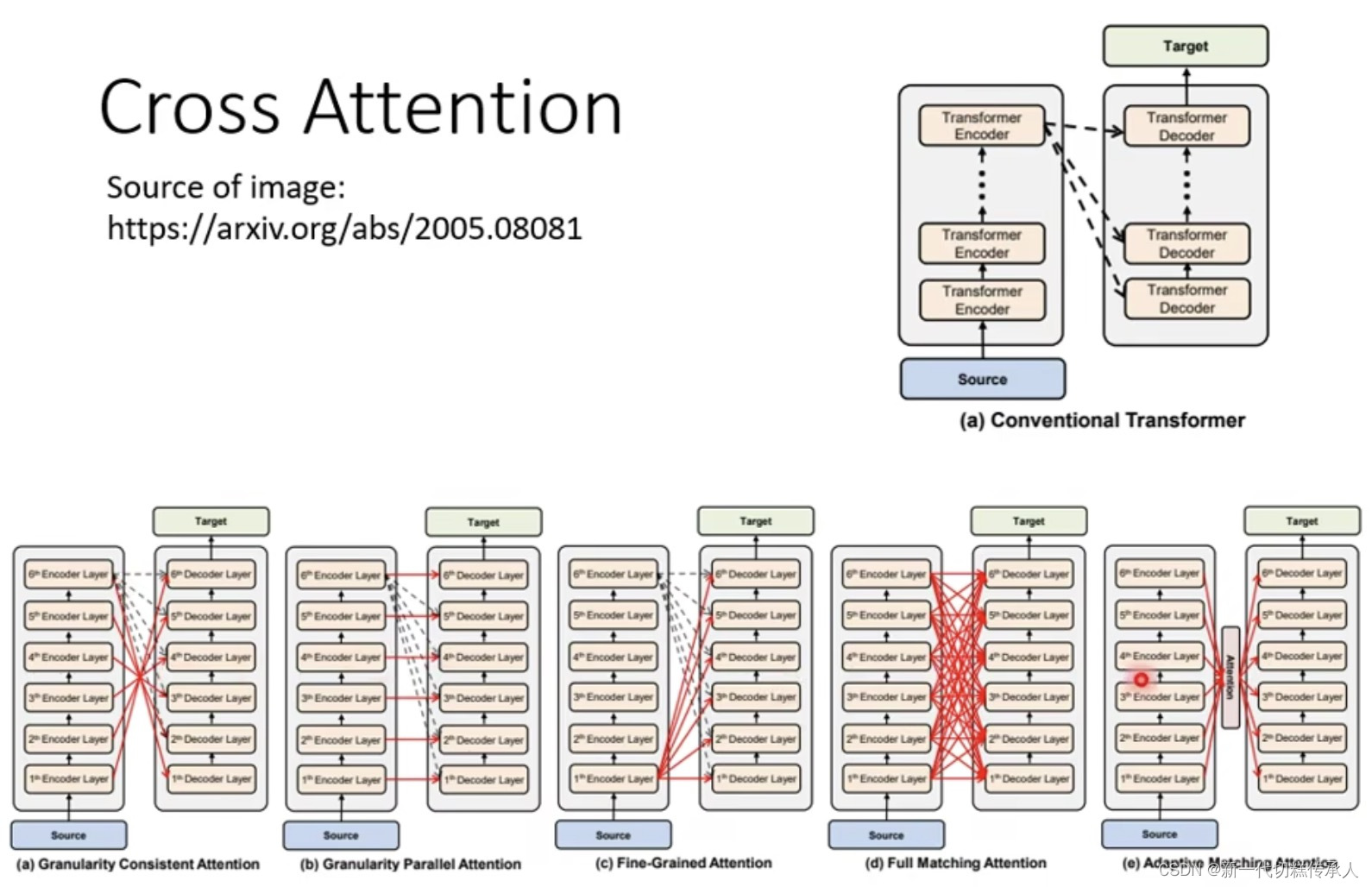
3. Encoder 和 Decoder 之间如何传递数据
各式各样的传递方式。。。
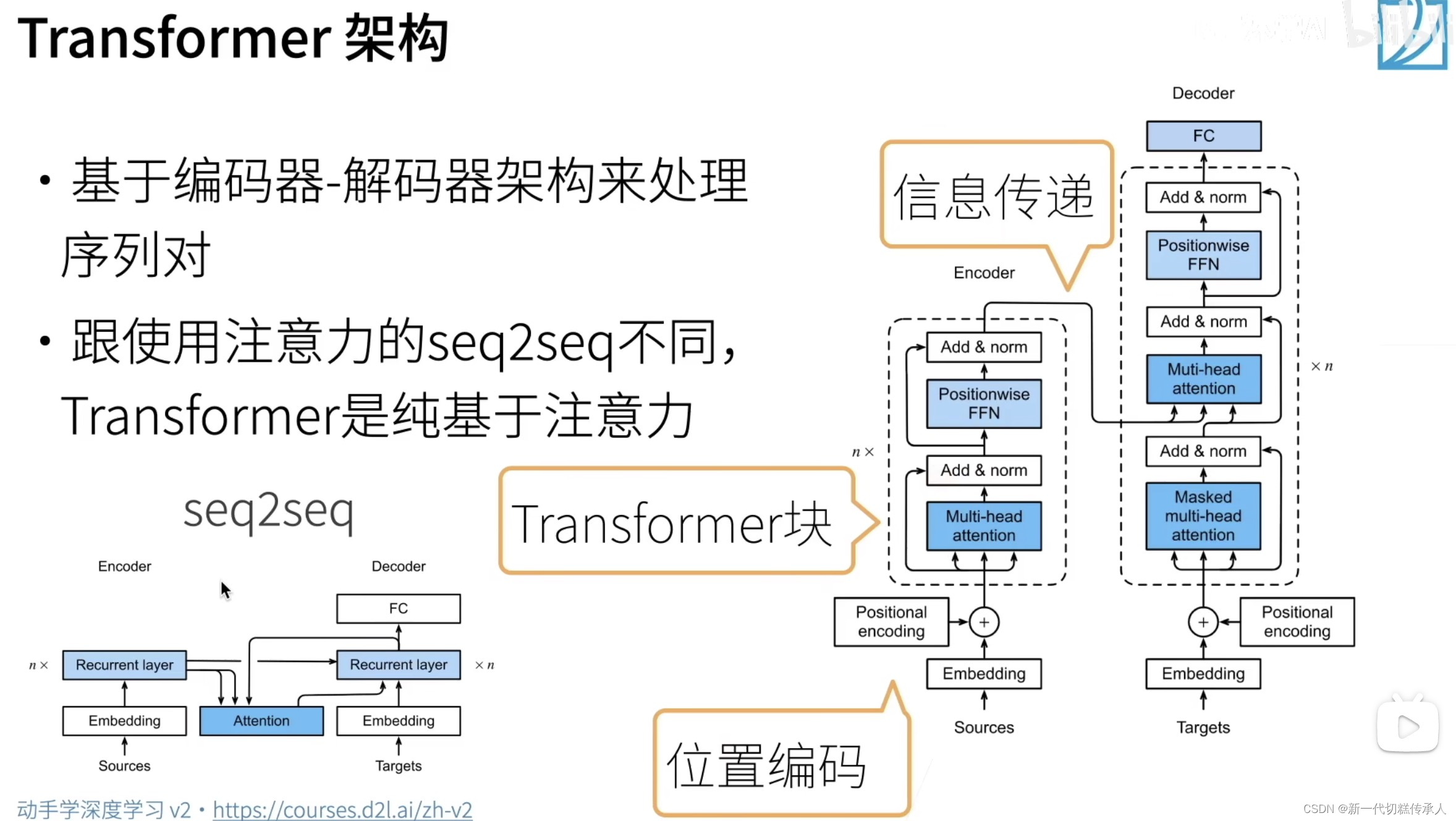
4. 李沐《动手学》:注意力机制 & Transformer框架 & 归一化 Normalization
学习链接🔗:https://zh.d2l.ai/chapter_attention-mechanisms/index.html
https://space.bilibili.com/1567748478/channel/seriesdetail?sid=358497
4.1 多头注意力 Multi-Head Attention
看图上的笔记!!!!!!!!!!
4.2 层归一化 Layer Normalization
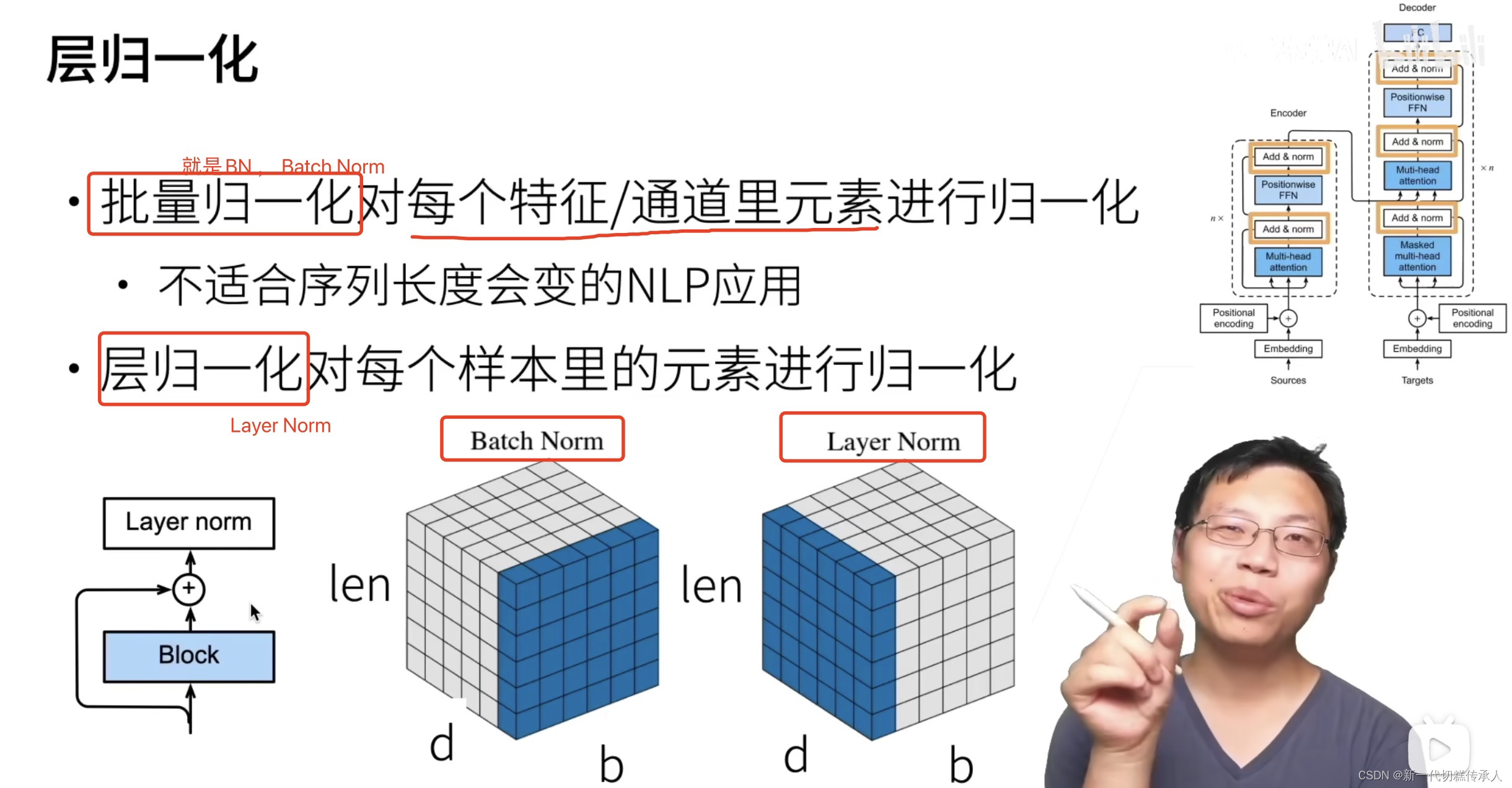
LN适用于 输入输出序列长度会变的data,所以NLP领域基本都用LN。
而BN常用于CV领域。
4.3 批量归一化 Batch Normalization (2015)
假设总共有30个样本,每5个样本构成一个batch来进行训练!
参考学习链接:(1)5分钟速食 https://www.bilibili.com/video/BV12d4y1f74C/?spm_id_from=333.337.search-card.all.click&vd_source=6b4de80fe82d569d8c1324a8320a624f
(2)台大 李宏毅 讲BN:https://www.bilibili.com/video/BV1bx411V798/?spm_id_from=333.337.search-card.all.click&vd_source=6b4de80fe82d569d8c1324a8320a624f # 真的很会讲 每次听都豁然开朗
BN可以保证网络中间的层,每一层的输入的分布都是类似的。
以下笔记来自 台大李宏毅老师 讲BN的视频:
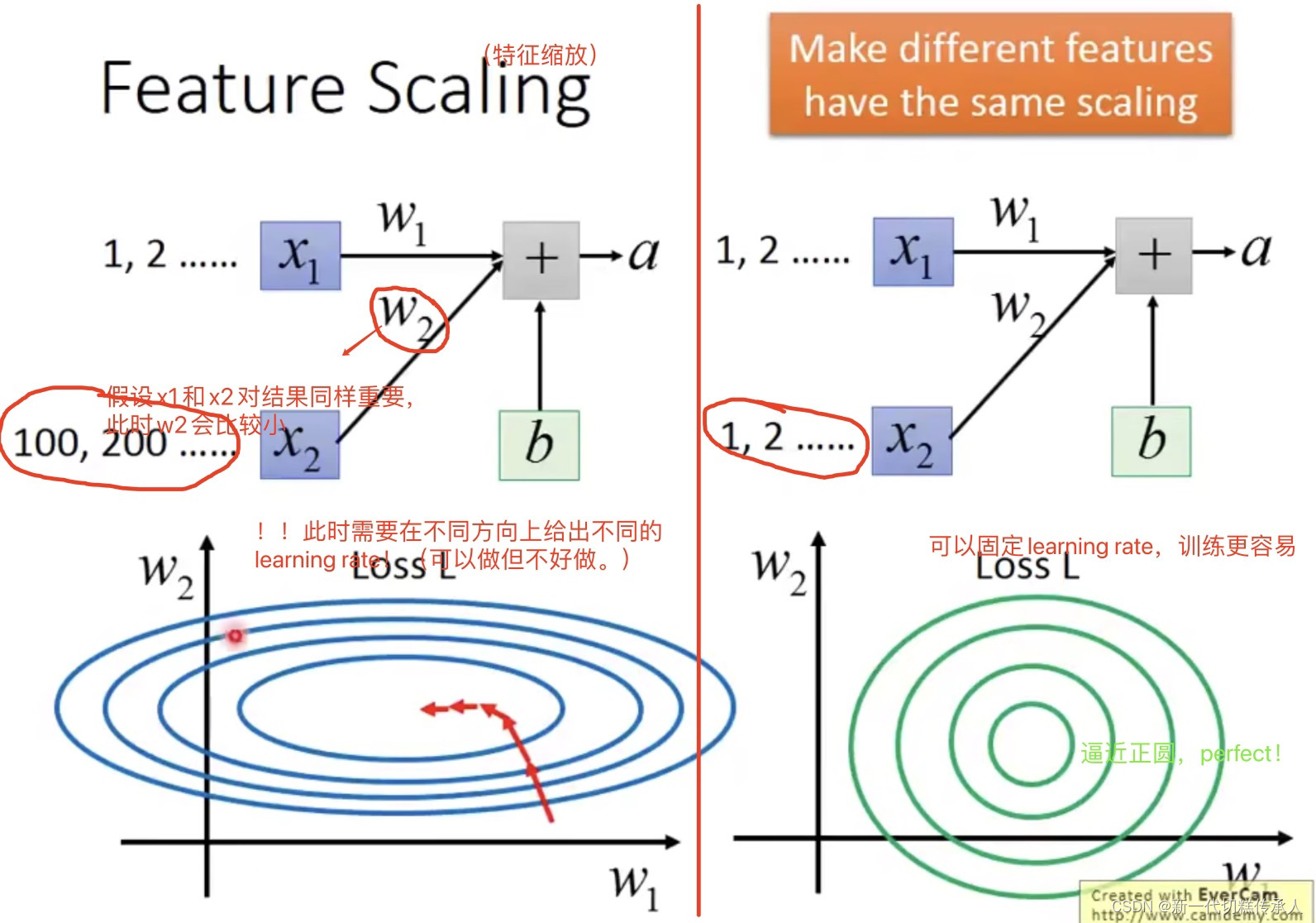
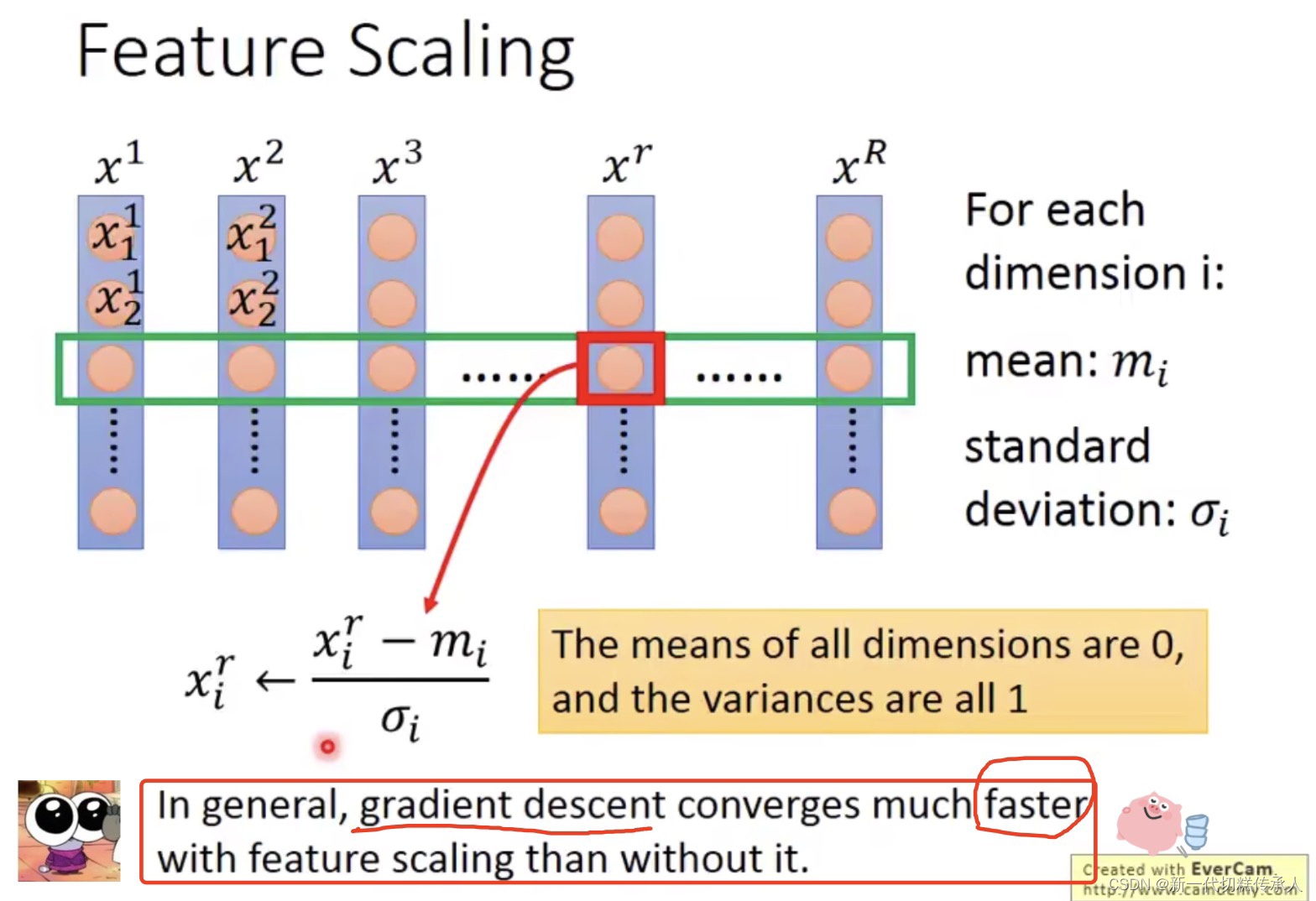
但是在网络中的hidden layers,都吃上一层输出的结果作为input,而这些数据是否也需要 Feature Scaling???
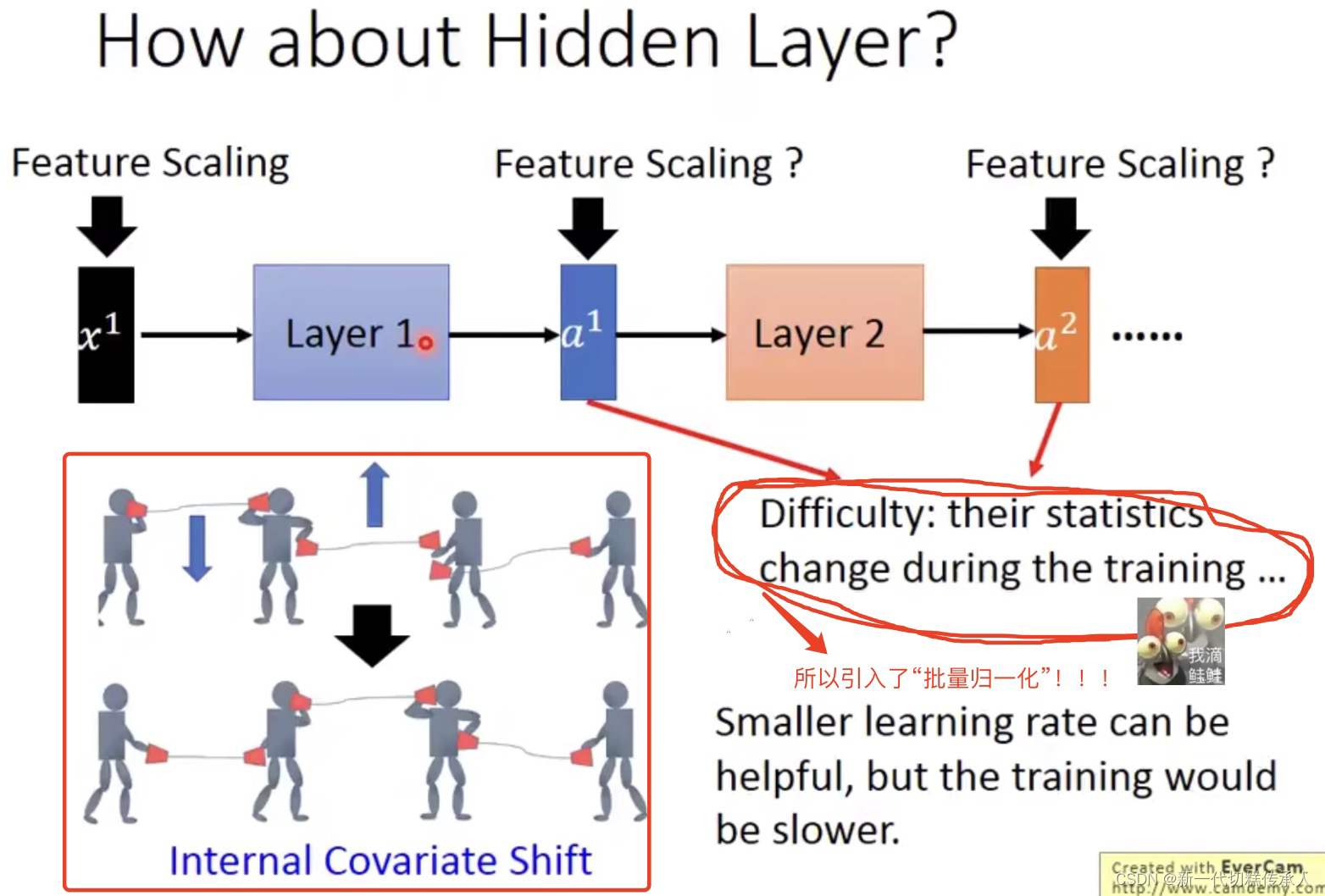
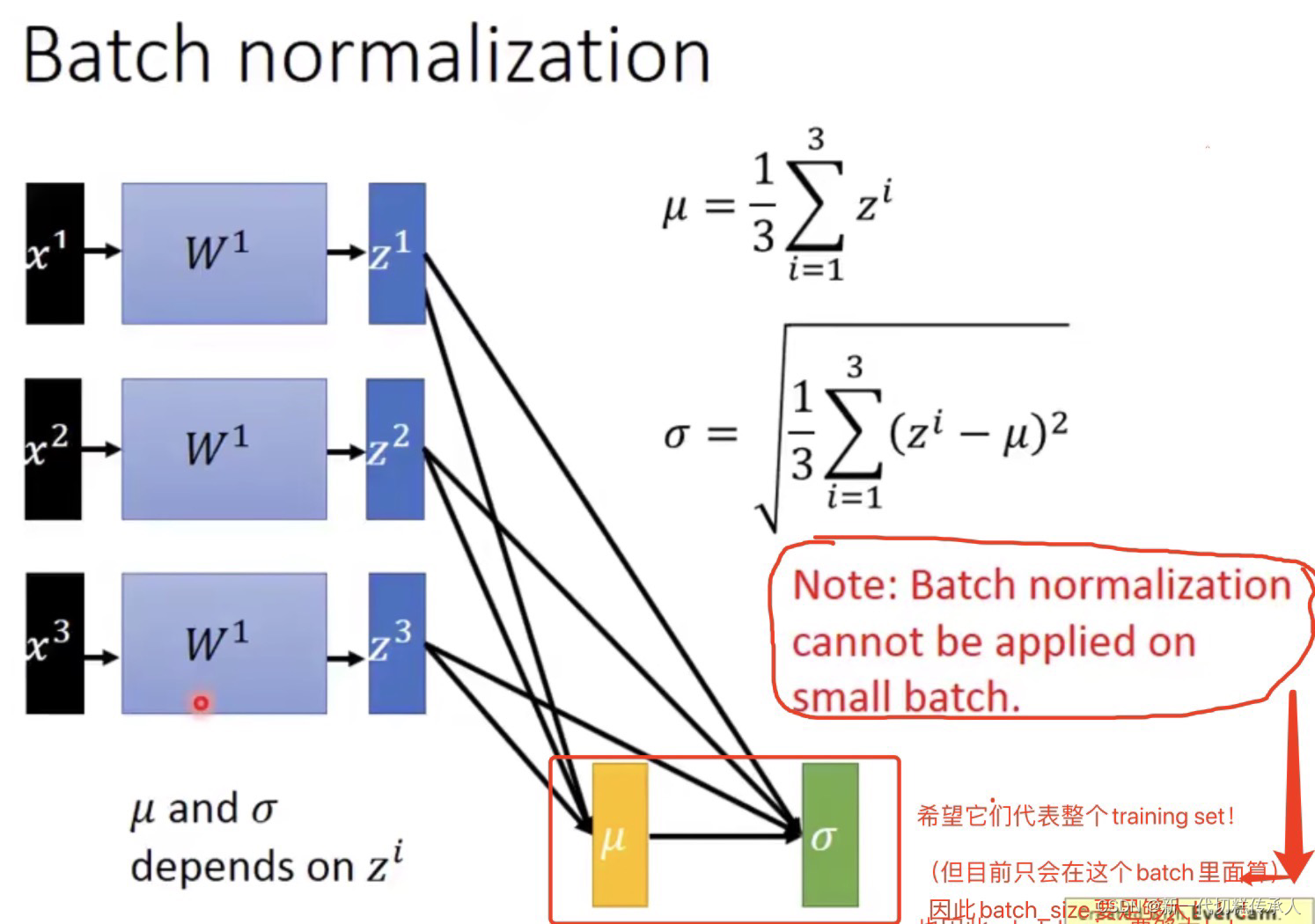
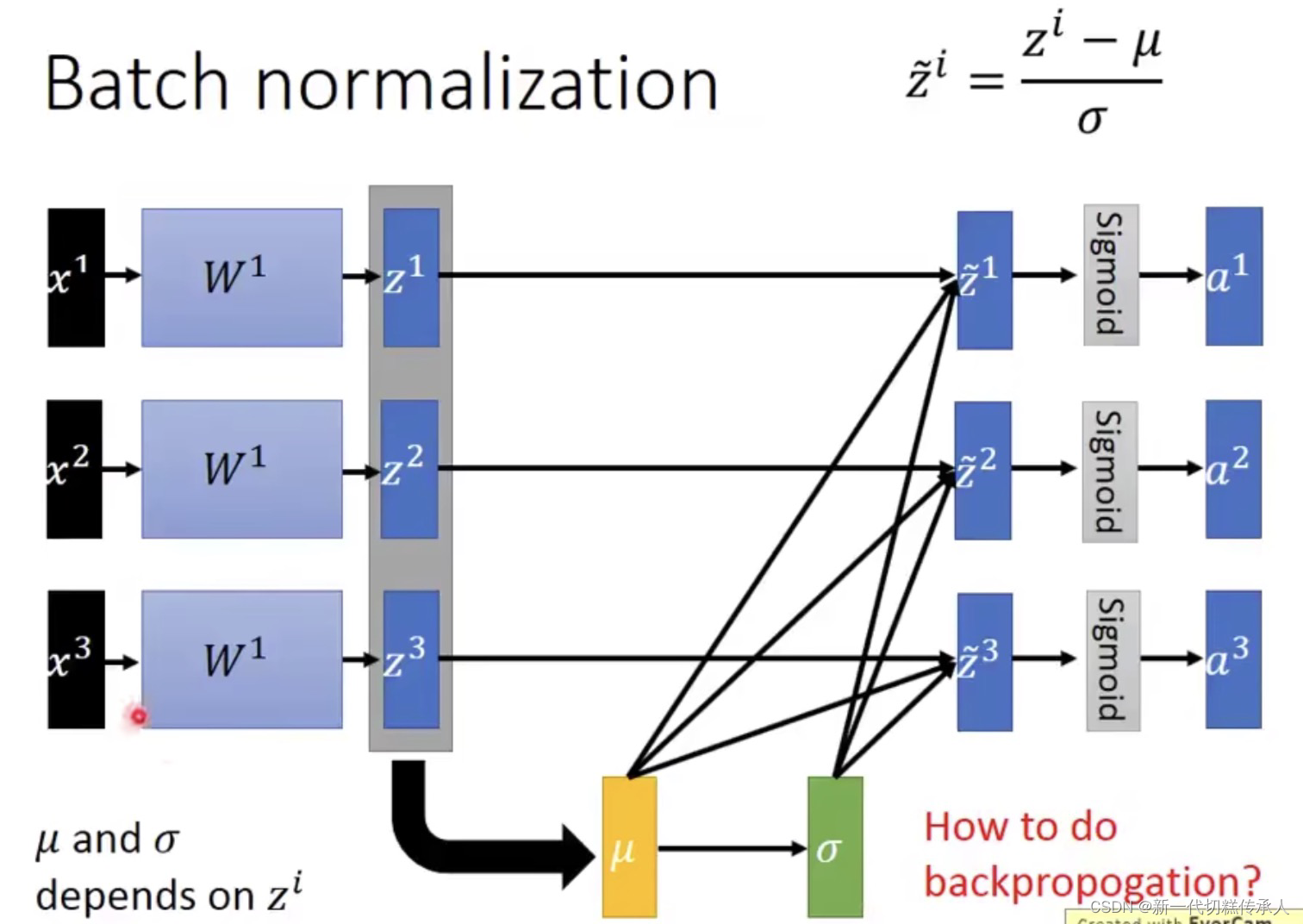
由上图可知:BN不可以在太小的batch上面被很好地应用,因为太小的batch计算得到的两个统计参数并不能很好地代表整个training set。因此,batch_size要足够大!!!
在 Testing stage / Inference时,如何使用 Batch Norm???
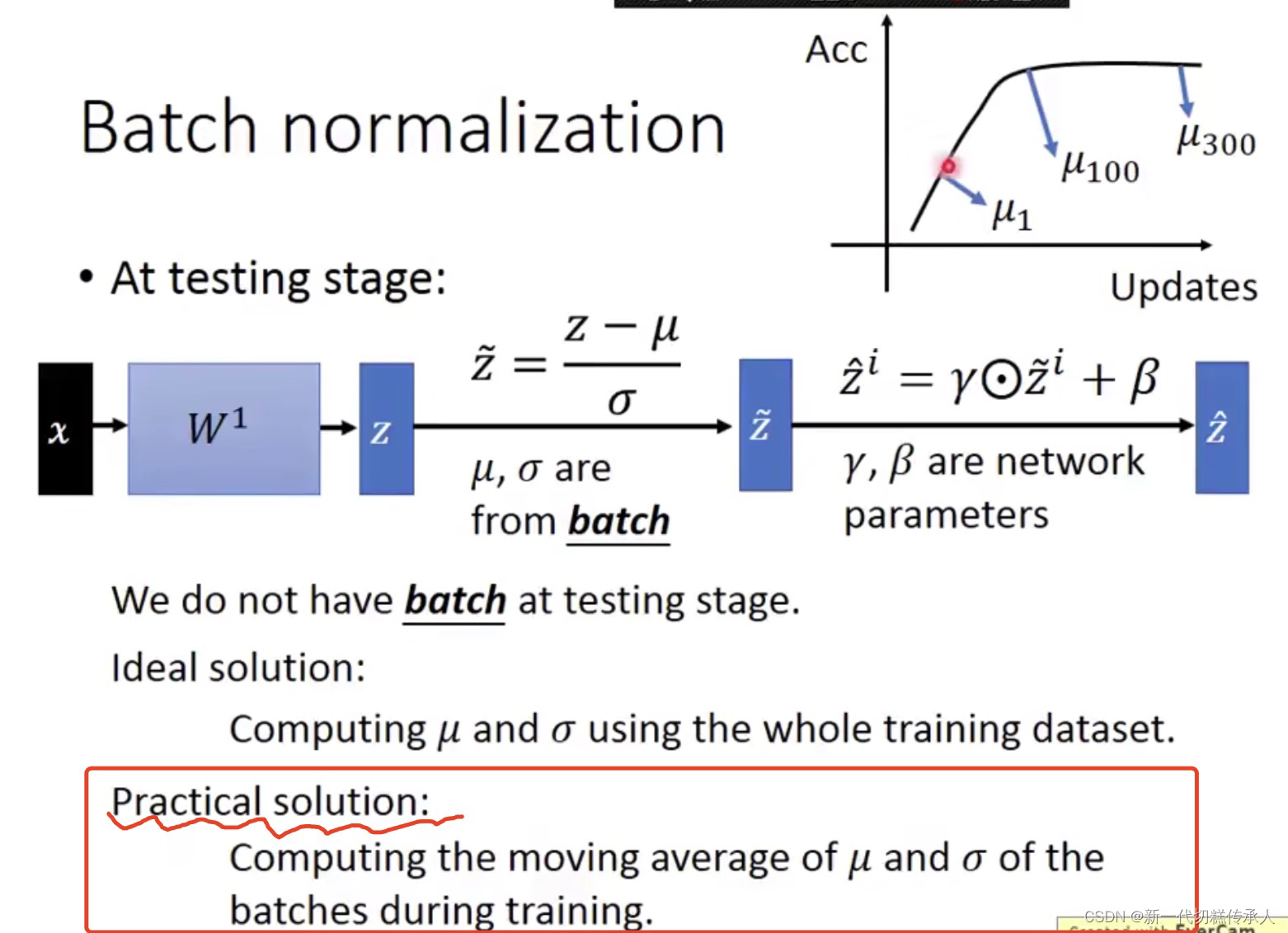
BN可以提速,但一般不改变模型的精度。
4.4 四种常见的「网络归一化」

4.5 信息传递(编码器 --> 解码器)
