网站做营销推广公司软文怎么写
文章目录
- 背景
- 排查步骤
- 官方issue排查
- 测试正常对话
- 测试官方默认知识库
- Debug排查
- vscode配置launch.json
- 命令行自动启动conda
- debug知识库搜索
- 测试更换ChineseRecursiveTextSplitter分词器
- 结论
- 关于markdownHeaderTextSplitter的探索
- 标准的markdown测试集
- Langchain区分head1和head2
- Langchain区分head1,head2,head3
- Langchain-Chatchat测试结果
- 分析Langchain-Chatchat的markdown文件加载
- 为什么Langchain-Chatchat会丢失标题
- 后记
背景
接上篇Langchain-Chatchat之pdf转markdown格式,pdf转markdown之后,使用官方的markdownHeaderTextSplitter分词器,创建完知识库之后进行问答,结果发现大模型无法正常返回,且日志报错如下:
File "/home/jfli/anaconda3/envs/py3.11/lib/python3.11/site-packages/langchain_community/chat_models/openai.py", line 493, in _astreamif len(chunk["choices"]) == 0:^^^^^^^^^^^^^^^^^^^^^
TypeError: Caught exception: object of type 'NoneType' has no len()
markdownHeaderTextSplitter这个分词器和markdown格式不是天生一对吗?为什么会出现这种报错?
排查步骤
官方issue排查
- https://github.com/chatchat-space/Langchain-Chatchat/issues/2062
- 重新install dashscope 无效
- 升级fschat 无效
- https://github.com/chatchat-space/Langchain-Chatchat/issues/3727
- 官方回答说这种类型的回答都代表大模型输出内容不对导致的。
- 所以就是要确认大模型是可用的,确认知识库的搜索结果是否符合预期。
测试正常对话
正常对话没问题,且大模型回复自己是千问,说明大模型也正常加载使用。
测试官方默认知识库
测试sample知识库的问题,结果是可以正常回复。说明大模型对于知识库的问答是生效的状态。
Debug排查
vscode配置launch.json
{// 使用 IntelliSense 了解相关属性。 // 悬停以查看现有属性的描述。// 欲了解更多信息,请访问: https://go.microsoft.com/fwlink/?linkid=830387"version": "0.2.0","configurations": [{"name": "Langchain-Chatchat","type": "debugpy","request": "launch","program": "${workspaceFolder}/startup.py","args": ["-a"],"console": "integratedTerminal","python": "/home/xxx/anaconda3/envs/py3.11/bin/python"}]
}
命令行自动启动conda
因为环境依赖都在conda下,如果不配置自动开启conda的话,服务会因为缺少依赖起不来。
配置launch.json的参数中没办法设置conda环境。有一种使用方法是先定义个task.json,在launch.json中定义preLaunchTask制定先运行task.json,在task.json中启动conda环境。
参考:利用launch.json和tasks.json 文件进行vscode 调试以及自动编译_tasks.json make编译-CSDN博客
经验证,没有成功。
第二种方法是直接修改zshrc文件,在文件下面新增:
conda activate py3.11
这样每次打开新的终端都会自动启动conda环境,缺点就是每次启动py3.11环境,如果需要切换环境的话需要自己手动切换。
debug知识库搜索
- 初始化模型
- 实例化模型的时候,api地址对应的端口是20000
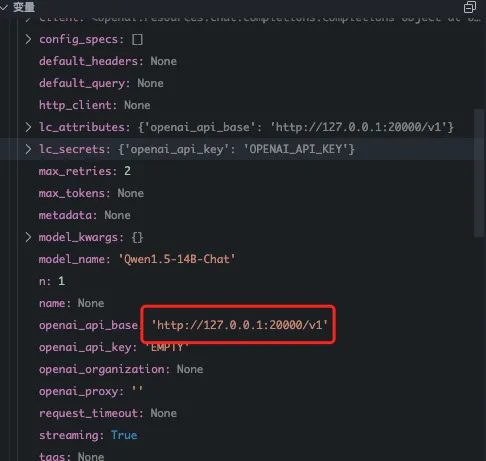
- 实例化模型的时候,api地址对应的端口是20000
- 查看知识库搜索结果
- 可以看到在向量库已经拿到数据了,根据向量返回的内容组装context,请求大模型出错。

- 查看启动配置,发现model_worker已经正常启动了
- 可以看到在向量库已经拿到数据了,根据向量返回的内容组装context,请求大模型出错。
2024-05-11 17:52:50 | INFO | model_worker | Register to controller
INFO: Started server process [3818873]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:7861 (Press CTRL+C to quit)
- 为什么请求大模型是走的20000这个端口呢?而不是配置中的21012端口?
- langchain-chatchat中默认的openai 端口是20000,这个配置会作为api_base传递给ChatOpenAI类,最后组装langchain的LLMChain,发起大模型请求。
- 目前发现请求大模型的地址
http://127.0.0.1:20000/v1/chat/completions# 这个地址是初始化openai的时候,使用fastchat提供的fastapi路由,
# 文件在fastchat.serve.openai_api_server# qianwen 大模型实际部署的端口是21012,对不上,是否会是这个问题呢?
- 参考fastchat的文档:https://github.com/lm-sys/FastChat/blob/main/docs/openai_api.md
- http://127.0.0.1:20000是fastchat启动的restful的api地址,同时也要启动模型工作线程 fastchat.serve.model_worker
- 测试fastchat中是否可以调用本地的qianwen-14B的模型
# 查看当前启动的模型
curl "http://127.0.0.1:20000/v1/models"# 返回了qianwen-14B
{"object":"list","data":[
{"id":"Qwen1.5-14B-Chat","object":"model","created":1715421368,
"owned_by":"fastchat","root":"Qwen1.5-14B-Chat","parent":null,
"permission":[{"id":"modelperm-4dMH93oGAz7eFLMoAdKegr","object":"model_permission","created":1715421368,"allow_create_engine":false,"allow_sampling":true,"allow_logprobs":true,"allow_search_indices":true,"allow_view":true,"allow_fine_tuning":false,"organization":"*","group":null,"is_blocking":false}
]}]}# 查看启动的模型
curl -X POST "http://127.0.0.1:20001/list_models"
{"models":["Qwen1.5-14B-Chat"]}# 和模型交流
curl http://localhost:20000/v1/chat/completions \-H "Content-Type: application/json" \-d '{"model": "Qwen1.5-14B-Chat","messages": [{"role": "user", "content": "Hello! What is your name?"}]}'# 模型回答{"id":"chatcmpl-3ySLAgNaGJUqXcbu39cAmf","object":"chat.completion","created":1715421533,"model":"Qwen1.5-14B-Chat","choices":[{"index":0,"message":{"role":"assistant","content":"Hello! My name is Assistant. I'm here to help you with any questions or tasks you need assistance with. How can I help you today?"},"finish_reason":"stop"}],"usage":{"prompt_tokens":25,"total_tokens":55,"completion_tokens":30}}
3. 结论是访问20000端口请求大模型没问题,fastchat可以找到启动的大模型实例。20000端口是fastchat的controller地址,实际的大模型由model_worker启动。
- 错误堆栈追踪
- 追踪堆栈发现是调用langchain的langchain_core/language_models/chat_models.py,调用了_agenerate_with_cache函数,但并没有命中cache,走了617行
- 命中langchain_community/chat_models/openai.py的_agenerate函数
- 最终报错是在langchain_community/chat_models/openai.py的_astream函数,代码如下:
async for chunk in await acompletion_with_retry(self, messages=message_dicts, run_manager=run_manager, **params):if not isinstance(chunk, dict):chunk = chunk.dict()if len(chunk["choices"]) == 0:continuechoice = chunk["choices"][0]# 错误代码
if len(chunk["choices"]) == 0:
- 拿到知识库返回的context,手动调用大模型查询试试?
- 知识库返回5w多个字符,不符合预期。
- 从返回内容上来看,充斥着大量的"##############" ,不符合我们的预期。使用MarkdownHeaderTextSplitter只是想保留标题,按照标题来分块,而不是污染原来的文档。
- 更改markdownHeaderTextSplitter的配置
- 默认的配置如下
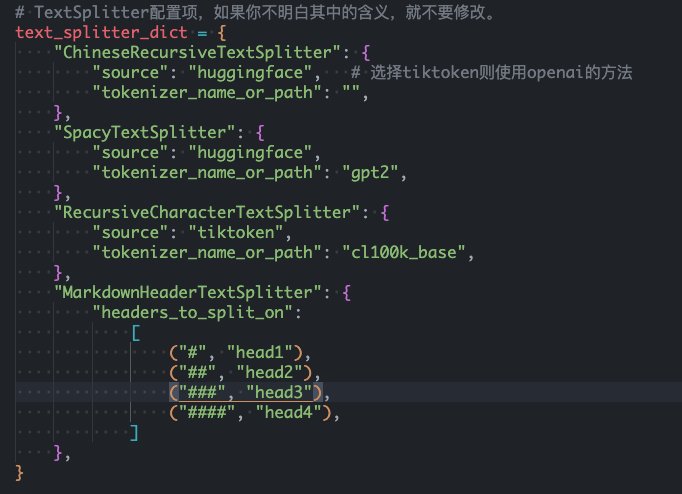
- 更改为只保留head1和head2看看
- 结果依然不行,文档含有大量的"##############",且分块只有2个。如果是textSplitter的话,分块有165个,比较正常。
- 猜测是markdownHeaderTextSplitter适合标准格式的markdown文件,我们这里把pdf转换成markdown并不标准,格式不统一。此时通过markdownHeaderTextSplitter分词识别到的head1和head2比较少,导致分块只有2个。
- langchain-chatchat中分词配置中的chunkSize和overlapSize对markdownHeaderTextSplitter不生效。如果markdown文件不标准的话,可能一个块有几w个字,会影响大模型的输出。
- 更改markdownHeaderTextSplitter的配置到head6
- 知识库分块明显多了,从2个块变成了35个块。
- 部分问答可以出来,部分问答依然返回错误。
- 默认的配置如下
测试更换ChineseRecursiveTextSplitter分词器
- 可以正常被搜索到,返回1216个字符
- 返回的内容依然是带有markdown格式的内容,保留了表格的关系
- 知识库查看数据可以正常分块,一共165个块。

结论
pdf转markdown之后生成的markdown格式不够标准,这种情况下使用markdownHeadertextSplitter进行分词的效果不符合预期。
且因为配置文件中的chunkSize和overlapSize对markdownHeaderTextSplitter不生效,导致分块结果很差,一个块几万个字。
大模型是拿到知识库查询的结果,作为"context"传过去的,几万个字传给大模型,直接导致大模型推理时间过久且没有返回结果。
关于markdownHeaderTextSplitter的探索
标准的markdown测试集
# 查特查特团队
荣获AGI Playground Hackathon黑客松“生产力工具的新想象”赛道季军。
## 报道简介
2023年10月16日, Founder Park在近日结束的AGI Playground Hackathon黑客松比赛中,查特查特团队展现出色的实力,荣获了“生产力工具的新想象”赛道季军。本次比赛由Founder Park主办,并由智谱、Dify、Zilliz、声网、AWS云服务等企业协办。
## 获奖队员简介
+ 小明,A大学+ 负责Agent旅游助手的开发、场地协调以及团队住宿和行程的安排+ 在保证团队完赛上做出了主要贡献。作为队长,栋宇坚持自信,创新,沉着的精神,不断提出改进方案并抓紧落实,遇到相关问题积极请教老师,提高了团队开发效率。
# 你好啊
## 世界你好
比赛吸引了120多支参赛团队,最终有36支队伍进入决赛,其中34支队伍成功完成了路演。
## 中国你好
比赛吸引了120多支参赛团队,最终有36支队伍进入决赛,其中34支队伍成功完成了路演。
# 中午吃什么
## 世纪难题
比赛吸引了120多支参赛团队,最终有36支队伍进入决赛,其中34支队伍成功完成了路演。
## 为什么选择吃什么这么难
比赛吸引了120多支参赛团队,最终有36支队伍进入决赛,其中34支队伍成功完成了路演。
## 现在的年轻人到底需要什么?
比赛吸引了120多支参赛团队,最终有36支队伍进入决赛,其中34支队伍成功完成了路演。
# 早睡早起
## 为什么晚睡
比赛吸引了120多支参赛团队,最终有36支队伍进入决赛,其中34支队伍成功完成了路演。
## 晚睡的危害是什么
比赛吸引了120多支参赛团队,最终有36支队伍进入决赛,其中34支队伍成功完成了路演。
Langchain区分head1和head2
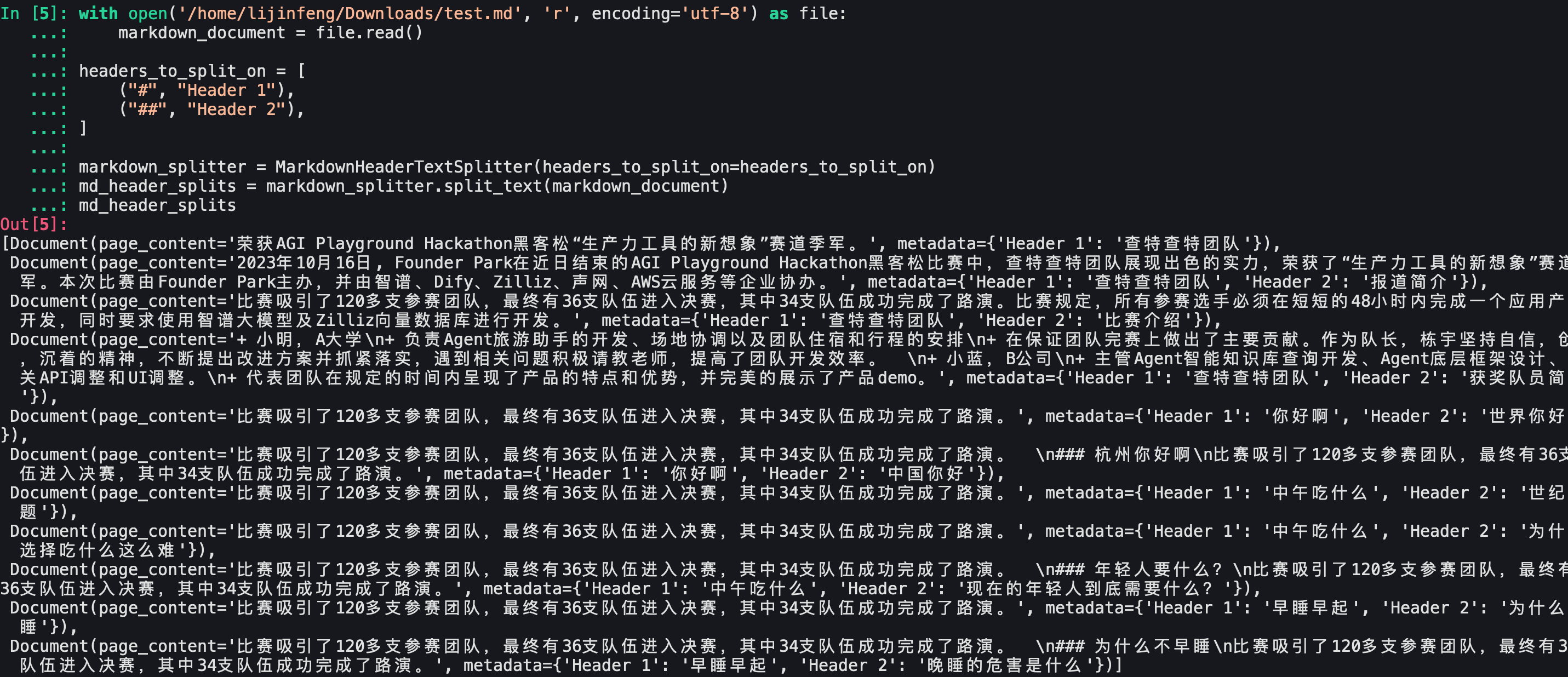
Langchain区分head1,head2,head3
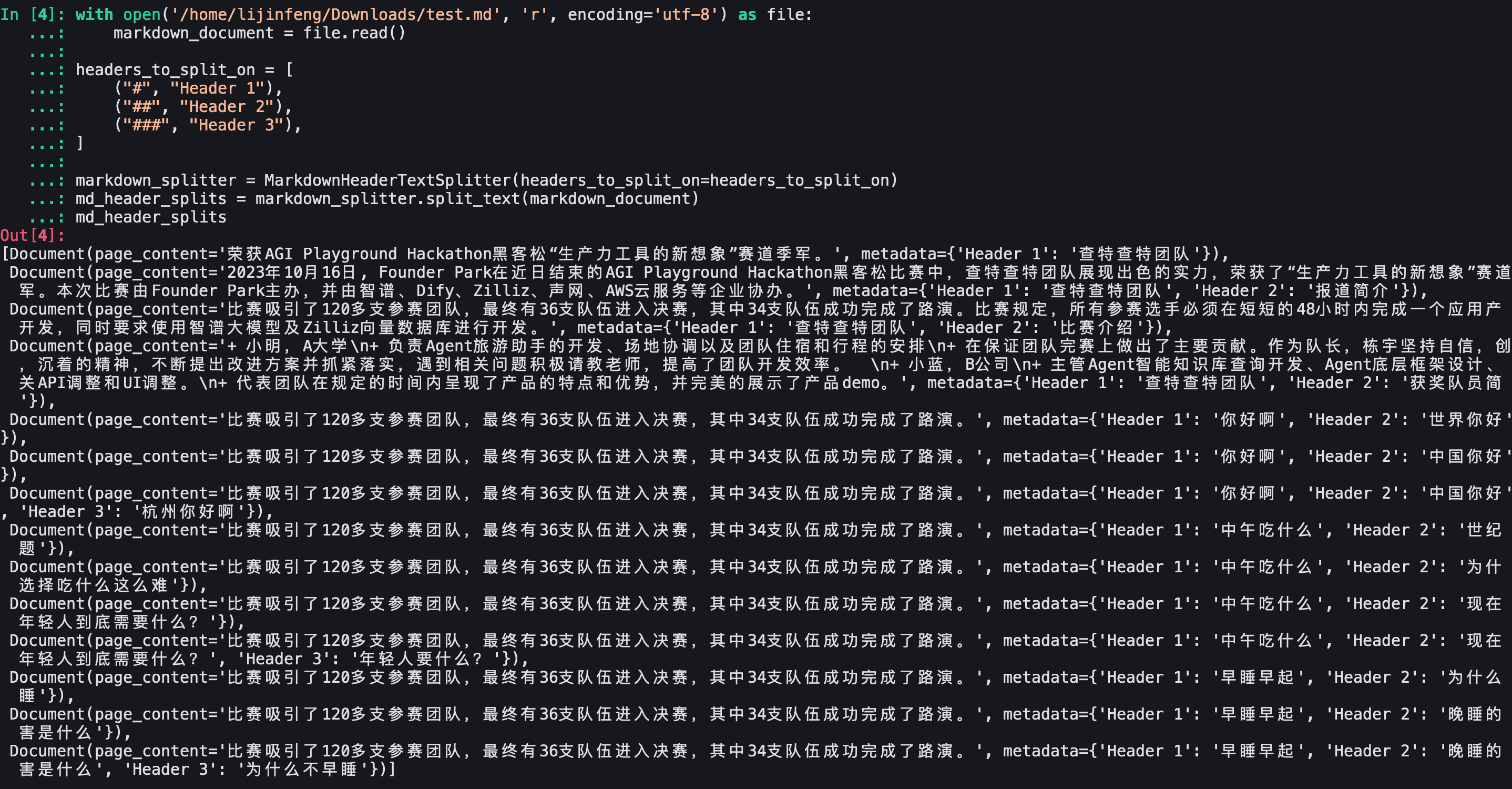
可以看到文档划分还是符合预期的。Langchain官方给出的测试demo没问题。
Langchain-Chatchat测试结果
更改markdown文件及分词器配置
- markdown文件包含一级,二级,三级标题
- 分词器只包含head1和head2
测试结果
- 依然只有一个文档
- 删除了md的分割标识符
- 保留了标题和内容的关系
- 没有保留标题的meta信息,不符合预期。
查特查特团队
荣获AGI Playground Hackathon黑客松“生产力工具的新想象”赛道季军。
报道简介
2023年10月16日, Founder Park在近日结束的AGI Playground Hackathon黑客松比赛中,查特查特团队展现出色的实力,荣获了“生产力工具的新想象”赛道季军。本次比赛由Founder Park主办,并由智谱、Dify、Zilliz、声网、AWS云服务等企业协办。
获奖队员简介
小明,A大学
负责Agent旅游助手的开发、场地协调以及团队住宿和行程的安排
在保证团队完赛上做出了主要贡献。作为队长,栋宇坚持自信,创新,沉着的精神,不断提出改进方案并抓紧落实,遇到相关问题积极请教老师,提高了团队开发效率。
你好啊
世界你好
比赛吸引了120多支参赛团队,最终有36支队伍进入决赛,其中34支队伍成功完成了路演。
中国你好
比赛吸引了120多支参赛团队,最终有36支队伍进入决赛,其中34支队伍成功完成了路演。
杭州你好啊
比赛吸引了120多支参赛团队,最终有36支队伍进入决赛,其中34支队伍成功完成了路演。
中午吃什么
世纪难题
比赛吸引了120多支参赛团队,最终有36支队伍进入决赛,其中34支队伍成功完成了路演。
为什么选择吃什么这么难
比赛吸引了120多支参赛团队,最终有36支队伍进入决赛,其中34支队伍成功完成了路演。
年轻人要什么?
比赛吸引了120多支参赛团队,最终有36支队伍进入决赛,其中34支队伍成功完成了路演。
早睡早起
为什么晚睡
比赛吸引了120多支参赛团队,最终有36支队伍进入决赛,其中34支队伍成功完成了路演。
为什么不早睡
比赛吸引了120多支参赛团队,最终有36支队伍进入决赛,其中34支队伍成功完成了路演。
分析Langchain-Chatchat的markdown文件加载
- 测试发现langchain-chatchat加载markdown文件使用的是langchain的markdown document loader
- 测试结果如下

- 也就是document loader的结果文件是没有markdown标识的,因此会导致进行markdownHeaderTextSplitter的时候,无法正确的按照标题来分割数据。
- document loader加上mode=“elements” 参数,发现可以区分标题了

- 测试markdownHeaderTextSplitter的效果
- 如果加上mode=“elements” 参数的话,markdown_splitter.split_text(markdown_document[0].page_content)的返回

- 如果不加 mode=“elements” 参数的话,结果是一整块
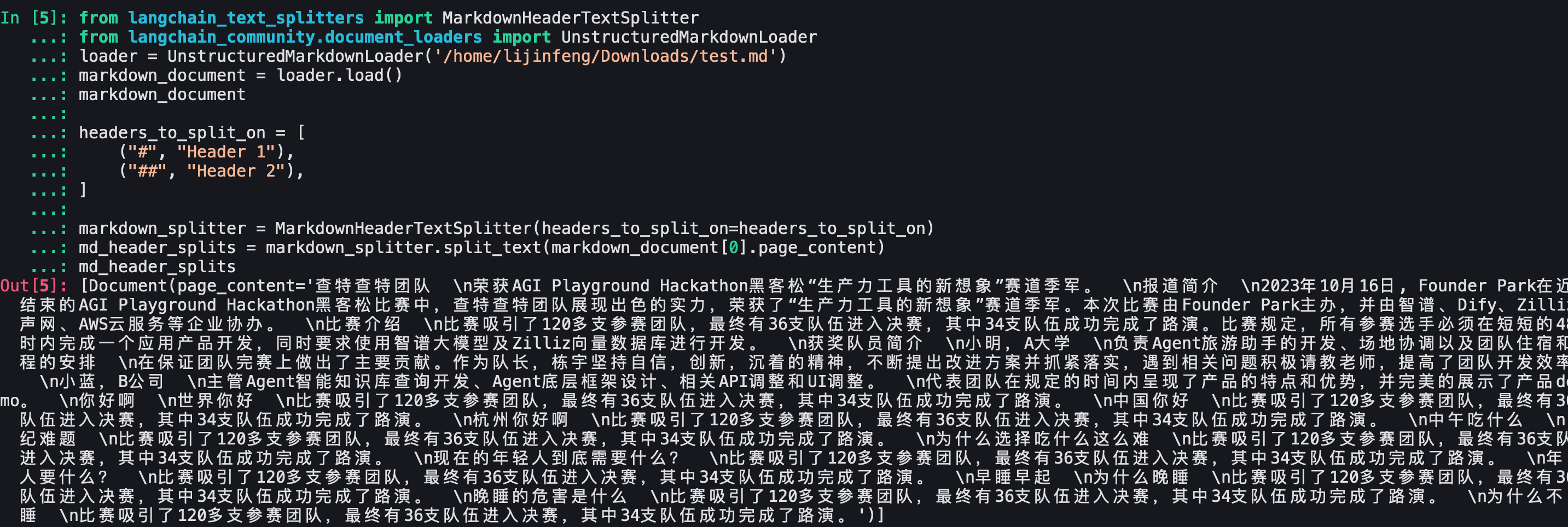
- 添加mode="elements"并且使用循环去进行split_text :

- 这个结果也不是符合预期的,只有文档内容page_content,没有meta信息,也没有标题信息。
- 如果加上mode=“elements” 参数的话,markdown_splitter.split_text(markdown_document[0].page_content)的返回
为什么Langchain-Chatchat会丢失标题
正如这篇文章所说: https://community.deeplearning.ai/t/loading-markdown-from-file-for-splitting/575875 langChain 中的 Markdown 加载器(UnstructedMarkdownLoader)删除了示例中分割文本所需的 Markdown 字符(例如:#、##、###)。所以按照标题分块是行不通的。
- 但是可以使用TextLoader来原样加载markdown文件,如下:

- 结合markdownHeaderTextSplitter
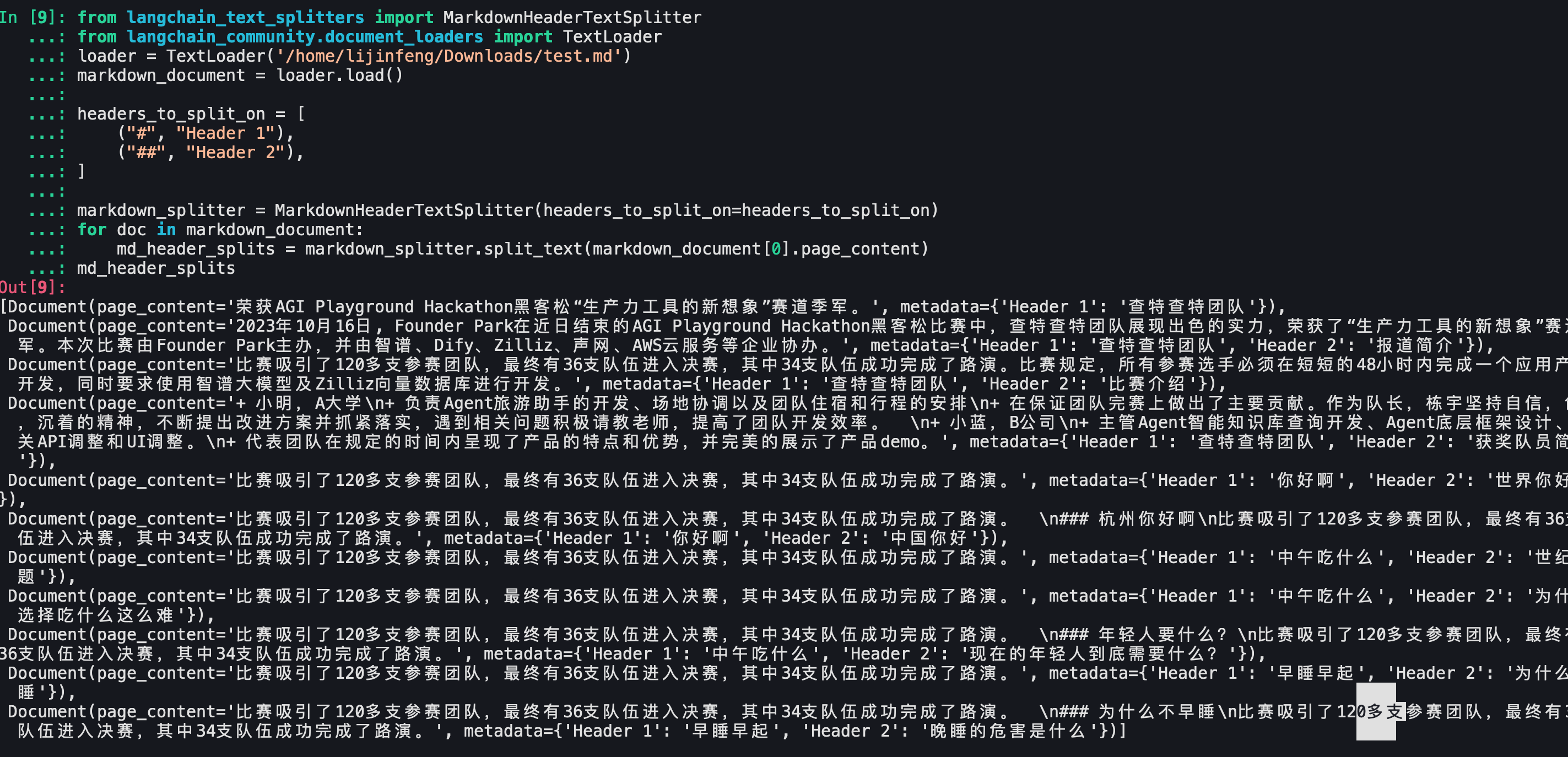
- 成功记录了标题信息,分块很成功!
后记
开源项目开箱即用是好事,但是直接拿来做产品还是欠佳的,怪不得大家最终都会走到自定义分词器的步骤,业务的需求千变万化,代码都掌握在自己手里才能以不变应万变啊。
就这样吧,还是挺有意思的。
end